 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-WAM: Latent World Action Modeling for End-to-End Autonomous Driving
Mar 25, 2026We introduce Latent-WAM, an efficient end-to-end autonomous driving framework that achieves strong trajectory planning through spatially-aware and dynamics-informed latent world representations. Existing world-model-based planners suffer from inadequately compressed representations, limited spatial understanding, and underutilized temporal dynamics, resulting in sub-optimal planning under constrained data and compute budgets. Latent-WAM addresses these limitations with two core modules: a Spatial-Aware Compressive World Encoder (SCWE) that distills geometric knowledge from a foundation model and compresses multi-view images into compact scene tokens via learnable queries, and a Dynamic Latent World Model (DLWM) that employs a causal Transformer to autoregressively predict future world status conditioned on historical visual and motion representations. Extensive experiments on NAVSIM v2 and HUGSIM demonstrate new state-of-the-art results: 89.3 EPDMS on NAVSIM v2 and 28.9 HD-Score on HUGSIM, surpassing the best prior perception-free method by 3.2 EPDMS with significantly less training data and a compact 104M-parameter model.
CMAMRNet: A Contextual Mask-Aware Network Enhancing Mural Restoration Through Comprehensive Mask Guidance
Aug 10, 2025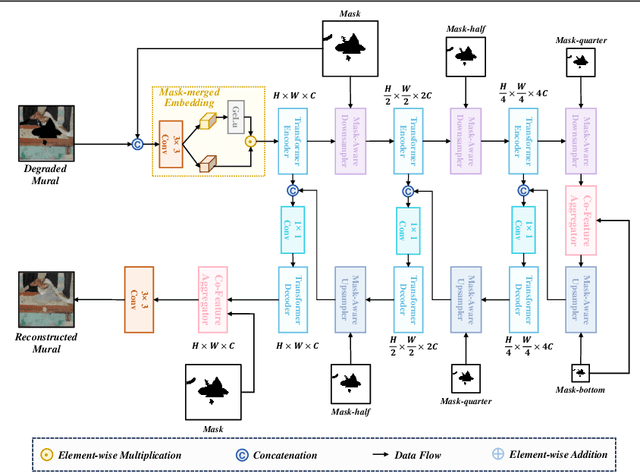
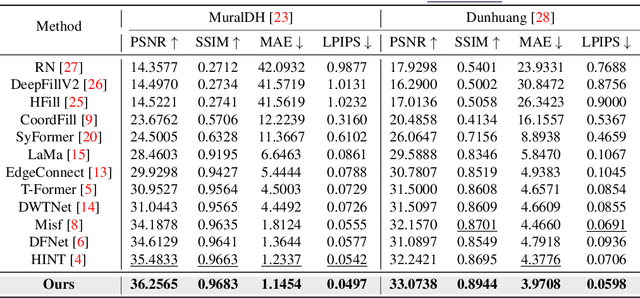
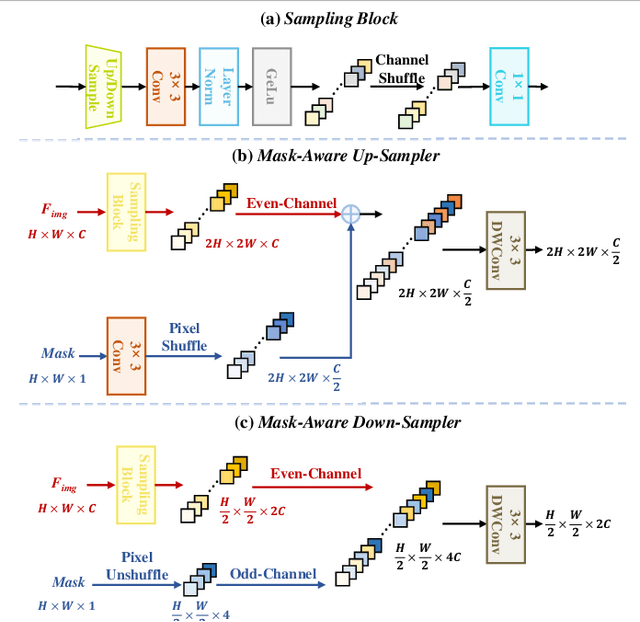
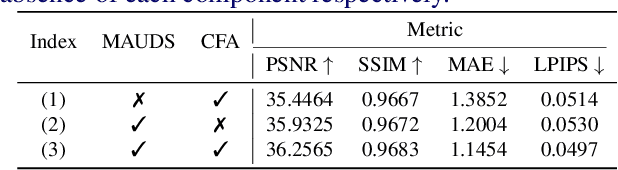
Murals, as invaluable cultural artifacts, face continuous deterioration from environmental factors and human activities. Digital restoration of murals faces unique challenges due to their complex degradation patterns and the critical need to preserve artistic authenticity. Existing learning-based methods struggle with maintaining consistent mask guidance throughout their networks, leading to insufficient focus on damaged regions and compromised restoration quality. We propose CMAMRNet, a Contextual Mask-Aware Mural Restoration Network that addresses these limitations through comprehensive mask guidance and multi-scale feature extraction. Our framework introduces two key components: (1) the Mask-Aware Up/Down-Sampler (MAUDS), which ensures consistent mask sensitivity across resolution scales through dedicated channel-wise feature selection and mask-guided feature fusion; and (2) the Co-Feature Aggregator (CFA), operating at both the highest and lowest resolutions to extract complementary features for capturing fine textures and global structures in degraded regions. Experimental results on benchmark datasets demonstrate that CMAMRNet outperforms state-of-the-art methods, effectively preserving both structural integrity and artistic details in restored murals. The code is available at~\href{https://github.com/CXH-Research/CMAMRNet}{https://github.com/CXH-Research/CMAMRNet}.
