 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-rank Optimization Trajectories Modeling for LLM RLVR Acceleration
Apr 13, 2026Recently, scaling reinforcement learning with verifiable rewards (RLVR) for large language models (LLMs) has emerged as an effective training paradigm for significantly improving model capabilities, which requires guiding the model to perform extensive exploration and learning, leading to substantial computational overhead and becoming a key challenge. To reduce the number of training steps, Prior work performs linear extrapolation of model parameters. However, the dynamics of model parameter updates during RLVR training remain insufficiently understood. To further investigate the evolution of LLMs during RLVR training, we conduct empirical experiments and find that the rank-1 subspace of the model does not evolve linearly, and its dominance over the original parameters is further amplified during LoRA training. Based on the above insights, we propose the \textbf{N}onlinear \textbf{Ext}rapolation of low-rank trajectories (\textbf{NExt}), a novel framework that models and extrapolates low-rank parameter trajectories in a nonlinear manner. Concretely, we first train the model using LoRA and extract the rank-1 subspace of parameter differences at multiple training steps, which is then used for the subsequent nonlinear extrapolation. Afterward, we utilized the extracted rank-1 subspace to train a predictor, which can model the trajectory of parameter updates during RLVR, and then perform the predict-extend process to extrapolate model parameters, achieving the acceleration of RLVR. To further study and understand NExt, we conduct comprehensive experiments that demonstrate the effectiveness and robustness of the method. Our method reduces computational overhead by approximately 37.5\% while remaining compatible with a wide range of RLVR algorithms and tasks. We release our code in https://github.com/RUCAIBox/NExt.
Muskits-ESPnet: A Comprehensive Toolkit for Singing Voice Synthesis in New Paradigm
Sep 11, 2024

This research presents Muskits-ESPnet, a versatile toolkit that introduces new paradigms to Singing Voice Synthesis (SVS) through the application of pretrained audio models in both continuous and discrete approaches. Specifically, we explore discrete representations derived from SSL models and audio codecs and offer significant advantages in versatility and intelligence, supporting multi-format inputs and adaptable data processing workflows for various SVS models. The toolkit features automatic music score error detection and correction, as well as a perception auto-evaluation module to imitate human subjective evaluating scores. Muskits-ESPnet is available at \url{https://github.com/espnet/espnet}.
Multi-modal Mood Reader: Pre-trained Model Empowers Cross-Subject Emotion Recognition
May 28, 2024Emotion recognition based on Electroencephalography (EEG) has gained significant attention and diversified development in fields such as neural signal processing and affective computing. However, the unique brain anatomy of individuals leads to non-negligible natural differences in EEG signals across subjects, posing challenges for cross-subject emotion recognition. While recent studies have attempted to address these issues, they still face limitations in practical effectiveness and model framework unity. Current methods often struggle to capture the complex spatial-temporal dynamics of EEG signals and fail to effectively integrate multimodal information, resulting in suboptimal performance and limited generalizability across subjects. To overcome these limitations, we develop a Pre-trained model based Multimodal Mood Reader for cross-subject emotion recognition that utilizes masked brain signal modeling and interlinked spatial-temporal attention mechanism. The model learns universal latent representations of EEG signals through pre-training on large scale dataset, and employs Interlinked spatial-temporal attention mechanism to process Differential Entropy(DE) features extracted from EEG data. Subsequently, a multi-level fusion layer is proposed to integrate the discriminative features, maximizing the advantages of features across different dimensions and modalities. Extensive experiments on public datasets demonstrate Mood Reader's superior performance in cross-subject emotion recognition tasks, outperforming state-of-the-art methods. Additionally, the model is dissected from attention perspective, providing qualitative analysis of emotion-related brain areas, offering valuable insights for affective research in neural signal processing.
A Systematic Exploration of Joint-training for Singing Voice Synthesis
Aug 05, 2023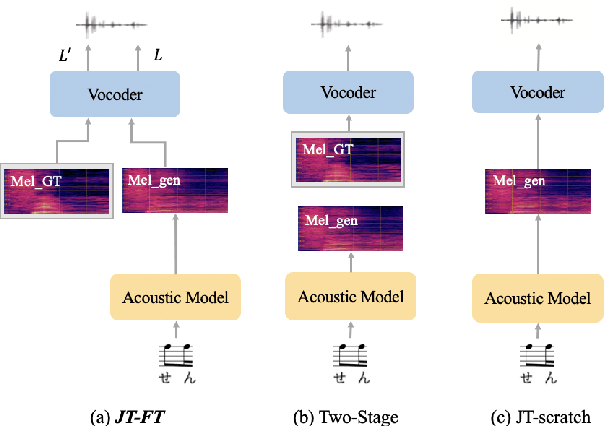

