 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Label the Repeats for In-The-Wild Audio-to-Score Alignment
Nov 11, 2024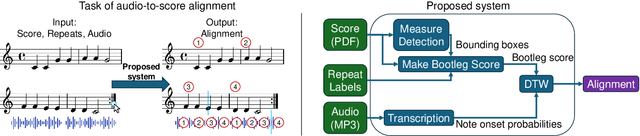



We propose an efficient workflow for high-quality offline alignment of in-the-wild performance audio and corresponding sheet music scans (images). Recent work on audio-to-score alignment extends dynamic time warping (DTW) to be theoretically able to handle jumps in sheet music induced by repeat signs-this method requires no human annotations, but we show that it often yields low-quality alignments. As an alternative, we propose a workflow and interface that allows users to quickly annotate jumps (by clicking on repeat signs), requiring a small amount of human supervision but yielding much higher quality alignments on average. Additionally, we refine audio and score feature representations to improve alignment quality by: (1) integrating measure detection into the score feature representation, and (2) using raw onset prediction probabilities from a music transcription model instead of piano roll. We propose an evaluation protocol for audio-to-score alignment that computes the distance between the estimated and ground truth alignment in units of measures. Under this evaluation, we find that our proposed jump annotation workflow and improved feature representations together improve alignment accuracy by 150% relative to prior work (33% to 82%).
Sound Check: Auditing Audio Datasets
Oct 17, 2024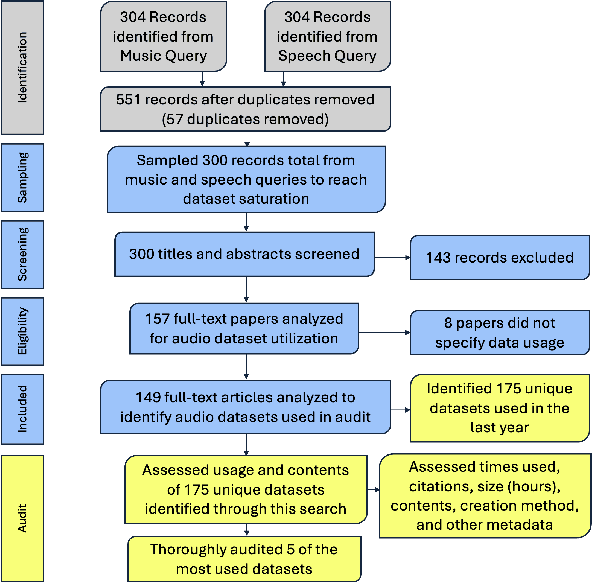
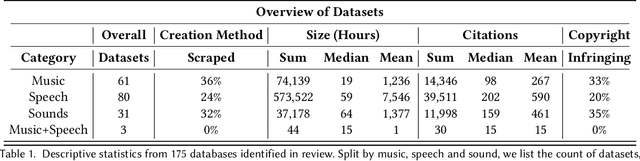
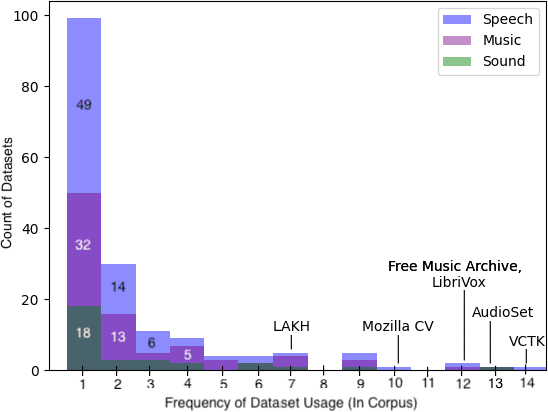

Generative audio models are rapidly advancing in both capabilities and public utilization -- several powerful generative audio models have readily available open weights, and some tech companies have released high quality generative audio products. Yet, while prior work has enumerated many ethical issues stemming from the data on which generative visual and textual models have been trained, we have little understanding of similar issues with generative audio datasets, including those related to bias, toxicity, and intellectual property. To bridge this gap, we conducted a literature review of hundreds of audio datasets and selected seven of the most prominent to audit in more detail. We found that these datasets are biased against women, contain toxic stereotypes about marginalized communities, and contain significant amounts of copyrighted work. To enable artists to see if they are in popular audio datasets and facilitate exploration of the contents of these datasets, we developed a web tool audio datasets exploration tool at https://audio-audit.vercel.app.
