 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantVLA: Scale-Calibrated Post-Training Quantization for Vision-Language-Action Models
Feb 25, 2026Vision-language-action (VLA) models unify perception, language, and control for embodied agents but face significant challenges in practical deployment due to rapidly increasing compute and memory demands, especially as models scale to longer horizons and larger backbones. To address these bottlenecks, we introduce QuantVLA, a training-free post-training quantization (PTQ) framework that, to our knowledge, is the first PTQ approach for VLA systems and the first to successfully quantize a diffusion transformer (DiT) action head. QuantVLA incorporates three scale-calibrated components: (1) a selective quantization layout that integerizes all linear layers in both the language backbone and the DiT while keeping attention projections in floating point to preserve the original operator schedule; (2) attention temperature matching, a lightweight per-head scaling mechanism that stabilizes attention logits and is folded into the dequantization scales at inference; and (3) output head balancing, a per-layer residual interface calibration that mitigates post-projection energy drift. The framework requires no additional training, uses only a small unlabeled calibration buffer, and supports integer kernels for low-bit weights and activations while leaving the architecture unchanged. Across representative VLA models on LIBERO, QuantVLA exceeds the task success rates of full-precision baselines, achieves about 70% relative memory savings on the quantized components, and delivers a 1.22x speedup in end-to-end inference latency, providing a practical pathway toward scalable low-bit embodied intelligence under strict compute, memory, and power constraints.
ProMist-5K: A Comprehensive Dataset for Digital Emulation of Cinematic Pro-Mist Filter Effects
Jan 27, 2026Pro-Mist filters are widely used in cinematography for their ability to create soft halation, lower contrast, and produce a distinctive, atmospheric style. These effects are difficult to reproduce digitally due to the complex behavior of light diffusion. We present ProMist-5K, a dataset designed to support cinematic style emulation. It is built using a physically inspired pipeline in a scene-referred linear space and includes 20,000 high-resolution image pairs across four configurations, covering two filter densities (1/2 and 1/8) and two focal lengths (20mm and 50mm). Unlike general style datasets, ProMist-5K focuses on realistic glow and highlight diffusion effects. Multiple blur layers and carefully tuned weighting are used to model the varying intensity and spread of optical diffusion. The dataset provides a consistent and controllable target domain that supports various image translation models and learning paradigms. Experiments show that the dataset works well across different training settings and helps capture both subtle and strong cinematic appearances. ProMist-5K offers a practical and physically grounded resource for film-inspired image transformation, bridging the gap between digital flexibility and traditional lens aesthetics. The dataset is available at https://www.kaggle.com/datasets/yingtielei/promist5k.
SFormer: SNR-guided Transformer for Underwater Image Enhancement from the Frequency Domain
Aug 26, 2025


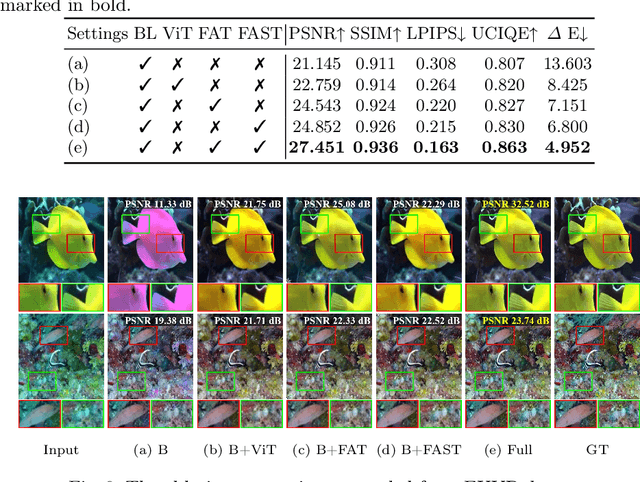
Recent learning-based underwater image enhancement (UIE) methods have advanced by incorporating physical priors into deep neural networks, particularly using the signal-to-noise ratio (SNR) prior to reduce wavelength-dependent attenuation. However, spatial domain SNR priors have two limitations: (i) they cannot effectively separate cross-channel interference, and (ii) they provide limited help in amplifying informative structures while suppressing noise. To overcome these, we propose using the SNR prior in the frequency domain, decomposing features into amplitude and phase spectra for better channel modulation. We introduce the Fourier Attention SNR-prior Transformer (FAST), combining spectral interactions with SNR cues to highlight key spectral components. Additionally, the Frequency Adaptive Transformer (FAT) bottleneck merges low- and high-frequency branches using a gated attention mechanism to enhance perceptual quality. Embedded in a unified U-shaped architecture, these modules integrate a conventional RGB stream with an SNR-guided branch, forming SFormer. Trained on 4,800 paired images from UIEB, EUVP, and LSUI, SFormer surpasses recent methods with a 3.1 dB gain in PSNR and 0.08 in SSIM, successfully restoring colors, textures, and contrast in underwater scenes.
