 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumans Hallucinate Too: Language Models Identify and Correct Subjective Annotation Errors With Label-in-a-Haystack Prompts
May 22, 2025Modeling complex subjective tasks in Natural Language Processing, such as recognizing emotion and morality, is considerably challenging due to significant variation in human annotations. This variation often reflects reasonable differences in semantic interpretations rather than mere noise, necessitating methods to distinguish between legitimate subjectivity and error. We address this challenge by exploring label verification in these contexts using Large Language Models (LLMs). First, we propose a simple In-Context Learning binary filtering baseline that estimates the reasonableness of a document-label pair. We then introduce the Label-in-a-Haystack setting: the query and its label(s) are included in the demonstrations shown to LLMs, which are prompted to predict the label(s) again, while receiving task-specific instructions (e.g., emotion recognition) rather than label copying. We show how the failure to copy the label(s) to the output of the LLM are task-relevant and informative. Building on this, we propose the Label-in-a-Haystack Rectification (LiaHR) framework for subjective label correction: when the model outputs diverge from the reference gold labels, we assign the generated labels to the example instead of discarding it. This approach can be integrated into annotation pipelines to enhance signal-to-noise ratios. Comprehensive analyses, human evaluations, and ecological validity studies verify the utility of LiaHR for label correction. Code is available at https://github.com/gchochla/LiaHR.
Deep Speech Synthesis from Multimodal Articulatory Representations
Dec 17, 2024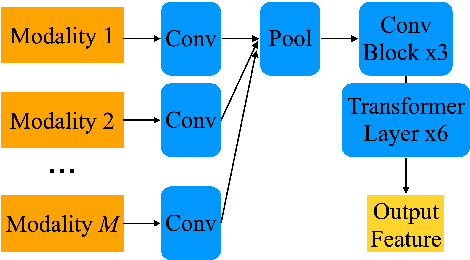
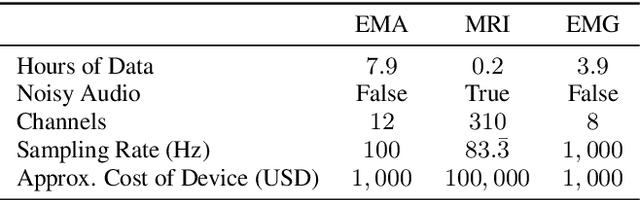
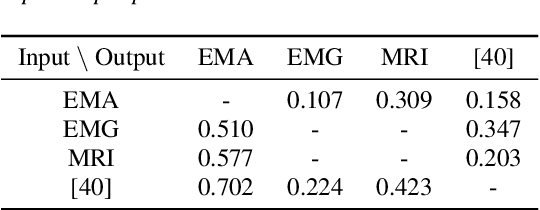

The amount of articulatory data available for training deep learning models is much less compared to acoustic speech data. In order to improve articulatory-to-acoustic synthesis performance in these low-resource settings, we propose a multimodal pre-training framework. On single-speaker speech synthesis tasks from real-time magnetic resonance imaging and surface electromyography inputs, the intelligibility of synthesized outputs improves noticeably. For example, compared to prior work, utilizing our proposed transfer learning methods improves the MRI-to-speech performance by 36% word error rate. In addition to these intelligibility results, our multimodal pre-trained models consistently outperform unimodal baselines on three objective and subjective synthesis quality metrics.
Fast, High-Quality and Parameter-Efficient Articulatory Synthesis using Differentiable DSP
Sep 04, 2024



Articulatory trajectories like electromagnetic articulography (EMA) provide a low-dimensional representation of the vocal tract filter and have been used as natural, grounded features for speech synthesis. Differentiable digital signal processing (DDSP) is a parameter-efficient framework for audio synthesis. Therefore, integrating low-dimensional EMA features with DDSP can significantly enhance the computational efficiency of speech synthesis. In this paper, we propose a fast, high-quality, and parameter-efficient DDSP articulatory vocoder that can synthesize speech from EMA, F0, and loudness. We incorporate several techniques to solve the harmonics / noise imbalance problem, and add a multi-resolution adversarial loss for better synthesis quality. Our model achieves a transcription word error rate (WER) of 6.67% and a mean opinion score (MOS) of 3.74, with an improvement of 1.63% and 0.16 compared to the state-of-the-art (SOTA) baseline. Our DDSP vocoder is 4.9x faster than the baseline on CPU during inference, and can generate speech of comparable quality with only 0.4M parameters, in contrast to the 9M parameters required by the SOTA.
Towards EMG-to-Speech with a Necklace Form Factor
Jul 31, 2024



Electrodes for decoding speech from electromyography (EMG) are typically placed on the face, requiring adhesives that are inconvenient and skin-irritating if used regularly. We explore a different device form factor, where dry electrodes are placed around the neck instead. 11-word, multi-speaker voiced EMG classifiers trained on data recorded with this device achieve 92.7% accuracy. Ablation studies reveal the importance of having more than two electrodes on the neck, and phonological analyses reveal similar classification confusions between neck-only and neck-and-face form factors. Finally, speech-EMG correlation experiments demonstrate a linear relationship between many EMG spectrogram frequency bins and self-supervised speech representation dimensions.
Multimodal Segmentation for Vocal Tract Modeling
Jun 22, 2024