Prompt Exploration with Prompt Regression
May 17, 2024



In the advent of democratized usage of large language models (LLMs), there is a growing desire to systematize LLM prompt creation and selection processes beyond iterative trial-and-error. Prior works majorly focus on searching the space of prompts without accounting for relations between prompt variations. Here we propose a framework, Prompt Exploration with Prompt Regression (PEPR), to predict the effect of prompt combinations given results for individual prompt elements as well as a simple method to select an effective prompt for a given use-case. We evaluate our approach with open-source LLMs of different sizes on several different tasks.
Red-Teaming for Generative AI: Silver Bullet or Security Theater?
Jan 29, 2024In response to rising concerns surrounding the safety, security, and trustworthiness of Generative AI (GenAI) models, practitioners and regulators alike have pointed to AI red-teaming as a key component of their strategies for identifying and mitigating these risks. However, despite AI red-teaming's central role in policy discussions and corporate messaging, significant questions remain about what precisely it means, what role it can play in regulation, and how precisely it relates to conventional red-teaming practices as originally conceived in the field of cybersecurity. In this work, we identify recent cases of red-teaming activities in the AI industry and conduct an extensive survey of the relevant research literature to characterize the scope, structure, and criteria for AI red-teaming practices. Our analysis reveals that prior methods and practices of AI red-teaming diverge along several axes, including the purpose of the activity (which is often vague), the artifact under evaluation, the setting in which the activity is conducted (e.g., actors, resources, and methods), and the resulting decisions it informs (e.g., reporting, disclosure, and mitigation). In light of our findings, we argue that while red-teaming may be a valuable big-tent idea for characterizing a broad set of activities and attitudes aimed at improving the behavior of GenAI models, gestures towards red-teaming as a panacea for every possible risk verge on security theater. To move toward a more robust toolbox of evaluations for generative AI, we synthesize our recommendations into a question bank meant to guide and scaffold future AI red-teaming practices.
The AI Incident Database as an Educational Tool to Raise Awareness of AI Harms: A Classroom Exploration of Efficacy, Limitations, & Future Improvements
Oct 10, 2023Prior work has established the importance of integrating AI ethics topics into computer and data sciences curricula. We provide evidence suggesting that one of the critical objectives of AI Ethics education must be to raise awareness of AI harms. While there are various sources to learn about such harms, The AI Incident Database (AIID) is one of the few attempts at offering a relatively comprehensive database indexing prior instances of harms or near harms stemming from the deployment of AI technologies in the real world. This study assesses the effectiveness of AIID as an educational tool to raise awareness regarding the prevalence and severity of AI harms in socially high-stakes domains. We present findings obtained through a classroom study conducted at an R1 institution as part of a course focused on the societal and ethical considerations around AI and ML. Our qualitative findings characterize students' initial perceptions of core topics in AI ethics and their desire to close the educational gap between their technical skills and their ability to think systematically about ethical and societal aspects of their work. We find that interacting with the database helps students better understand the magnitude and severity of AI harms and instills in them a sense of urgency around (a) designing functional and safe AI and (b) strengthening governance and accountability mechanisms. Finally, we compile students' feedback about the tool and our class activity into actionable recommendations for the database development team and the broader community to improve awareness of AI harms in AI ethics education.
A Suite of Fairness Datasets for Tabular Classification
Jul 31, 2023



There have been many papers with algorithms for improving fairness of machine-learning classifiers for tabular data. Unfortunately, most use only very few datasets for their experimental evaluation. We introduce a suite of functions for fetching 20 fairness datasets and providing associated fairness metadata. Hopefully, these will lead to more rigorous experimental evaluations in future fairness-aware machine learning research.
Moral Machine or Tyranny of the Majority?
