 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rhythm In Anything: Audio-Prompted Drums Generation with Masked Language Modeling
Sep 19, 2025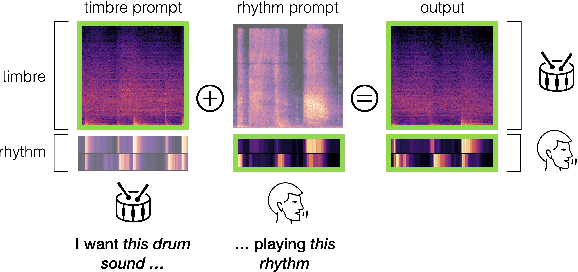
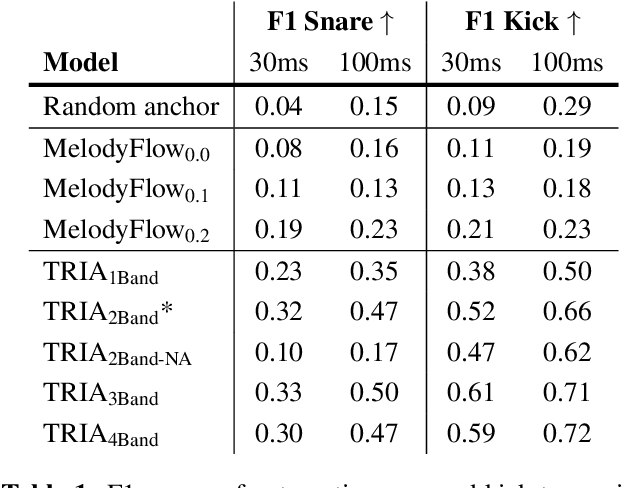
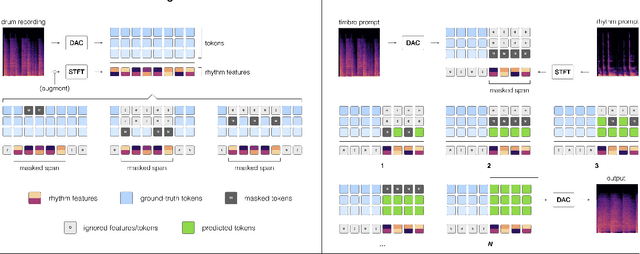
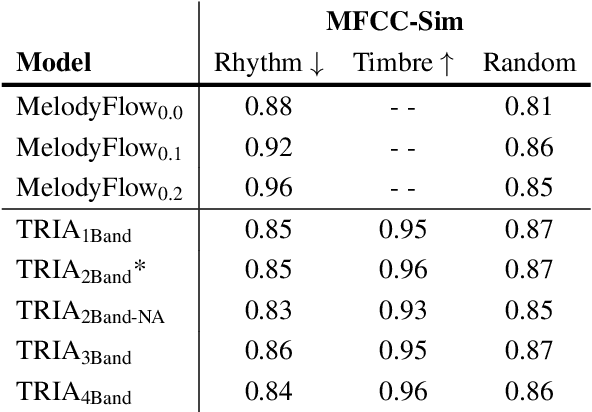
Musicians and nonmusicians alike use rhythmic sound gestures, such as tapping and beatboxing, to express drum patterns. While these gestures effectively communicate musical ideas, realizing these ideas as fully-produced drum recordings can be time-consuming, potentially disrupting many creative workflows. To bridge this gap, we present TRIA (The Rhythm In Anything), a masked transformer model for mapping rhythmic sound gestures to high-fidelity drum recordings. Given an audio prompt of the desired rhythmic pattern and a second prompt to represent drumkit timbre, TRIA produces audio of a drumkit playing the desired rhythm (with appropriate elaborations) in the desired timbre. Subjective and objective evaluations show that a TRIA model trained on less than 10 hours of publicly-available drum data can generate high-quality, faithful realizations of sound gestures across a wide range of timbres in a zero-shot manner.
