 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Music Captioning with Music Metadata LLMs
Feb 03, 2026Music captioning, or the task of generating a natural language description of music, is useful for both music understanding and controllable music generation. Training captioning models, however, typically requires high-quality music caption data which is scarce compared to metadata (e.g., genre, mood, etc.). As a result, it is common to use large language models (LLMs) to synthesize captions from metadata to generate training data for captioning models, though this process imposes a fixed stylization and entangles factual information with natural language style. As a more direct approach, we propose metadata-based captioning. We train a metadata prediction model to infer detailed music metadata from audio and then convert it into expressive captions via pre-trained LLMs at inference time. Compared to a strong end-to-end baseline trained on LLM-generated captions derived from metadata, our method: (1) achieves comparable performance in less training time over end-to-end captioners, (2) offers flexibility to easily change stylization post-training, enabling output captions to be tailored to specific stylistic and quality requirements, and (3) can be prompted with audio and partial metadata to enable powerful metadata imputation or in-filling--a common task for organizing music data.
Unified Cross-modal Translation of Score Images, Symbolic Music, and Performance Audio
May 19, 2025Music exists in various modalities, such as score images, symbolic scores, MIDI, and audio. Translations between each modality are established as core tasks of music information retrieval, such as automatic music transcription (audio-to-MIDI) and optical music recognition (score image to symbolic score). However, most past work on multimodal translation trains specialized models on individual translation tasks. In this paper, we propose a unified approach, where we train a general-purpose model on many translation tasks simultaneously. Two key factors make this unified approach viable: a new large-scale dataset and the tokenization of each modality. Firstly, we propose a new dataset that consists of more than 1,300 hours of paired audio-score image data collected from YouTube videos, which is an order of magnitude larger than any existing music modal translation datasets. Secondly, our unified tokenization framework discretizes score images, audio, MIDI, and MusicXML into a sequence of tokens, enabling a single encoder-decoder Transformer to tackle multiple cross-modal translation as one coherent sequence-to-sequence task. Experimental results confirm that our unified multitask model improves upon single-task baselines in several key areas, notably reducing the symbol error rate for optical music recognition from 24.58% to a state-of-the-art 13.67%, while similarly substantial improvements are observed across the other translation tasks. Notably, our approach achieves the first successful score-image-conditioned audio generation, marking a significant breakthrough in cross-modal music generation.
Just Label the Repeats for In-The-Wild Audio-to-Score Alignment
Nov 11, 2024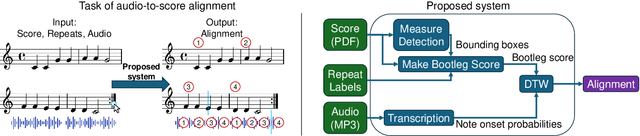



We propose an efficient workflow for high-quality offline alignment of in-the-wild performance audio and corresponding sheet music scans (images). Recent work on audio-to-score alignment extends dynamic time warping (DTW) to be theoretically able to handle jumps in sheet music induced by repeat signs-this method requires no human annotations, but we show that it often yields low-quality alignments. As an alternative, we propose a workflow and interface that allows users to quickly annotate jumps (by clicking on repeat signs), requiring a small amount of human supervision but yielding much higher quality alignments on average. Additionally, we refine audio and score feature representations to improve alignment quality by: (1) integrating measure detection into the score feature representation, and (2) using raw onset prediction probabilities from a music transcription model instead of piano roll. We propose an evaluation protocol for audio-to-score alignment that computes the distance between the estimated and ground truth alignment in units of measures. Under this evaluation, we find that our proposed jump annotation workflow and improved feature representations together improve alignment accuracy by 150% relative to prior work (33% to 82%).