CMAMRNet: A Contextual Mask-Aware Network Enhancing Mural Restoration Through Comprehensive Mask Guidance
Aug 10, 2025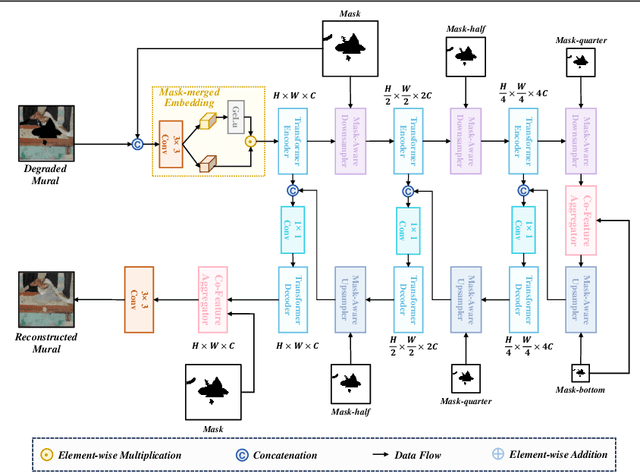
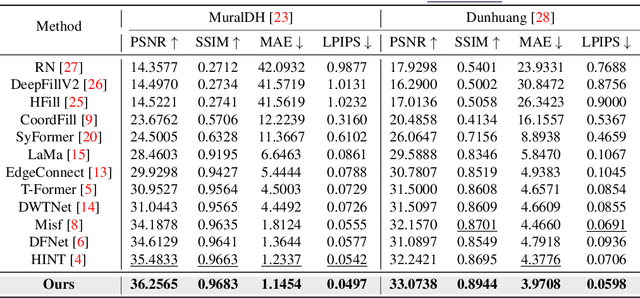
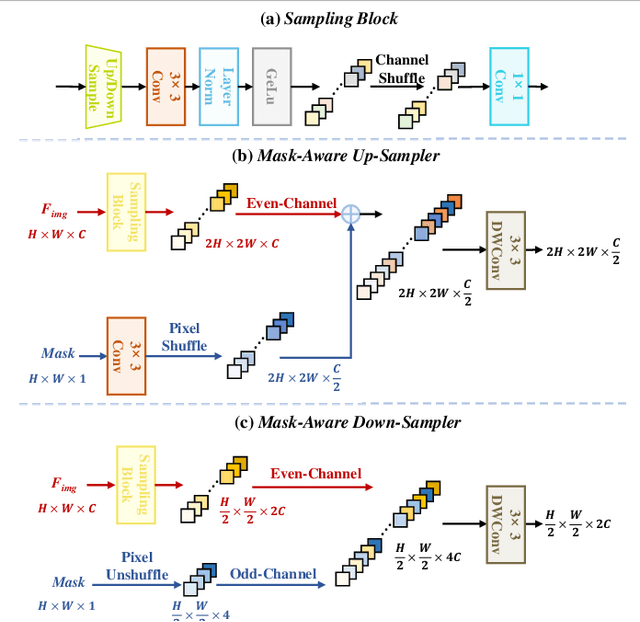
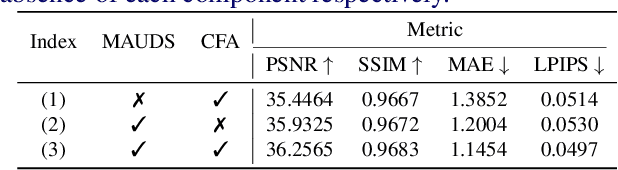
Murals, as invaluable cultural artifacts, face continuous deterioration from environmental factors and human activities. Digital restoration of murals faces unique challenges due to their complex degradation patterns and the critical need to preserve artistic authenticity. Existing learning-based methods struggle with maintaining consistent mask guidance throughout their networks, leading to insufficient focus on damaged regions and compromised restoration quality. We propose CMAMRNet, a Contextual Mask-Aware Mural Restoration Network that addresses these limitations through comprehensive mask guidance and multi-scale feature extraction. Our framework introduces two key components: (1) the Mask-Aware Up/Down-Sampler (MAUDS), which ensures consistent mask sensitivity across resolution scales through dedicated channel-wise feature selection and mask-guided feature fusion; and (2) the Co-Feature Aggregator (CFA), operating at both the highest and lowest resolutions to extract complementary features for capturing fine textures and global structures in degraded regions. Experimental results on benchmark datasets demonstrate that CMAMRNet outperforms state-of-the-art methods, effectively preserving both structural integrity and artistic details in restored murals. The code is available at~\href{https://github.com/CXH-Research/CMAMRNet}{https://github.com/CXH-Research/CMAMRNet}.
High-Fidelity Document Stain Removal via A Large-Scale Real-World Dataset and A Memory-Augmented Transformer
Oct 30, 2024