May 27, 2023
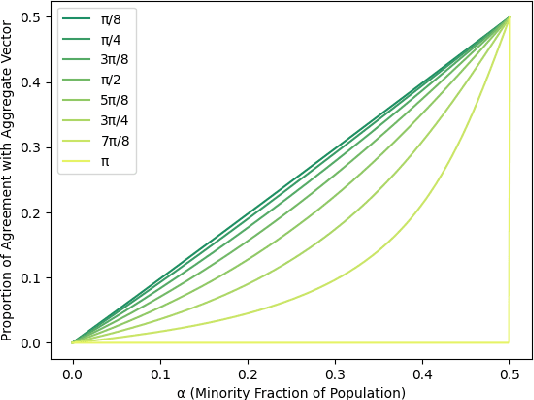


With Artificial Intelligence systems increasingly applied in consequential domains, researchers have begun to ask how these systems ought to act in ethically charged situations where even humans lack consensus. In the Moral Machine project, researchers crowdsourced answers to "Trolley Problems" concerning autonomous vehicles. Subsequently, Noothigattu et al. (2018) proposed inferring linear functions that approximate each individual's preferences and aggregating these linear models by averaging parameters across the population. In this paper, we examine this averaging mechanism, focusing on fairness concerns in the presence of strategic effects. We investigate a simple setting where the population consists of two groups, with the minority constituting an {\alpha} < 0.5 share of the population. To simplify the analysis, we consider the extreme case in which within-group preferences are homogeneous. Focusing on the fraction of contested cases where the minority group prevails, we make the following observations: (a) even when all parties report their preferences truthfully, the fraction of disputes where the minority prevails is less than proportionate in {\alpha}; (b) the degree of sub-proportionality grows more severe as the level of disagreement between the groups increases; (c) when parties report preferences strategically, pure strategy equilibria do not always exist; and (d) whenever a pure strategy equilibrium exists, the majority group prevails 100% of the time. These findings raise concerns about stability and fairness of preference vector averaging as a mechanism for aggregating diverging voices. Finally, we discuss alternatives, including randomized dictatorship and median-based mechanisms.
Navigating Ensemble Configurations for Algorithmic Fairness
Oct 11, 2022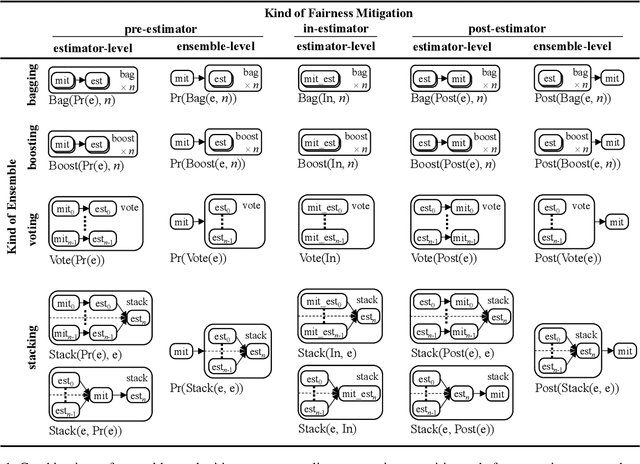
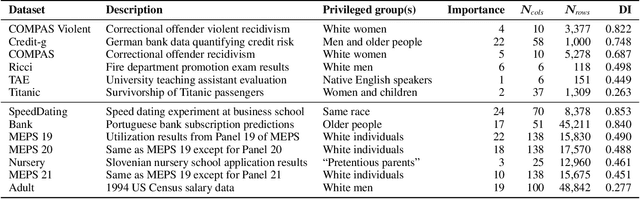

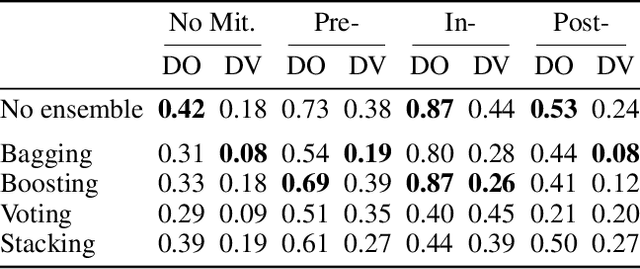
Bias mitigators can improve algorithmic fairness in machine learning models, but their effect on fairness is often not stable across data splits. A popular approach to train more stable models is ensemble learning, but unfortunately, it is unclear how to combine ensembles with mitigators to best navigate trade-offs between fairness and predictive performance. To that end, we built an open-source library enabling the modular composition of 8 mitigators, 4 ensembles, and their corresponding hyperparameters, and we empirically explored the space of configurations on 13 datasets. We distilled our insights from this exploration in the form of a guidance diagram for practitioners that we demonstrate is robust and reproducible.
