 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMO-Reasoning: Benchmarking Emotional Reasoning Capabilities in Spoken Dialogue Systems
Aug 25, 2025Speech emotions play a crucial role in human-computer interaction, shaping engagement and context-aware communication. Despite recent advances in spoken dialogue systems, a holistic system for evaluating emotional reasoning is still lacking. To address this, we introduce EMO-Reasoning, a benchmark for assessing emotional coherence in dialogue systems. It leverages a curated dataset generated via text-to-speech to simulate diverse emotional states, overcoming the scarcity of emotional speech data. We further propose the Cross-turn Emotion Reasoning Score to assess the emotion transitions in multi-turn dialogues. Evaluating seven dialogue systems through continuous, categorical, and perceptual metrics, we show that our framework effectively detects emotional inconsistencies, providing insights for improving current dialogue systems. By releasing a systematic evaluation benchmark, we aim to advance emotion-aware spoken dialogue modeling toward more natural and adaptive interactions.
Sound Check: Auditing Audio Datasets
Oct 17, 2024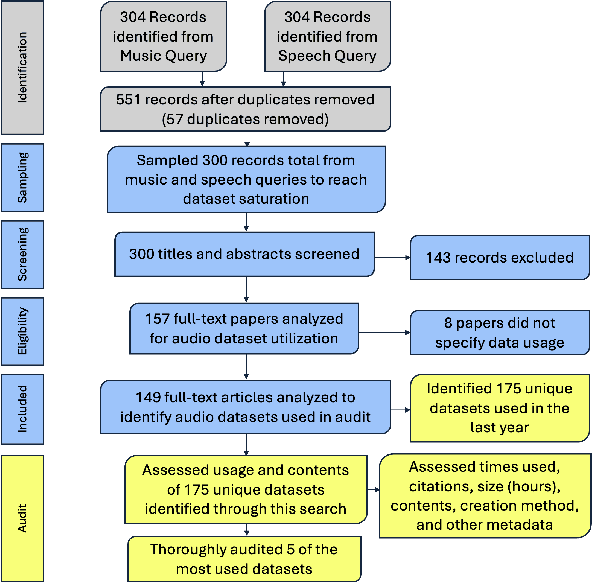
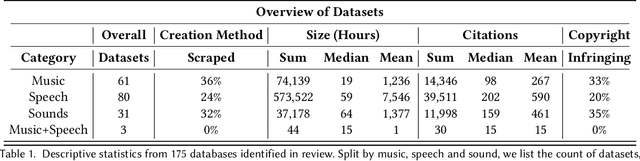
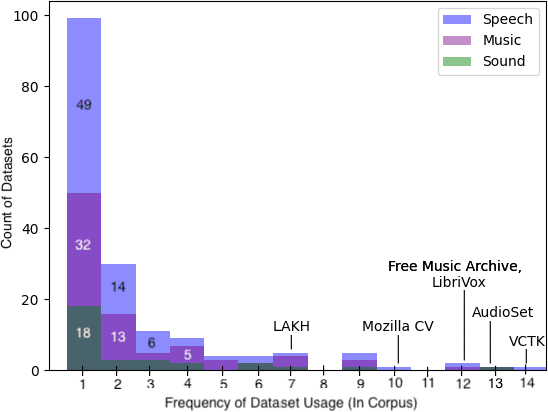

Generative audio models are rapidly advancing in both capabilities and public utilization -- several powerful generative audio models have readily available open weights, and some tech companies have released high quality generative audio products. Yet, while prior work has enumerated many ethical issues stemming from the data on which generative visual and textual models have been trained, we have little understanding of similar issues with generative audio datasets, including those related to bias, toxicity, and intellectual property. To bridge this gap, we conducted a literature review of hundreds of audio datasets and selected seven of the most prominent to audit in more detail. We found that these datasets are biased against women, contain toxic stereotypes about marginalized communities, and contain significant amounts of copyrighted work. To enable artists to see if they are in popular audio datasets and facilitate exploration of the contents of these datasets, we developed a web tool audio datasets exploration tool at https://audio-audit.vercel.app.
Speech After Gender: A Trans-Feminine Perspective on Next Steps for Speech Science and Technology
Jul 09, 2024



As experts in voice modification, trans-feminine gender-affirming voice teachers have unique perspectives on voice that confound current understandings of speaker identity. To demonstrate this, we present the Versatile Voice Dataset (VVD), a collection of three speakers modifying their voices along gendered axes. The VVD illustrates that current approaches in speaker modeling, based on categorical notions of gender and a static understanding of vocal texture, fail to account for the flexibility of the vocal tract. Utilizing publicly-available speaker embeddings, we demonstrate that gender classification systems are highly sensitive to voice modification, and speaker verification systems fail to identify voices as coming from the same speaker as voice modification becomes more drastic. As one path towards moving beyond categorical and static notions of speaker identity, we propose modeling individual qualities of vocal texture such as pitch, resonance, and weight.
PerMod: Perceptually Grounded Voice Modification with Latent Diffusion Models
Dec 13, 2023


