 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting from Predictions
Aug 15, 2022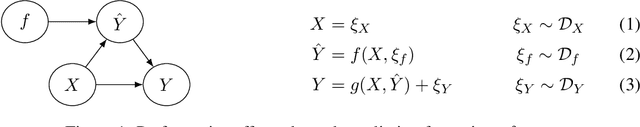
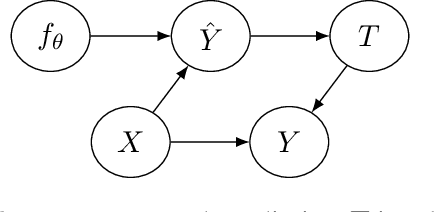
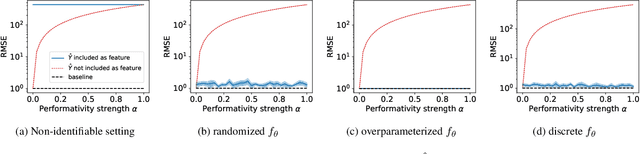
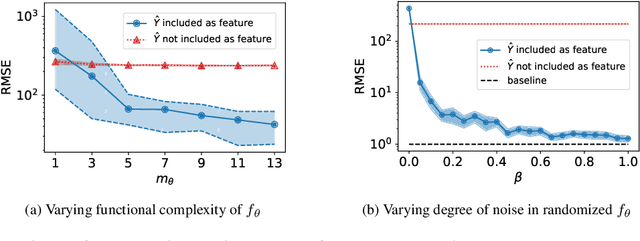
Predictions about people, such as their expected educational achievement or their credit risk, can be performative and shape the outcome that they aim to predict. Understanding the causal effect of these predictions on the eventual outcomes is crucial for foreseeing the implications of future predictive models and selecting which models to deploy. However, this causal estimation task poses unique challenges: model predictions are usually deterministic functions of input features and highly correlated with outcomes, which can make the causal effects of predictions impossible to disentangle from the direct effect of the covariates. We study this problem through the lens of causal identifiability, and despite the hardness of this problem in full generality, we highlight three natural scenarios where the causal effect of predictions on outcomes can be identified from observational data: randomization in predictions or prediction-based decisions, overparameterization of the predictive model deployed during data collection, and discrete prediction outputs. We show empirically that, under suitable identifiability conditions, standard variants of supervised learning that predict from predictions can find transferable functional relationships between features, predictions, and outcomes, allowing for conclusions about newly deployed prediction models. Our positive results fundamentally rely on model predictions being recorded during data collection, bringing forward the importance of rethinking standard data collection practices to enable progress towards a better understanding of social outcomes and performative feedback loops.
Retiring Adult: New Datasets for Fair Machine Learning
Aug 10, 2021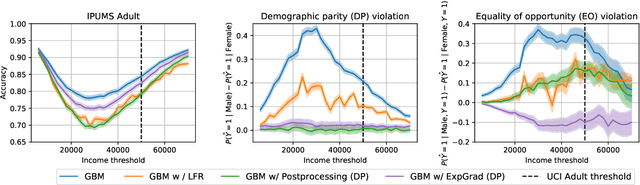
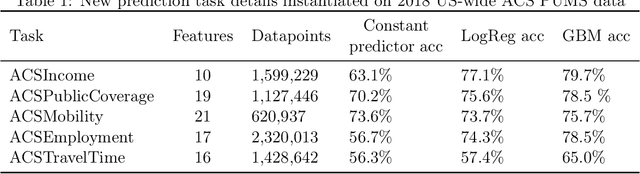
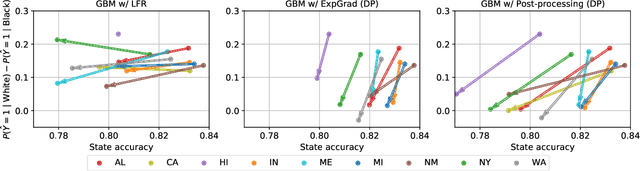