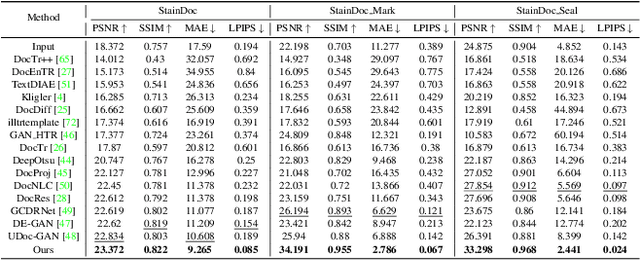


Document images are often degraded by various stains, significantly impacting their readability and hindering downstream applications such as document digitization and analysis. The absence of a comprehensive stained document dataset has limited the effectiveness of existing document enhancement methods in removing stains while preserving fine-grained details. To address this challenge, we construct StainDoc, the first large-scale, high-resolution ($2145\times2245$) dataset specifically designed for document stain removal. StainDoc comprises over 5,000 pairs of stained and clean document images across multiple scenes. This dataset encompasses a diverse range of stain types, severities, and document backgrounds, facilitating robust training and evaluation of document stain removal algorithms. Furthermore, we propose StainRestorer, a Transformer-based document stain removal approach. StainRestorer employs a memory-augmented Transformer architecture that captures hierarchical stain representations at part, instance, and semantic levels via the DocMemory module. The Stain Removal Transformer (SRTransformer) leverages these feature representations through a dual attention mechanism: an enhanced spatial attention with an expanded receptive field, and a channel attention captures channel-wise feature importance. This combination enables precise stain removal while preserving document content integrity. Extensive experiments demonstrate StainRestorer's superior performance over state-of-the-art methods on the StainDoc dataset and its variants StainDoc\_Mark and StainDoc\_Seal, establishing a new benchmark for document stain removal. Our work highlights the potential of memory-augmented Transformers for this task and contributes a valuable dataset to advance future research.