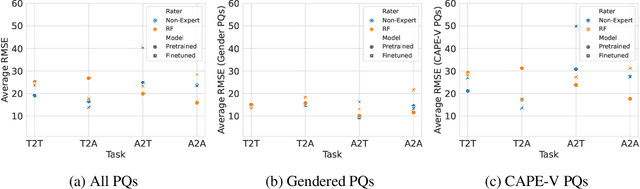
Perceptual modification of voice is an elusive goal. While non-experts can modify an image or sentence perceptually with available tools, it is not clear how to similarly modify speech along perceptual axes. Voice conversion does make it possible to convert one voice to another, but these modifications are handled by black box models, and the specifics of what perceptual qualities to modify and how to modify them are unclear. Towards allowing greater perceptual control over voice, we introduce PerMod, a conditional latent diffusion model that takes in an input voice and a perceptual qualities vector, and produces a voice with the matching perceptual qualities. Unlike prior work, PerMod generates a new voice corresponding to specific perceptual modifications. Evaluating perceptual quality vectors with RMSE from both human and predicted labels, we demonstrate that PerMod produces voices with the desired perceptual qualities for typical voices, but performs poorly on atypical voices.
Towards an Interpretable Representation of Speaker Identity via Perceptual Voice Qualities
Oct 04, 2023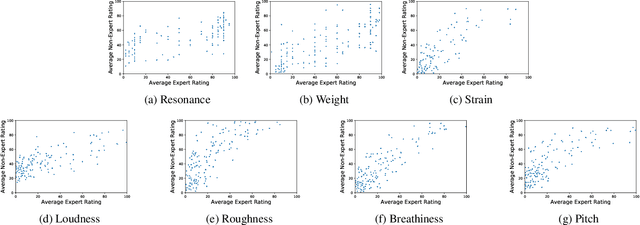

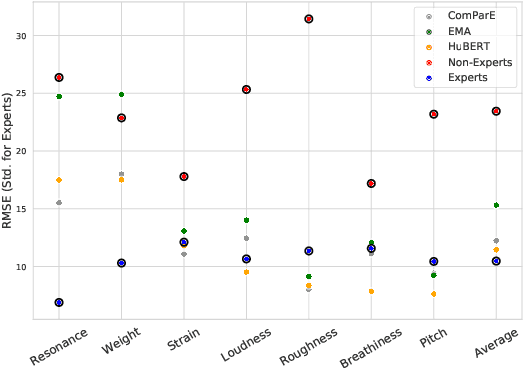
Unlike other data modalities such as text and vision, speech does not lend itself to easy interpretation. While lay people can understand how to describe an image or sentence via perception, non-expert descriptions of speech often end at high-level demographic information, such as gender or age. In this paper, we propose a possible interpretable representation of speaker identity based on perceptual voice qualities (PQs). By adding gendered PQs to the pathology-focused Consensus Auditory-Perceptual Evaluation of Voice (CAPE-V) protocol, our PQ-based approach provides a perceptual latent space of the character of adult voices that is an intermediary of abstraction between high-level demographics and low-level acoustic, physical, or learned representations. Contrary to prior belief, we demonstrate that these PQs are hearable by ensembles of non-experts, and further demonstrate that the information encoded in a PQ-based representation is predictable by various speech representations.
Improving Prototypical Part Networks with Reward Reweighing, Reselection, and Retraining
Jul 08, 2023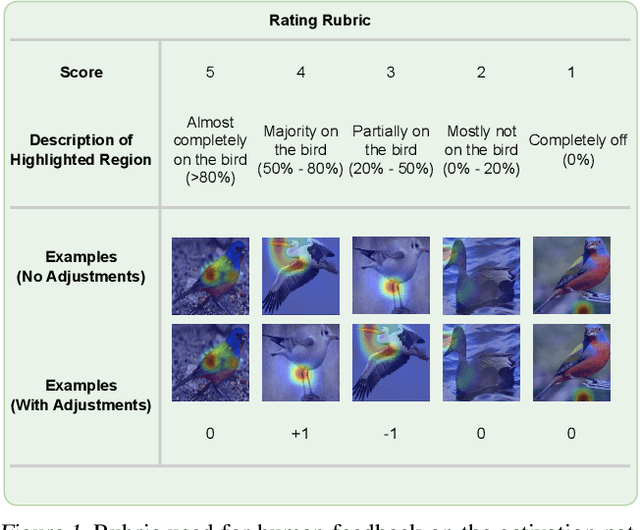
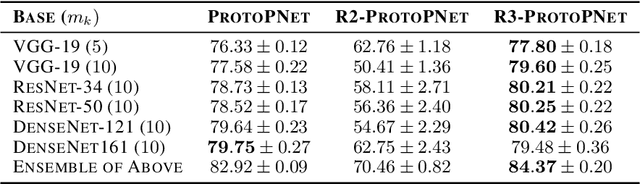

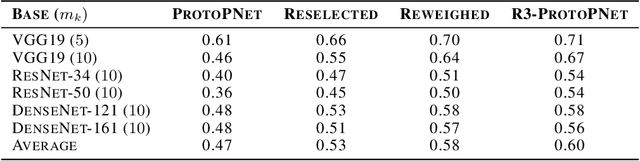
In recent years, work has gone into developing deep interpretable methods for image classification that clearly attributes a model's output to specific features of the data. One such of these methods is the prototypical part network (ProtoPNet), which attempts to classify images based on meaningful parts of the input. While this method results in interpretable classifications, this method often learns to classify from spurious or inconsistent parts of the image. Hoping to remedy this, we take inspiration from the recent developments in Reinforcement Learning with Human Feedback (RLHF) to fine-tune these prototypes. By collecting human annotations of prototypes quality via a 1-5 scale on the CUB-200-2011 dataset, we construct a reward model that learns to identify non-spurious prototypes. In place of a full RL update, we propose the reweighted, reselected, and retrained prototypical part network (R3-ProtoPNet), which adds an additional three steps to the ProtoPNet training loop. The first two steps are reward-based reweighting and reselection, which align prototypes with human feedback. The final step is retraining to realign the model's features with the updated prototypes. We find that R3-ProtoPNet improves the overall consistency and meaningfulness of the prototypes, but lower the test predictive accuracy when used independently. When multiple R3-ProtoPNets are incorporated into an ensemble, we find an increase in test predictive performance while maintaining interpretability.