Accurate modeling of the vocal tract is necessary to construct articulatory representations for interpretable speech processing and linguistics. However, vocal tract modeling is challenging because many internal articulators are occluded from external motion capture technologies. Real-time magnetic resonance imaging (RT-MRI) allows measuring precise movements of internal articulators during speech, but annotated datasets of MRI are limited in size due to time-consuming and computationally expensive labeling methods. We first present a deep labeling strategy for the RT-MRI video using a vision-only segmentation approach. We then introduce a multimodal algorithm using audio to improve segmentation of vocal articulators. Together, we set a new benchmark for vocal tract modeling in MRI video segmentation and use this to release labels for a 75-speaker RT-MRI dataset, increasing the amount of labeled public RT-MRI data of the vocal tract by over a factor of 9. The code and dataset labels can be found at \url{rishiraij.github.io/multimodal-mri-avatar/}.
Articulatory Encodec: Vocal Tract Kinematics as a Codec for Speech
Jun 18, 2024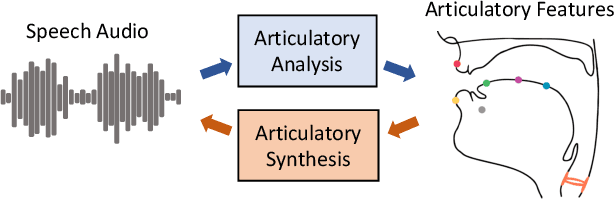
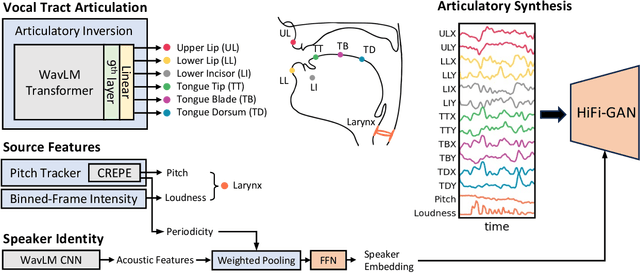

Vocal tract articulation is a natural, grounded control space of speech production. The spatiotemporal coordination of articulators combined with the vocal source shapes intelligible speech sounds to enable effective spoken communication. Based on this physiological grounding of speech, we propose a new framework of neural encoding-decoding of speech -- articulatory encodec. The articulatory encodec comprises an articulatory analysis model that infers articulatory features from speech audio, and an articulatory synthesis model that synthesizes speech audio from articulatory features. The articulatory features are kinematic traces of vocal tract articulators and source features, which are intuitively interpretable and controllable, being the actual physical interface of speech production. An additional speaker identity encoder is jointly trained with the articulatory synthesizer to inform the voice texture of individual speakers. By training on large-scale speech data, we achieve a fully intelligible, high-quality articulatory synthesizer that generalizes to unseen speakers. Furthermore, the speaker embedding is effectively disentangled from articulations, which enables accent-perserving zero-shot voice conversion. To the best of our knowledge, this is the first demonstration of universal, high-performance articulatory inference and synthesis, suggesting the proposed framework as a powerful coding system of speech.
Unconstrained Dysfluency Modeling for Dysfluent Speech Transcription and Detection
Dec 20, 2023Dysfluent speech modeling requires time-accurate and silence-aware transcription at both the word-level and phonetic-level. However, current research in dysfluency modeling primarily focuses on either transcription or detection, and the performance of each aspect remains limited. In this work, we present an unconstrained dysfluency modeling (UDM) approach that addresses both transcription and detection in an automatic and hierarchical manner. UDM eliminates the need for extensive manual annotation by providing a comprehensive solution. Furthermore, we introduce a simulated dysfluent dataset called VCTK++ to enhance the capabilities of UDM in phonetic transcription. Our experimental results demonstrate the effectiveness and robustness of our proposed methods in both transcription and detection tasks.
Towards Streaming Speech-to-Avatar Synthesis
Oct 25, 2023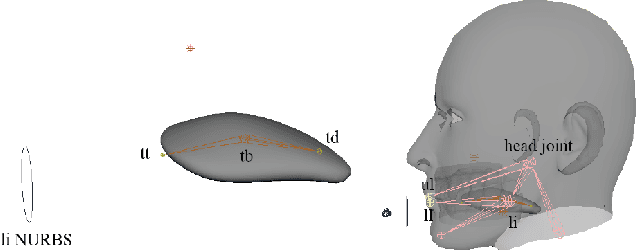
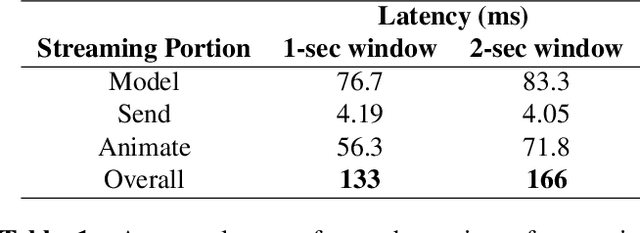
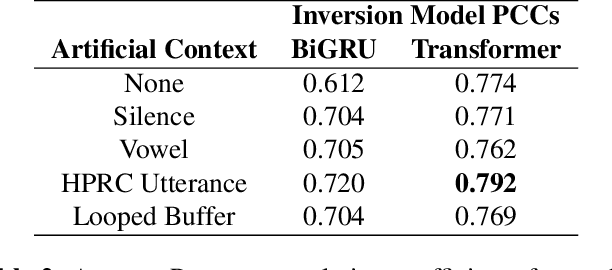