MAC-Lookup: Multi-Axis Conditional Lookup Model for Underwater Image Enhancement
Jul 03, 2025Enhancing underwater images is crucial for exploration. These images face visibility and color issues due to light changes, water turbidity, and bubbles. Traditional prior-based methods and pixel-based methods often fail, while deep learning lacks sufficient high-quality datasets. We introduce the Multi-Axis Conditional Lookup (MAC-Lookup) model, which enhances visual quality by improving color accuracy, sharpness, and contrast. It includes Conditional 3D Lookup Table Color Correction (CLTCC) for preliminary color and quality correction and Multi-Axis Adaptive Enhancement (MAAE) for detail refinement. This model prevents over-enhancement and saturation while handling underwater challenges. Extensive experiments show that MAC-Lookup excels in enhancing underwater images by restoring details and colors better than existing methods. The code is https://github.com/onlycatdoraemon/MAC-Lookup.
LensNet: An End-to-End Learning Framework for Empirical Point Spread Function Modeling and Lensless Imaging Reconstruction
May 03, 2025


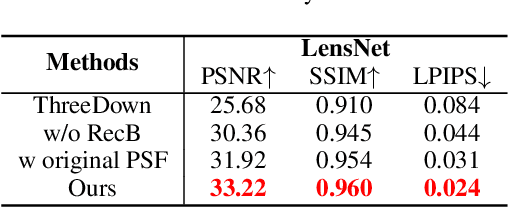
Lensless imaging stands out as a promising alternative to conventional lens-based systems, particularly in scenarios demanding ultracompact form factors and cost-effective architectures. However, such systems are fundamentally governed by the Point Spread Function (PSF), which dictates how a point source contributes to the final captured signal. Traditional lensless techniques often require explicit calibrations and extensive pre-processing, relying on static or approximate PSF models. These rigid strategies can result in limited adaptability to real-world challenges, including noise, system imperfections, and dynamic scene variations, thus impeding high-fidelity reconstruction. In this paper, we propose LensNet, an end-to-end deep learning framework that integrates spatial-domain and frequency-domain representations in a unified pipeline. Central to our approach is a learnable Coded Mask Simulator (CMS) that enables dynamic, data-driven estimation of the PSF during training, effectively mitigating the shortcomings of fixed or sparsely calibrated kernels. By embedding a Wiener filtering component, LensNet refines global structure and restores fine-scale details, thus alleviating the dependency on multiple handcrafted pre-processing steps. Extensive experiments demonstrate LensNet's robust performance and superior reconstruction quality compared to state-of-the-art methods, particularly in preserving high-frequency details and attenuating noise. The proposed framework establishes a novel convergence between physics-based modeling and data-driven learning, paving the way for more accurate, flexible, and practical lensless imaging solutions for applications ranging from miniature sensors to medical diagnostics. The link of code is https://github.com/baijiesong/Lensnet.