An Empirical Study of Modular Bias Mitigators and Ensembles
Feb 01, 2022
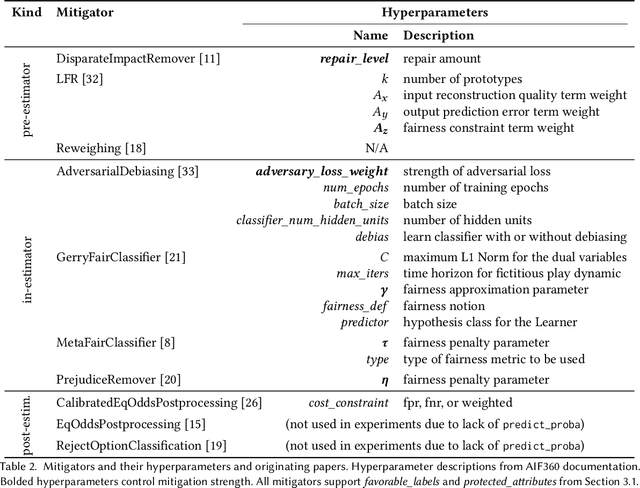
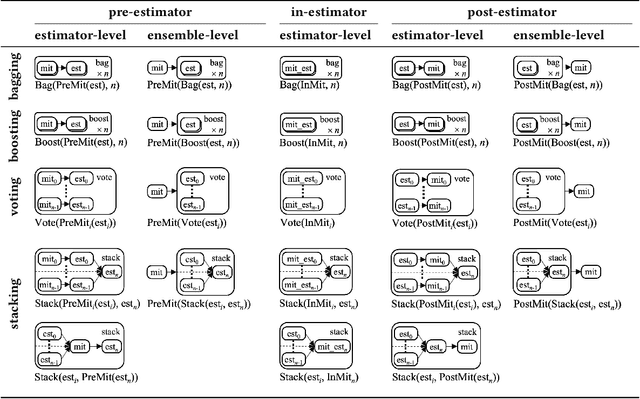
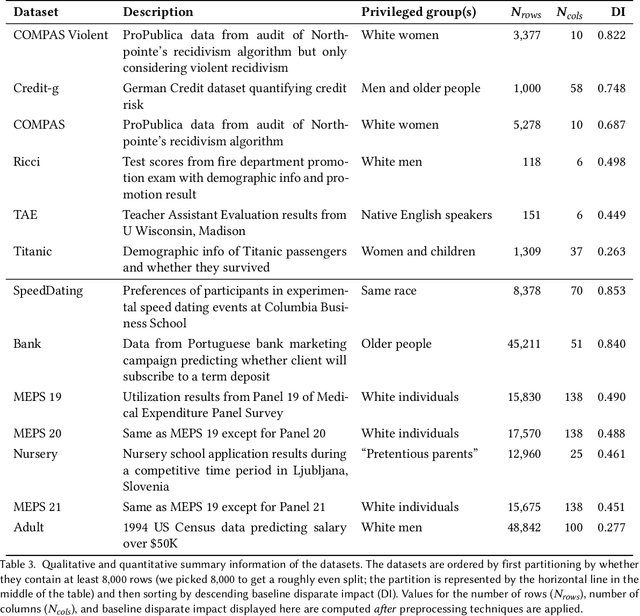
There are several bias mitigators that can reduce algorithmic bias in machine learning models but, unfortunately, the effect of mitigators on fairness is often not stable when measured across different data splits. A popular approach to train more stable models is ensemble learning. Ensembles, such as bagging, boosting, voting, or stacking, have been successful at making predictive performance more stable. One might therefore ask whether we can combine the advantages of bias mitigators and ensembles? To explore this question, we first need bias mitigators and ensembles to work together. We built an open-source library enabling the modular composition of 10 mitigators, 4 ensembles, and their corresponding hyperparameters. Based on this library, we empirically explored the space of combinations on 13 datasets, including datasets commonly used in fairness literature plus datasets newly curated by our library. Furthermore, we distilled the results into a guidance diagram for practitioners. We hope this paper will contribute towards improving stability in bias mitigation.