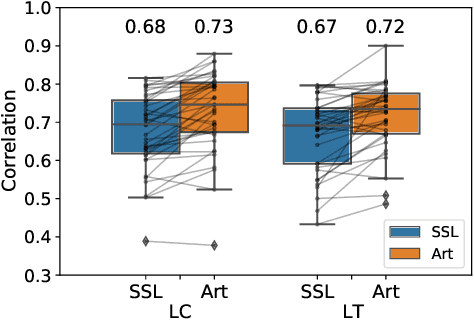
Streaming speech-to-avatar synthesis creates real-time animations for a virtual character from audio data. Accurate avatar representations of speech are important for the visualization of sound in linguistics, phonetics, and phonology, visual feedback to assist second language acquisition, and virtual embodiment for paralyzed patients. Previous works have highlighted the capability of deep articulatory inversion to perform high-quality avatar animation using electromagnetic articulography (EMA) features. However, these models focus on offline avatar synthesis with recordings rather than real-time audio, which is necessary for live avatar visualization or embodiment. To address this issue, we propose a method using articulatory inversion for streaming high quality facial and inner-mouth avatar animation from real-time audio. Our approach achieves 130ms average streaming latency for every 0.1 seconds of audio with a 0.792 correlation with ground truth articulations. Finally, we show generated mouth and tongue animations to demonstrate the efficacy of our methodology.
Towards an Interpretable Representation of Speaker Identity via Perceptual Voice Qualities
Oct 04, 2023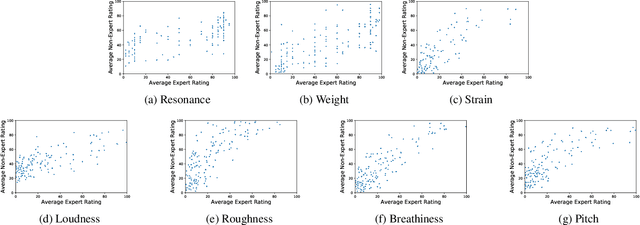

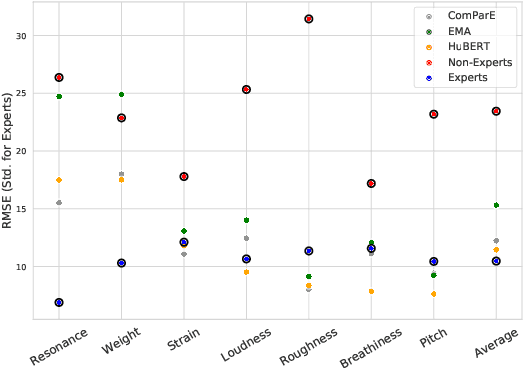
Unlike other data modalities such as text and vision, speech does not lend itself to easy interpretation. While lay people can understand how to describe an image or sentence via perception, non-expert descriptions of speech often end at high-level demographic information, such as gender or age. In this paper, we propose a possible interpretable representation of speaker identity based on perceptual voice qualities (PQs). By adding gendered PQs to the pathology-focused Consensus Auditory-Perceptual Evaluation of Voice (CAPE-V) protocol, our PQ-based approach provides a perceptual latent space of the character of adult voices that is an intermediary of abstraction between high-level demographics and low-level acoustic, physical, or learned representations. Contrary to prior belief, we demonstrate that these PQs are hearable by ensembles of non-experts, and further demonstrate that the information encoded in a PQ-based representation is predictable by various speech representations.
CiwaGAN: Articulatory information exchange
Sep 14, 2023



Humans encode information into sounds by controlling articulators and decode information from sounds using the auditory apparatus. This paper introduces CiwaGAN, a model of human spoken language acquisition that combines unsupervised articulatory modeling with an unsupervised model of information exchange through the auditory modality. While prior research includes unsupervised articulatory modeling and information exchange separately, our model is the first to combine the two components. The paper also proposes an improved articulatory model with more interpretable internal representations. The proposed CiwaGAN model is the most realistic approximation of human spoken language acquisition using deep learning. As such, it is useful for cognitively plausible simulations of the human speech act.