Although the fairness community has recognized the importance of data, researchers in the area primarily rely on UCI Adult when it comes to tabular data. Derived from a 1994 US Census survey, this dataset has appeared in hundreds of research papers where it served as the basis for the development and comparison of many algorithmic fairness interventions. We reconstruct a superset of the UCI Adult data from available US Census sources and reveal idiosyncrasies of the UCI Adult dataset that limit its external validity. Our primary contribution is a suite of new datasets derived from US Census surveys that extend the existing data ecosystem for research on fair machine learning. We create prediction tasks relating to income, employment, health, transportation, and housing. The data span multiple years and all states of the United States, allowing researchers to study temporal shift and geographic variation. We highlight a broad initial sweep of new empirical insights relating to trade-offs between fairness criteria, performance of algorithmic interventions, and the role of distribution shift based on our new datasets. Our findings inform ongoing debates, challenge some existing narratives, and point to future research directions. Our datasets are available at https://github.com/zykls/folktables.
Grounding Representation Similarity with Statistical Testing
Aug 03, 2021
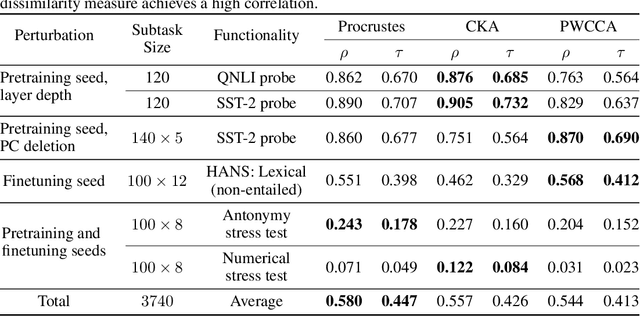


To understand neural network behavior, recent works quantitatively compare different networks' learned representations using canonical correlation analysis (CCA), centered kernel alignment (CKA), and other dissimilarity measures. Unfortunately, these widely used measures often disagree on fundamental observations, such as whether deep networks differing only in random initialization learn similar representations. These disagreements raise the question: which, if any, of these dissimilarity measures should we believe? We provide a framework to ground this question through a concrete test: measures should have sensitivity to changes that affect functional behavior, and specificity against changes that do not. We quantify this through a variety of functional behaviors including probing accuracy and robustness to distribution shift, and examine changes such as varying random initialization and deleting principal components. We find that current metrics exhibit different weaknesses, note that a classical baseline performs surprisingly well, and highlight settings where all metrics appear to fail, thus providing a challenge set for further improvement.
Representation via Representations: Domain Generalization via Adversarially Learned Invariant Representations
Jun 20, 2020


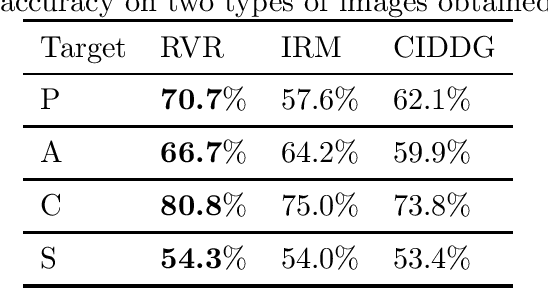
We investigate the power of censoring techniques, first developed for learning {\em fair representations}, to address domain generalization. We examine {\em adversarial} censoring techniques for learning invariant representations from multiple "studies" (or domains), where each study is drawn according to a distribution on domains. The mapping is used at test time to classify instances from a new domain. In many contexts, such as medical forecasting, domain generalization from studies in populous areas (where data are plentiful), to geographically remote populations (for which no training data exist) provides fairness of a different flavor, not anticipated in previous work on algorithmic fairness. We study an adversarial loss function for $k$ domains and precisely characterize its limiting behavior as $k$ grows, formalizing and proving the intuition, backed by experiments, that observing data from a larger number of domains helps. The limiting results are accompanied by non-asymptotic learning-theoretic bounds. Furthermore, we obtain sufficient conditions for good worst-case prediction performance of our algorithm on previously unseen domains. Finally, we decompose our mappings into two components and provide a complete characterization of invariance in terms of this decomposition. To our knowledge, our results provide the first formal guarantees of these kinds for adversarial invariant domain generalization.