SMAFormer: Synergistic Multi-Attention Transformer for Medical Image Segmentation
Aug 31, 2024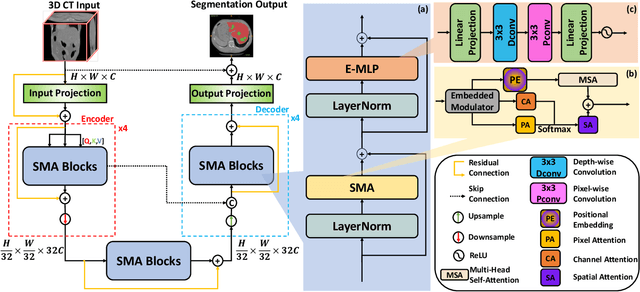
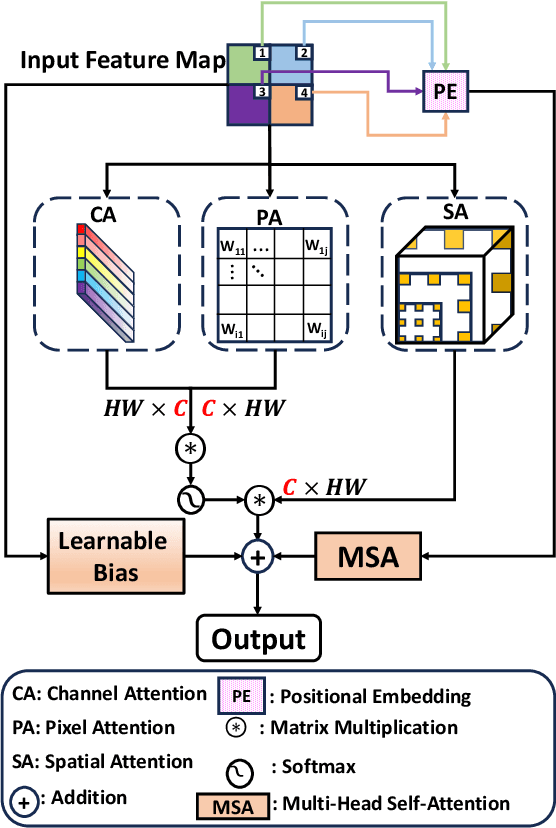
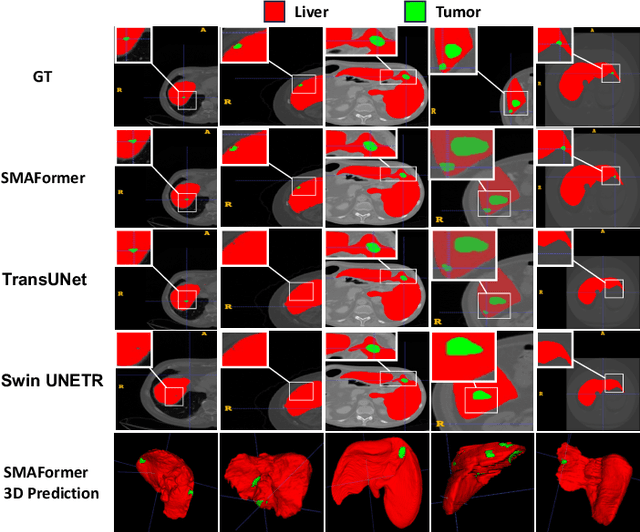
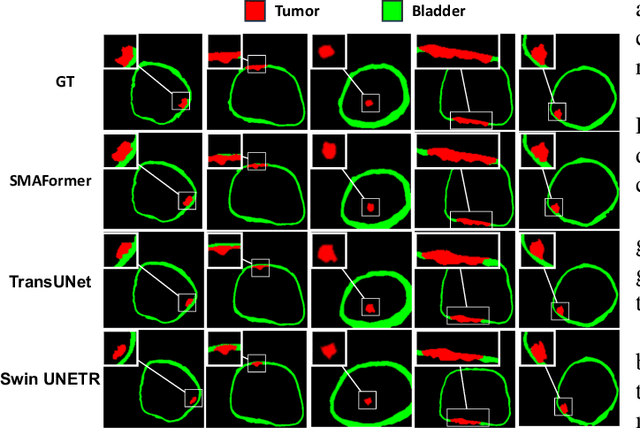
In medical image segmentation, specialized computer vision techniques, notably transformers grounded in attention mechanisms and residual networks employing skip connections, have been instrumental in advancing performance. Nonetheless, previous models often falter when segmenting small, irregularly shaped tumors. To this end, we introduce SMAFormer, an efficient, Transformer-based architecture that fuses multiple attention mechanisms for enhanced segmentation of small tumors and organs. SMAFormer can capture both local and global features for medical image segmentation. The architecture comprises two pivotal components. First, a Synergistic Multi-Attention (SMA) Transformer block is proposed, which has the benefits of Pixel Attention, Channel Attention, and Spatial Attention for feature enrichment. Second, addressing the challenge of information loss incurred during attention mechanism transitions and feature fusion, we design a Feature Fusion Modulator. This module bolsters the integration between the channel and spatial attention by mitigating reshaping-induced information attrition. To evaluate our method, we conduct extensive experiments on various medical image segmentation tasks, including multi-organ, liver tumor, and bladder tumor segmentation, achieving state-of-the-art results. Code and models are available at: \url{https://github.com/CXH-Research/SMAFormer}.
UIE-UnFold: Deep Unfolding Network with Color Priors and Vision Transformer for Underwater Image Enhancement
Aug 20, 2024



Underwater image enhancement (UIE) plays a crucial role in various marine applications, but it remains challenging due to the complex underwater environment. Current learning-based approaches frequently lack explicit incorporation of prior knowledge about the physical processes involved in underwater image formation, resulting in limited optimization despite their impressive enhancement results. This paper proposes a novel deep unfolding network (DUN) for UIE that integrates color priors and inter-stage feature transformation to improve enhancement performance. The proposed DUN model combines the iterative optimization and reliability of model-based methods with the flexibility and representational power of deep learning, offering a more explainable and stable solution compared to existing