Scenarios in Computing Research: A Systematic Review of the Use of Scenario Methods for Exploring the Future of Computing Technologies in Society
Jun 05, 2025Scenario building is an established method to anticipate the future of emerging technologies. Its primary goal is to use narratives to map future trajectories of technology development and sociotechnical adoption. Following this process, risks and benefits can be identified early on, and strategies can be developed that strive for desirable futures. In recent years, computer science has adopted this method and applied it to various technologies, including Artificial Intelligence (AI). Because computing technologies play such an important role in shaping modern societies, it is worth exploring how scenarios are being used as an anticipatory tool in the field -- and what possible traditional uses of scenarios are not yet covered but have the potential to enrich the field. We address this gap by conducting a systematic literature review on the use of scenario building methods in computer science over the last decade (n = 59). We guide the review along two main questions. First, we aim to uncover how scenarios are used in computing literature, focusing especially on the rationale for why scenarios are used. Second, in following the potential of scenario building to enhance inclusivity in research, we dive deeper into the participatory element of the existing scenario building literature in computer science.
Sound Check: Auditing Audio Datasets
Oct 17, 2024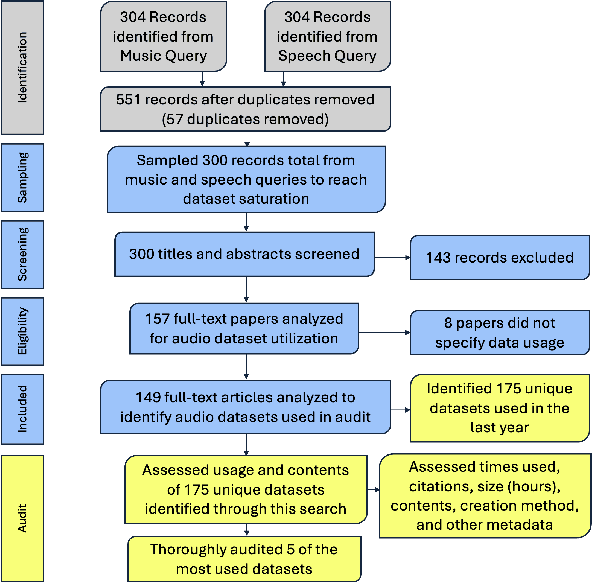
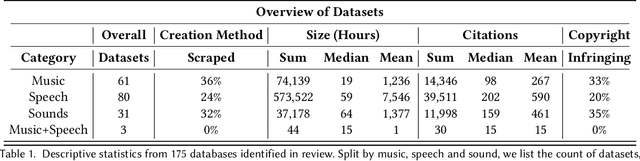
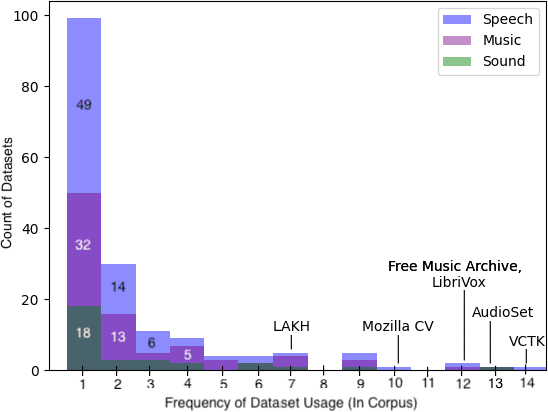

Generative audio models are rapidly advancing in both capabilities and public utilization -- several powerful generative audio models have readily available open weights, and some tech companies have released high quality generative audio products. Yet, while prior work has enumerated many ethical issues stemming from the data on which generative visual and textual models have been trained, we have little understanding of similar issues with generative audio datasets, including those related to bias, toxicity, and intellectual property. To bridge this gap, we conducted a literature review of hundreds of audio datasets and selected seven of the most prominent to audit in more detail. We found that these datasets are biased against women, contain toxic stereotypes about marginalized communities, and contain significant amounts of copyrighted work. To enable artists to see if they are in popular audio datasets and facilitate exploration of the contents of these datasets, we developed a web tool audio datasets exploration tool at https://audio-audit.vercel.app.