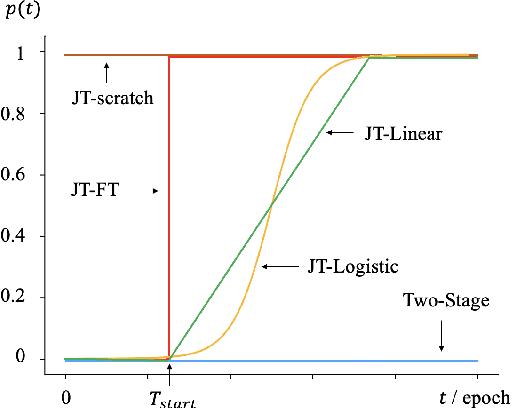

There has been a growing interest in using end-to-end acoustic models for singing voice synthesis (SVS). Typically, these models require an additional vocoder to transform the generated acoustic features into the final waveform. However, since the acoustic model and the vocoder are not jointly optimized, a gap can exist between the two models, leading to suboptimal performance. Although a similar problem has been addressed in the TTS systems by joint-training or by replacing acoustic features with a latent representation, adopting corresponding approaches to SVS is not an easy task. How to improve the joint-training of SVS systems has not been well explored. In this paper, we conduct a systematic investigation of how to better perform a joint-training of an acoustic model and a vocoder for SVS. We carry out extensive experiments and demonstrate that our joint-training strategy outperforms baselines, achieving more stable performance across different datasets while also increasing the interpretability of the entire framework.
PHONEix: Acoustic Feature Processing Strategy for Enhanced Singing Pronunciation with Phoneme Distribution Predictor
Mar 15, 2023



Singing voice synthesis (SVS), as a specific task for generating the vocal singing voice from a music score, has drawn much attention in recent years. SVS faces the challenge that the singing has various pronunciation flexibility conditioned on the same music score. Most of the previous works of SVS can not well handle the misalignment between the music score and actual singing. In this paper, we propose an acoustic feature processing strategy, named PHONEix, with a phoneme distribution predictor, to alleviate the gap between the music score and the singing voice, which can be easily adopted in different SVS systems. Extensive experiments in various settings demonstrate the effectiveness of our PHONEix in both objective and subjective evaluations.
Muskits: an End-to-End Music Processing Toolkit for Singing Voice Synthesis
May 09, 2022



