 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Morph-Patch Transformer for Aortic Vessel Segmentation
Nov 11, 2025Accurate segmentation of aortic vascular structures is critical for diagnosing and treating cardiovascular diseases.Traditional Transformer-based models have shown promise in this domain by capturing long-range dependencies between vascular features. However, their reliance on fixed-size rectangular patches often influences the integrity of complex vascular structures, leading to suboptimal segmentation accuracy. To address this challenge, we propose the adaptive Morph Patch Transformer (MPT), a novel architecture specifically designed for aortic vascular segmentation. Specifically, MPT introduces an adaptive patch partitioning strategy that dynamically generates morphology-aware patches aligned with complex vascular structures. This strategy can preserve semantic integrity of complex vascular structures within individual patches. Moreover, a Semantic Clustering Attention (SCA) method is proposed to dynamically aggregate features from various patches with similar semantic characteristics. This method enhances the model's capability to segment vessels of varying sizes, preserving the integrity of vascular structures. Extensive experiments on three open-source dataset(AVT, AortaSeg24 and TBAD) demonstrate that MPT achieves state-of-the-art performance, with improvements in segmenting intricate vascular structures.
Lagrange Duality and Compound Multi-Attention Transformer for Semi-Supervised Medical Image Segmentation
Sep 12, 2024Medical image segmentation, a critical application of semantic segmentation in healthcare, has seen significant advancements through specialized computer vision techniques. While deep learning-based medical image segmentation is essential for assisting in medical diagnosis, the lack of diverse training data causes the long-tail problem. Moreover, most previous hybrid CNN-ViT architectures have limited ability to combine various attentions in different layers of the Convolutional Neural Network. To address these issues, we propose a Lagrange Duality Consistency (LDC) Loss, integrated with Boundary-Aware Contrastive Loss, as the overall training objective for semi-supervised learning to mitigate the long-tail problem. Additionally, we introduce CMAformer, a novel network that synergizes the strengths of ResUNet and Transformer. The cross-attention block in CMAformer effectively integrates spatial attention and channel attention for multi-scale feature fusion. Overall, our results indicate that CMAformer, combined with the feature fusion framework and the new consistency loss, demonstrates strong complementarity in semi-supervised learning ensembles. We achieve state-of-the-art results on multiple public medical image datasets. Example code are available at: \url{https://github.com/lzeeorno/Lagrange-Duality-and-CMAformer}.
ASSNet: Adaptive Semantic Segmentation Network for Microtumors and Multi-Organ Segmentation
Sep 12, 2024



Medical image segmentation, a crucial task in computer vision, facilitates the automated delineation of anatomical structures and pathologies, supporting clinicians in diagnosis, treatment planning, and disease monitoring. Notably, transformers employing shifted window-based self-attention have demonstrated exceptional performance. However, their reliance on local window attention limits the fusion of local and global contextual information, crucial for segmenting microtumors and miniature organs. To address this limitation, we propose the Adaptive Semantic Segmentation Network (ASSNet), a transformer architecture that effectively integrates local and global features for precise medical image segmentation. ASSNet comprises a transformer-based U-shaped encoder-decoder network. The encoder utilizes shifted window self-attention across five resolutions to extract multi-scale features, which are then propagated to the decoder through skip connections. We introduce an augmented multi-layer perceptron within the encoder to explicitly model long-range dependencies during feature extraction. Recognizing the constraints of conventional symmetrical encoder-decoder designs, we propose an Adaptive Feature Fusion (AFF) decoder to complement our encoder. This decoder incorporates three key components: the Long Range Dependencies (LRD) block, the Multi-Scale Feature Fusion (MFF) block, and the Adaptive Semantic Center (ASC) block. These components synergistically facilitate the effective fusion of multi-scale features extracted by the decoder while capturing long-range dependencies and refining object boundaries. Comprehensive experiments on diverse medical image segmentation tasks, including multi-organ, liver tumor, and bladder tumor segmentation, demonstrate that ASSNet achieves state-of-the-art results. Code and models are available at: \url{https://github.com/lzeeorno/ASSNet}.