DLEN: Dual Branch of Transformer for Low-Light Image Enhancement in Dual Domains
Jan 21, 2025



Low-light image enhancement (LLE) aims to improve the visual quality of images captured in poorly lit conditions, which often suffer from low brightness, low contrast, noise, and color distortions. These issues hinder the performance of computer vision tasks such as object detection, facial recognition, and autonomous driving.Traditional enhancement techniques, such as multi-scale fusion and histogram equalization, fail to preserve fine details and often struggle with maintaining the natural appearance of enhanced images under complex lighting conditions. Although the Retinex theory provides a foundation for image decomposition, it often amplifies noise, leading to suboptimal image quality. In this paper, we propose the Dual Light Enhance Network (DLEN), a novel architecture that incorporates two distinct attention mechanisms, considering both spatial and frequency domains. Our model introduces a learnable wavelet transform module in the illumination estimation phase, preserving high- and low-frequency components to enhance edge and texture details. Additionally, we design a dual-branch structure that leverages the power of the Transformer architecture to enhance both the illumination and structural components of the image.Through extensive experiments, our model outperforms state-of-the-art methods on standard benchmarks.Code is available here: https://github.com/LaLaLoXX/DLEN
Underwater Image Restoration via Polymorphic Large Kernel CNNs
Dec 24, 2024



Underwater Image Restoration (UIR) remains a challenging task in computer vision due to the complex degradation of images in underwater environments. While recent approaches have leveraged various deep learning techniques, including Transformers and complex, parameter-heavy models to achieve significant improvements in restoration effects, we demonstrate that pure CNN architectures with lightweight parameters can achieve comparable results. In this paper, we introduce UIR-PolyKernel, a novel method for underwater image restoration that leverages Polymorphic Large Kernel CNNs. Our approach uniquely combines large kernel convolutions of diverse sizes and shapes to effectively capture long-range dependencies within underwater imagery. Additionally, we introduce a Hybrid Domain Attention module that integrates frequency and spatial domain attention mechanisms to enhance feature importance. By leveraging the frequency domain, we can capture hidden features that may not be perceptible to humans but are crucial for identifying patterns in both underwater and on-air images. This approach enhances the generalization and robustness of our UIR model. Extensive experiments on benchmark datasets demonstrate that UIR-PolyKernel achieves state-of-the-art performance in underwater image restoration tasks, both quantitatively and qualitatively. Our results show that well-designed pure CNN architectures can effectively compete with more complex models, offering a balance between performance and computational efficiency. This work provides new insights into the potential of CNN-based approaches for challenging image restoration tasks in underwater environments. The code is available at \href{https://github.com/CXH-Research/UIR-PolyKernel}{https://github.com/CXH-Research/UIR-PolyKernel}.
High-Fidelity Document Stain Removal via A Large-Scale Real-World Dataset and A Memory-Augmented Transformer
Oct 30, 2024
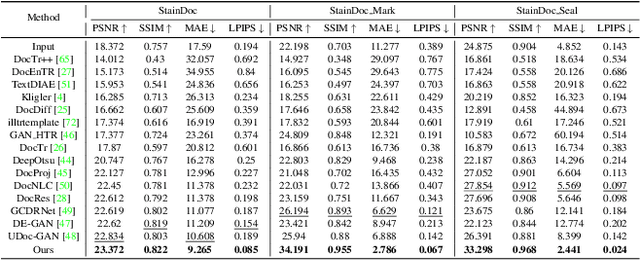


Document images are often degraded by various stains, significantly impacting their readability and hindering downstream applications such as document digitization and analysis. The absence of a comprehensive stained document dataset has limited the effectiveness of existing document enhancement methods in removing stains while preserving fine-grained details. To address this challenge, we construct StainDoc, the first large-scale, high-resolution ($2145\times2245$) dataset specifically designed for document stain removal. StainDoc comprises over 5,000 pairs of stained and clean document images across multiple scenes. This dataset encompasses a diverse range of stain types, severities, and document backgrounds, facilitating robust training and evaluation of document stain removal algorithms. Furthermore, we propose StainRestorer, a Transformer-based document stain removal approach. StainRestorer employs a memory-augmented Transformer architecture that captures hierarchical stain representations at part, instance, and semantic levels via the DocMemory module. The Stain Removal Transformer (SRTransformer) leverages these feature representations through a dual attention mechanism: an enhanced spatial attention with an expanded receptive field, and a channel attention captures channel-wise feature importance. This combination enables precise stain removal while preserving document content integrity. Extensive experiments demonstrate StainRestorer's superior performance over state-of-the-art methods on the StainDoc dataset and its variants StainDoc\_Mark and StainDoc\_Seal, establishing a new benchmark for document stain removal. Our work highlights the potential of memory-augmented Transformers for this task and contributes a valuable dataset to advance future research.