This paper introduces a new open-source platform named Muskits for end-to-end music processing, which mainly focuses on end-to-end singing voice synthesis (E2E-SVS). Muskits supports state-of-the-art SVS models, including RNN SVS, transformer SVS, and XiaoiceSing. The design of Muskits follows the style of widely-used speech processing toolkits, ESPnet and Kaldi, for data prepossessing, training, and recipe pipelines. To the best of our knowledge, this toolkit is the first platform that allows a fair and highly-reproducible comparison between several published works in SVS. In addition, we also demonstrate several advanced usages based on the toolkit functionalities, including multilingual training and transfer learning. This paper describes the major framework of Muskits, its functionalities, and experimental results in single-singer, multi-singer, multilingual, and transfer learning scenarios. The toolkit is publicly available at https://github.com/SJTMusicTeam/Muskits.
SingAug: Data Augmentation for Singing Voice Synthesis with Cycle-consistent Training Strategy
Mar 31, 2022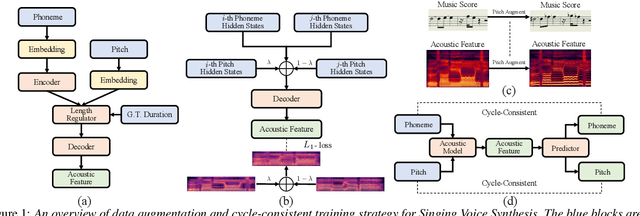
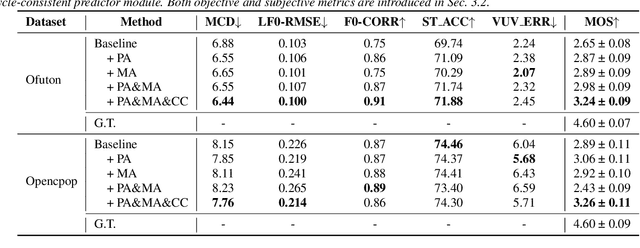
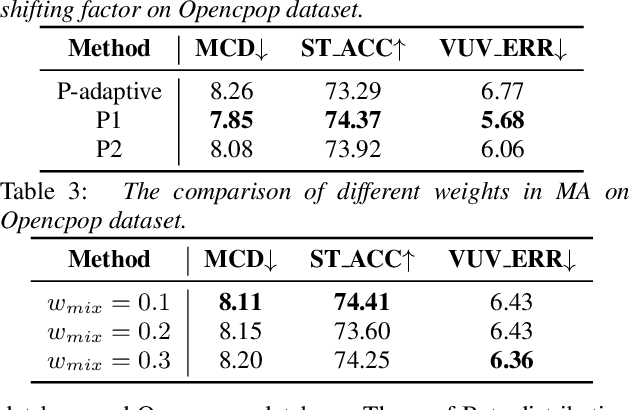
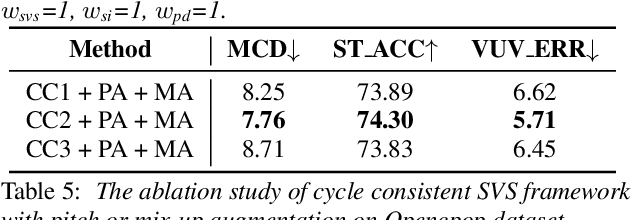
Deep learning based singing voice synthesis (SVS) systems have been demonstrated to flexibly generate singing with better qualities, compared to conventional statistical parametric based methods. However, neural systems are generally data-hungry and have difficulty to reach reasonable singing quality with limited public available training data. In this work, we explore different data augmentation methods to boost the training of SVS systems, including several strategies customized to SVS based on pitch augmentation and mix-up augmentation. To further stabilize the training, we introduce the cycle-consistent training strategy. Extensive experiments on two public singing databases demonstrate that our proposed augmentation methods and the stabilizing training strategy can significantly improve the performance on both objective and subjective evaluations.
A Granular Sieving Algorithm for Deterministic Global Optimization
Jul 14, 2021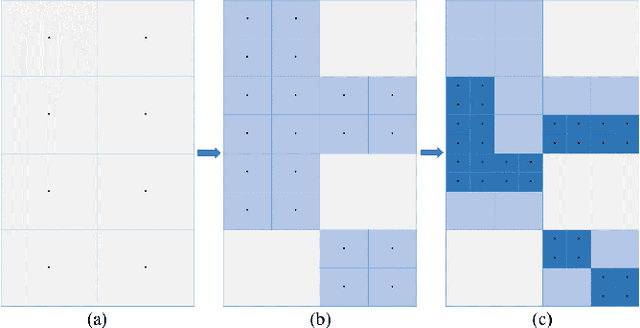

