 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Document Stain Removal via A Large-Scale Real-World Dataset and A Memory-Augmented Transformer
Oct 30, 2024
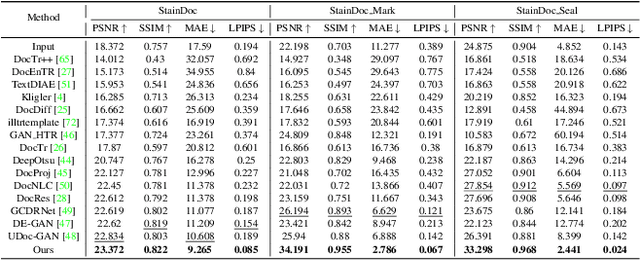


Document images are often degraded by various stains, significantly impacting their readability and hindering downstream applications such as document digitization and analysis. The absence of a comprehensive stained document dataset has limited the effectiveness of existing document enhancement methods in removing stains while preserving fine-grained details. To address this challenge, we construct StainDoc, the first large-scale, high-resolution ($2145\times2245$) dataset specifically designed for document stain removal. StainDoc comprises over 5,000 pairs of stained and clean document images across multiple scenes. This dataset encompasses a diverse range of stain types, severities, and document backgrounds, facilitating robust training and evaluation of document stain removal algorithms. Furthermore, we propose StainRestorer, a Transformer-based document stain removal approach. StainRestorer employs a memory-augmented Transformer architecture that captures hierarchical stain representations at part, instance, and semantic levels via the DocMemory module. The Stain Removal Transformer (SRTransformer) leverages these feature representations through a dual attention mechanism: an enhanced spatial attention with an expanded receptive field, and a channel attention captures channel-wise feature importance. This combination enables precise stain removal while preserving document content integrity. Extensive experiments demonstrate StainRestorer's superior performance over state-of-the-art methods on the StainDoc dataset and its variants StainDoc\_Mark and StainDoc\_Seal, establishing a new benchmark for document stain removal. Our work highlights the potential of memory-augmented Transformers for this task and contributes a valuable dataset to advance future research.
Implicit Multi-Spectral Transformer: An Lightweight and Effective Visible to Infrared Image Translation Model
Apr 10, 2024In the field of computer vision, visible light images often exhibit low contrast in low-light conditions, presenting a significant challenge. While infrared imagery provides a potential solution, its utilization entails high costs and practical limitations. Recent advancements in deep learning, particularly the deployment of Generative Adversarial Networks (GANs), have facilitated the transformation of visible light images to infrared images. However, these methods often experience unstable training phases and may produce suboptimal outputs. To address these issues, we propose a novel end-to-end Transformer-based model that efficiently converts visible light images into high-fidelity infrared images. Initially, the Texture Mapping Module and Color Perception Adapter collaborate to extract texture and color features from the visible light image. The Dynamic Fusion Aggregation Module subsequently integrates these features. Finally, the transformation into an infrared image is refined through the synergistic action of the Color Perception Adapter and the Enhanced Perception Attention mechanism. Comprehensive benchmarking experiments confirm that our model outperforms existing methods, producing infrared images of markedly superior quality, both qualitatively and quantitatively. Furthermore, the proposed model enables more effective downstream applications for infrared images than other methods.