SMAFormer: Synergistic Multi-Attention Transformer for Medical Image Segmentation
Aug 31, 2024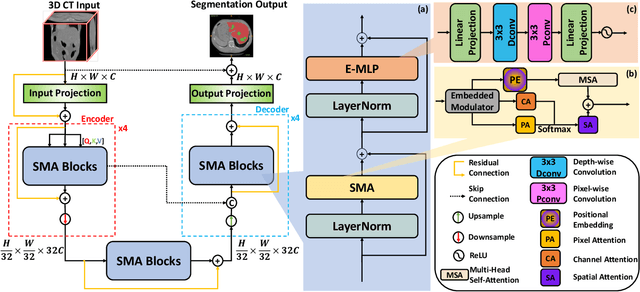
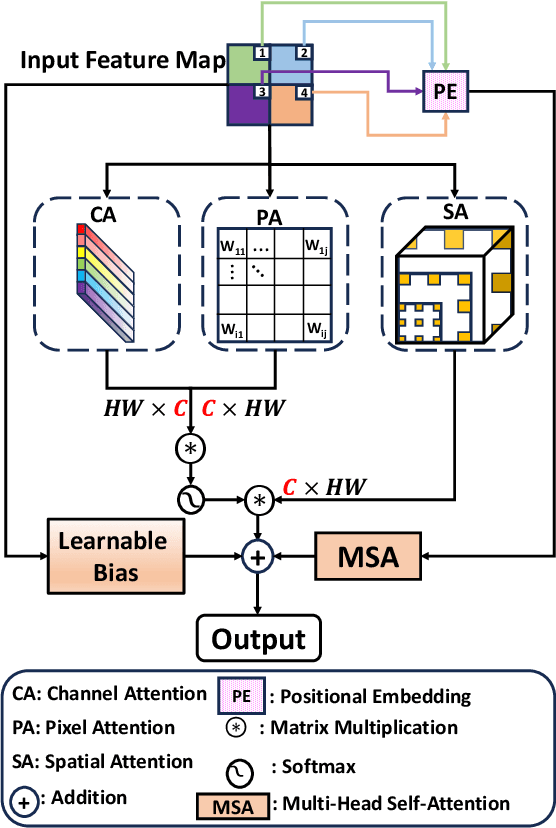
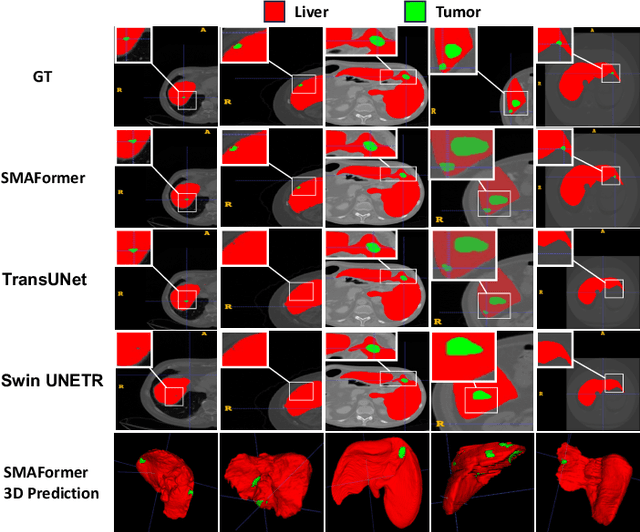
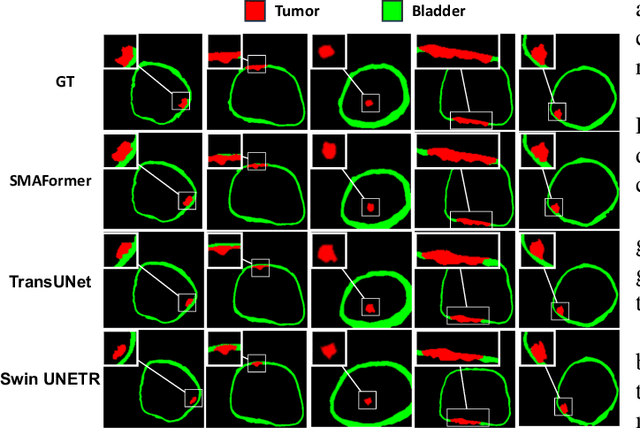
In medical image segmentation, specialized computer vision techniques, notably transformers grounded in attention mechanisms and residual networks employing skip connections, have been instrumental in advancing performance. Nonetheless, previous models often falter when segmenting small, irregularly shaped tumors. To this end, we introduce SMAFormer, an efficient, Transformer-based architecture that fuses multiple attention mechanisms for enhanced segmentation of small tumors and organs. SMAFormer can capture both local and global features for medical image segmentation. The architecture comprises two pivotal components. First, a Synergistic Multi-Attention (SMA) Transformer block is proposed, which has the benefits of Pixel Attention, Channel Attention, and Spatial Attention for feature enrichment. Second, addressing the challenge of information loss incurred during attention mechanism transitions and feature fusion, we design a Feature Fusion Modulator. This module bolsters the integration between the channel and spatial attention by mitigating reshaping-induced information attrition. To evaluate our method, we conduct extensive experiments on various medical image segmentation tasks, including multi-organ, liver tumor, and bladder tumor segmentation, achieving state-of-the-art results. Code and models are available at: \url{https://github.com/CXH-Research/SMAFormer}.