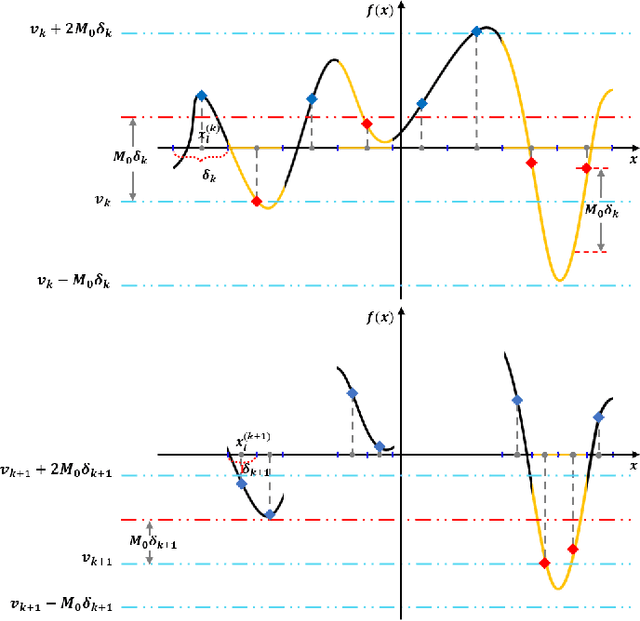
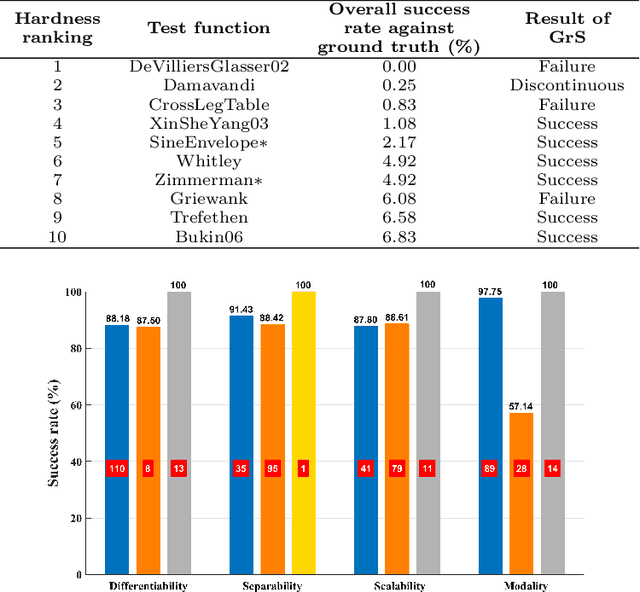
A gradient-free deterministic method is developed to solve global optimization problems for Lipschitz continuous functions defined in arbitrary path-wise connected compact sets in Euclidean spaces. The method can be regarded as granular sieving with synchronous analysis in both the domain and range of the objective function. With straightforward mathematical formulation applicable to both univariate and multivariate objective functions, the global minimum value and all the global minimizers are located through two decreasing sequences of compact sets in, respectively, the domain and range spaces. The algorithm is easy to implement with moderate computational cost. The method is tested against extensive benchmark functions in the literature. The experimental results show remarkable effectiveness and applicability of the algorithm.
A Bi-LSTM-RNN Model for Relation Classification Using Low-Cost Sequence Features
Aug 27, 2016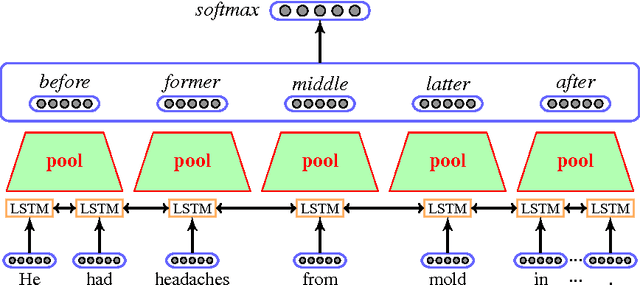
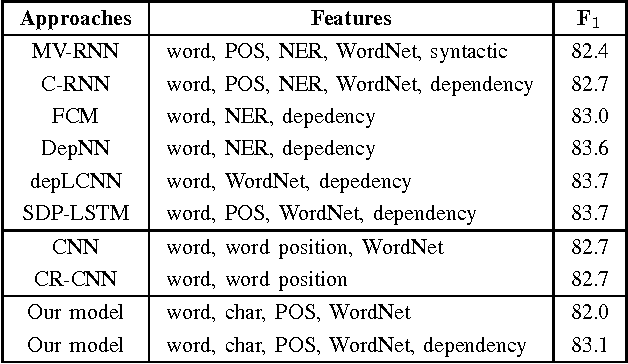
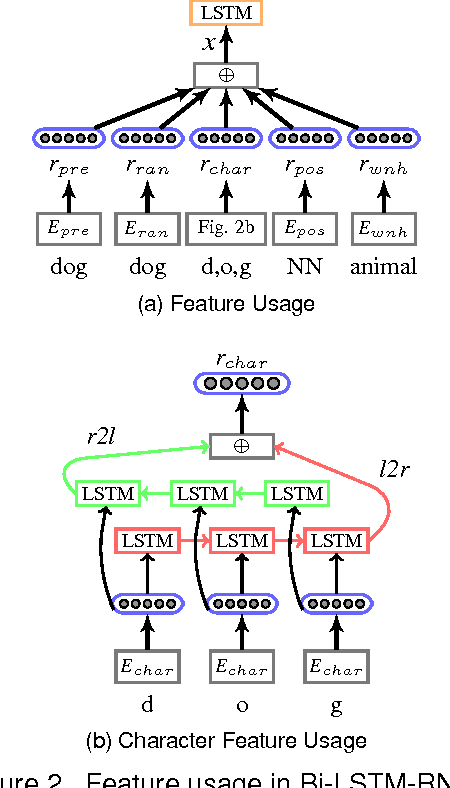

Relation classification is associated with many potential applications in the artificial intelligence area. Recent approaches usually leverage neural networks based on structure features such as syntactic or dependency features to solve this problem. However, high-cost structure features make such approaches inconvenient to be directly used. In addition, structure features are probably domain-dependent. Therefore, this paper proposes a bi-directional long-short-term-memory recurrent-neural-network (Bi-LSTM-RNN) model based on low-cost sequence features to address relation classification. This model divides a sentence or text segment into five parts, namely two target entities and their three contexts. It learns the representations of entities and their contexts, and uses them to classify relations. We evaluate our model on two standard benchmark datasets in different domains, namely SemEval-2010 Task 8 and BioNLP-ST 2016 Task BB3. In the former dataset, our model achieves comparable performance compared with other models using sequence features. In the latter dataset, our model obtains the third best results compared with other models in the official evaluation. Moreover, we find that the context between two target entities plays the most important role in relation classification. Furthermore, statistic experiments show that the context between two target entities can be used as an approximate replacement of the shortest dependency path when dependency parsing is not used.