learning-based UIE approaches. The proposed model consists of three key components: a Color Prior Guidance Block (CPGB) that establishes a mapping between color channels of degraded and original images, a Nonlinear Activation Gradient Descent Module (NAGDM) that simulates the underwater image degradation process, and an Inter Stage Feature Transformer (ISF-Former) that facilitates feature exchange between different network stages. By explicitly incorporating color priors and modeling the physical characteristics of underwater image formation, the proposed DUN model achieves more accurate and reliable enhancement results. Extensive experiments on multiple underwater image datasets demonstrate the superiority of the proposed model over state-of-the-art methods in both quantitative and qualitative evaluations. The proposed DUN-based approach offers a promising solution for UIE, enabling more accurate and reliable scientific analysis in marine research. The code is available at https://github.com/CXH-Research/UIE-UnFold.
Implicit Multi-Spectral Transformer: An Lightweight and Effective Visible to Infrared Image Translation Model
Apr 10, 2024In the field of computer vision, visible light images often exhibit low contrast in low-light conditions, presenting a significant challenge. While infrared imagery provides a potential solution, its utilization entails high costs and practical limitations. Recent advancements in deep learning, particularly the deployment of Generative Adversarial Networks (GANs), have facilitated the transformation of visible light images to infrared images. However, these methods often experience unstable training phases and may produce suboptimal outputs. To address these issues, we propose a novel end-to-end Transformer-based model that efficiently converts visible light images into high-fidelity infrared images. Initially, the Texture Mapping Module and Color Perception Adapter collaborate to extract texture and color features from the visible light image. The Dynamic Fusion Aggregation Module subsequently integrates these features. Finally, the transformation into an infrared image is refined through the synergistic action of the Color Perception Adapter and the Enhanced Perception Attention mechanism. Comprehensive benchmarking experiments confirm that our model outperforms existing methods, producing infrared images of markedly superior quality, both qualitatively and quantitatively. Furthermore, the proposed model enables more effective downstream applications for infrared images than other methods.