 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow do data owners say no? A case study of data consent mechanisms in web-scraped vision-language AI training datasets
Nov 10, 2025The internet has become the main source of data to train modern text-to-image or vision-language models, yet it is increasingly unclear whether web-scale data collection practices for training AI systems adequately respect data owners' wishes. Ignoring the owner's indication of consent around data usage not only raises ethical concerns but also has recently been elevated into lawsuits around copyright infringement cases. In this work, we aim to reveal information about data owners' consent to AI scraping and training, and study how it's expressed in DataComp, a popular dataset of 12.8 billion text-image pairs. We examine both the sample-level information, including the copyright notice, watermarking, and metadata, and the web-domain-level information, such as a site's Terms of Service (ToS) and Robots Exclusion Protocol. We estimate at least 122M of samples exhibit some indication of copyright notice in CommonPool, and find that 60\% of the samples in the top 50 domains come from websites with ToS that prohibit scraping. Furthermore, we estimate 9-13\% with 95\% confidence interval of samples from CommonPool to contain watermarks, where existing watermark detection methods fail to capture them in high fidelity. Our holistic methods and findings show that data owners rely on various channels to convey data consent, of which current AI data collection pipelines do not entirely respect. These findings highlight the limitations of the current dataset curation/release practice and the need for a unified data consent framework taking AI purposes into consideration.
Sound Check: Auditing Audio Datasets
Oct 17, 2024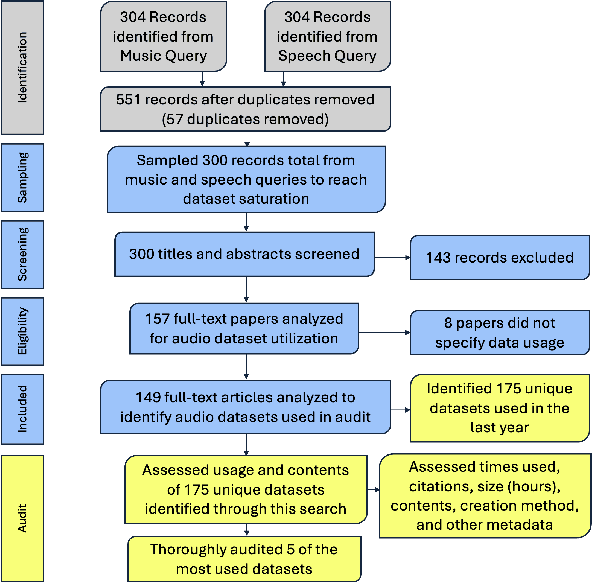
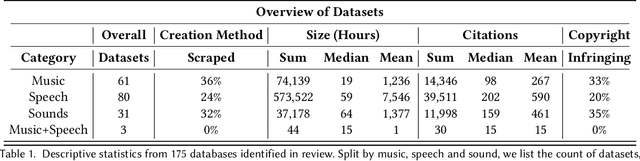
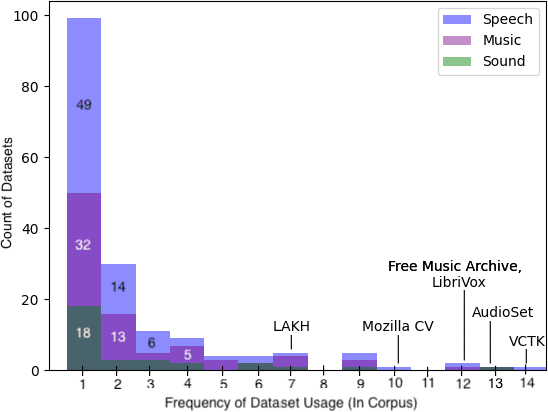

Generative audio models are rapidly advancing in both capabilities and public utilization -- several powerful generative audio models have readily available open weights, and some tech companies have released high quality generative audio products. Yet, while prior work has enumerated many ethical issues stemming from the data on which generative visual and textual models have been trained, we have little understanding of similar issues with generative audio datasets, including those related to bias, toxicity, and intellectual property. To bridge this gap, we conducted a literature review of hundreds of audio datasets and selected seven of the most prominent to audit in more detail. We found that these datasets are biased against women, contain toxic stereotypes about marginalized communities, and contain significant amounts of copyrighted work. To enable artists to see if they are in popular audio datasets and facilitate exploration of the contents of these datasets, we developed a web tool audio datasets exploration tool at https://audio-audit.vercel.app.
Who's in and who's out? A case study of multimodal CLIP-filtering in DataComp
May 13, 2024



As training datasets become increasingly drawn from unstructured, uncontrolled environments such as the web, researchers and industry practitioners have increasingly relied upon data filtering techniques to "filter out the noise" of web-scraped data. While datasets have been widely shown to reflect the biases and values of their creators, in this paper we contribute to an emerging body of research that assesses the filters used to create these datasets. We show that image-text data filtering also has biases and is value-laden, encoding specific notions of what is counted as "high-quality" data. In our work, we audit a standard approach of image-text CLIP-filtering on the academic benchmark DataComp's CommonPool by analyzing discrepancies of filtering through various annotation techniques across multiple modalities of image, text, and website source. We find that data relating to several imputed demographic groups -- such as LGBTQ+ people, older women, and younger men -- are associated with higher rates of exclusion. Moreover, we demonstrate cases of exclusion amplification: not only are certain marginalized groups already underrepresented in the unfiltered data, but CLIP-filtering excludes data from these groups at higher rates. The data-filtering step in the machine learning pipeline can therefore exacerbate representation disparities already present in the data-gathering step, especially when existing filters are designed to optimize a specifically-chosen downstream performance metric like zero-shot image classification accuracy. Finally, we show that the NSFW filter fails to remove sexually-explicit content from CommonPool, and that CLIP-filtering includes several categories of copyrighted content at high rates. Our conclusions point to a need for fundamental changes in dataset creation and filtering practices.
Representation via Representations: Domain Generalization via Adversarially Learned Invariant Representations
Jun 20, 2020


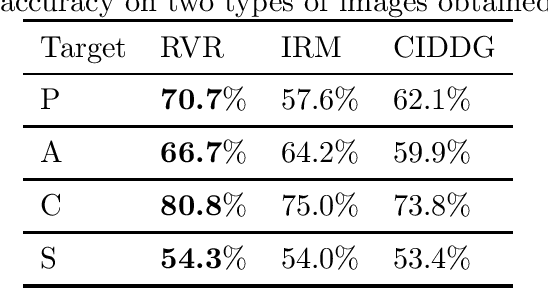
We investigate the power of censoring techniques, first developed for learning {\em fair representations}, to address domain generalization. We examine {\em adversarial} censoring techniques for learning invariant representations from multiple "studies" (or domains), where each study is drawn according to a distribution on domains. The mapping is used at test time to classify instances from a new domain. In many contexts, such as medical forecasting, domain generalization from studies in populous areas (where data are plentiful), to geographically remote populations (for which no training data exist) provides fairness of a different flavor, not anticipated in previous work on algorithmic fairness. We study an adversarial loss function for $k$ domains and precisely characterize its limiting behavior as $k$ grows, formalizing and proving the intuition, backed by experiments, that observing data from a larger number of domains helps. The limiting results are accompanied by non-asymptotic learning-theoretic bounds. Furthermore, we obtain sufficient conditions for good worst-case prediction performance of our algorithm on previously unseen domains. Finally, we decompose our mappings into two components and provide a complete characterization of invariance in terms of this decomposition. To our knowledge, our results provide the first formal guarantees of these kinds for adversarial invariant domain generalization.