Text2FX: Harnessing CLAP Embeddings for Text-Guided Audio Effects
Sep 27, 2024



This work introduces Text2FX, a method that leverages CLAP embeddings and differentiable digital signal processing to control audio effects, such as equalization and reverberation, using open-vocabulary natural language prompts (e.g., "make this sound in-your-face and bold"). Text2FX operates without retraining any models, relying instead on single-instance optimization within the existing embedding space. We show that CLAP encodes valuable information for controlling audio effects and propose two optimization approaches using CLAP to map text to audio effect parameters. While we demonstrate with CLAP, this approach is applicable to any shared text-audio embedding space. Similarly, while we demonstrate with equalization and reverberation, any differentiable audio effect may be controlled. We conduct a listener study with diverse text prompts and source audio to evaluate the quality and alignment of these methods with human perception.
Simulating Policy Impacts: Developing a Generative Scenario Writing Method to Evaluate the Perceived Effects of Regulation
May 15, 2024



The rapid advancement of AI technologies yields numerous future impacts on individuals and society. Policy-makers are therefore tasked to react quickly and establish policies that mitigate those impacts. However, anticipating the effectiveness of policies is a difficult task, as some impacts might only be observable in the future and respective policies might not be applicable to the future development of AI. In this work we develop a method for using large language models (LLMs) to evaluate the efficacy of a given piece of policy at mitigating specified negative impacts. We do so by using GPT-4 to generate scenarios both pre- and post-introduction of policy and translating these vivid stories into metrics based on human perceptions of impacts. We leverage an already established taxonomy of impacts of generative AI in the media environment to generate a set of scenario pairs both mitigated and non-mitigated by the transparency legislation of Article 50 of the EU AI Act. We then run a user study (n=234) to evaluate these scenarios across four risk-assessment dimensions: severity, plausibility, magnitude, and specificity to vulnerable populations. We find that this transparency legislation is perceived to be effective at mitigating harms in areas such as labor and well-being, but largely ineffective in areas such as social cohesion and security. Through this case study on generative AI harms we demonstrate the efficacy of our method as a tool to iterate on the effectiveness of policy on mitigating various negative impacts. We expect this method to be useful to researchers or other stakeholders who want to brainstorm the potential utility of different pieces of policy or other mitigation strategies.
Exploring Musical Roots: Applying Audio Embeddings to Empower Influence Attribution for a Generative Music Model
Jan 25, 2024



Every artist has a creative process that draws inspiration from previous artists and their works. Today, "inspiration" has been automated by generative music models. The black box nature of these models obscures the identity of the works that influence their creative output. As a result, users may inadvertently appropriate, misuse, or copy existing artists' works. We establish a replicable methodology to systematically identify similar pieces of music audio in a manner that is useful for understanding training data attribution. A key aspect of our approach is to harness an effective music audio similarity measure. We compare the effect of applying CLMR and CLAP embeddings to similarity measurement in a set of 5 million audio clips used to train VampNet, a recent open source generative music model. We validate this approach with a human listening study. We also explore the effect that modifications of an audio example (e.g., pitch shifting, time stretching, background noise) have on similarity measurements. This work is foundational to incorporating automated influence attribution into generative modeling, which promises to let model creators and users move from ignorant appropriation to informed creation. Audio samples that accompany this paper are available at https://tinyurl.com/exploring-musical-roots.
The Ethical Implications of Generative Audio Models: A Systematic Literature Review
Jul 07, 2023Generative audio models typically focus their applications in music and speech generation, with recent models having human-like quality in their audio output. This paper conducts a systematic literature review of 884 papers in the area of generative audio models in order to both quantify the degree to which researchers in the field are considering potential negative impacts and identify the types of ethical implications researchers in this area need to consider. Though 65% of generative audio research papers note positive potential impacts of their work, less than 10% discuss any negative impacts. This jarringly small percentage of papers considering negative impact is particularly worrying because the issues brought to light by the few papers doing so are raising serious ethical implications and concerns relevant to the broader field such as the potential for fraud, deep-fakes, and copyright infringement. By quantifying this lack of ethical consideration in generative audio research and identifying key areas of potential harm, this paper lays the groundwork for future work in the field at a critical point in time in order to guide more conscientious research as this field progresses.