Lagrange Duality and Compound Multi-Attention Transformer for Semi-Supervised Medical Image Segmentation
Sep 12, 2024Medical image segmentation, a critical application of semantic segmentation in healthcare, has seen significant advancements through specialized computer vision techniques. While deep learning-based medical image segmentation is essential for assisting in medical diagnosis, the lack of diverse training data causes the long-tail problem. Moreover, most previous hybrid CNN-ViT architectures have limited ability to combine various attentions in different layers of the Convolutional Neural Network. To address these issues, we propose a Lagrange Duality Consistency (LDC) Loss, integrated with Boundary-Aware Contrastive Loss, as the overall training objective for semi-supervised learning to mitigate the long-tail problem. Additionally, we introduce CMAformer, a novel network that synergizes the strengths of ResUNet and Transformer. The cross-attention block in CMAformer effectively integrates spatial attention and channel attention for multi-scale feature fusion. Overall, our results indicate that CMAformer, combined with the feature fusion framework and the new consistency loss, demonstrates strong complementarity in semi-supervised learning ensembles. We achieve state-of-the-art results on multiple public medical image datasets. Example code are available at: \url{https://github.com/lzeeorno/Lagrange-Duality-and-CMAformer}.
UIE-UnFold: Deep Unfolding Network with Color Priors and Vision Transformer for Underwater Image Enhancement
Aug 20, 2024



Underwater image enhancement (UIE) plays a crucial role in various marine applications, but it remains challenging due to the complex underwater environment. Current learning-based approaches frequently lack explicit incorporation of prior knowledge about the physical processes involved in underwater image formation, resulting in limited optimization despite their impressive enhancement results. This paper proposes a novel deep unfolding network (DUN) for UIE that integrates color priors and inter-stage feature transformation to improve enhancement performance. The proposed DUN model combines the iterative optimization and reliability of model-based methods with the flexibility and representational power of deep learning, offering a more explainable and stable solution compared to existing learning-based UIE approaches. The proposed model consists of three key components: a Color Prior Guidance Block (CPGB) that establishes a mapping between color channels of degraded and original images, a Nonlinear Activation Gradient Descent Module (NAGDM) that simulates the underwater image degradation process, and an Inter Stage Feature Transformer (ISF-Former) that facilitates feature exchange between different network stages. By explicitly incorporating color priors and modeling the physical characteristics of underwater image formation, the proposed DUN model achieves more accurate and reliable enhancement results. Extensive experiments on multiple underwater image datasets demonstrate the superiority of the proposed model over state-of-the-art methods in both quantitative and qualitative evaluations. The proposed DUN-based approach offers a promising solution for UIE, enabling more accurate and reliable scientific analysis in marine research. The code is available at https://github.com/CXH-Research/UIE-UnFold.
Multi-modal Mood Reader: Pre-trained Model Empowers Cross-Subject Emotion Recognition
May 28, 2024Emotion recognition based on Electroencephalography (EEG) has gained significant attention and diversified development in fields such as neural signal processing and affective computing. However, the unique brain anatomy of individuals leads to non-negligible natural differences in EEG signals across subjects, posing challenges for cross-subject emotion recognition. While recent studies have attempted to address these issues, they still face limitations in practical effectiveness and model framework unity. Current methods often struggle to capture the complex spatial-temporal dynamics of EEG signals and fail to effectively integrate multimodal information, resulting in suboptimal performance and limited generalizability across subjects. To overcome these limitations, we develop a Pre-trained model based Multimodal Mood Reader for cross-subject emotion recognition that utilizes masked brain signal modeling and interlinked spatial-temporal attention mechanism. The model learns universal latent representations of EEG signals through pre-training on large scale dataset, and employs Interlinked spatial-temporal attention mechanism to process Differential Entropy(DE) features extracted from EEG data. Subsequently, a multi-level fusion layer is proposed to integrate the discriminative features, maximizing the advantages of features across different dimensions and modalities. Extensive experiments on public datasets demonstrate Mood Reader's superior performance in cross-subject emotion recognition tasks, outperforming state-of-the-art methods. Additionally, the model is dissected from attention perspective, providing qualitative analysis of emotion-related brain areas, offering valuable insights for affective research in neural signal processing.