 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning What Can Be Picked: Active Reachability Estimation for Efficient Robotic Fruit Harvesting
Mar 24, 2026Agriculture remains a cornerstone of global health and economic sustainability, yet labor-intensive tasks such as harvesting high-value crops continue to face growing workforce shortages. Robotic harvesting systems offer a promising solution; however, their deployment in unstructured orchard environments is constrained by inefficient perception-to-action pipelines. In particular, existing approaches often rely on exhaustive inverse kinematics or motion planning to determine whether a target fruit is reachable, leading to unnecessary computation and delayed decision-making. Our approach combines RGB-D perception with active learning to directly learn reachability as a binary decision problem. We then leverage active learning to selectively query the most informative samples for reachability labeling, significantly reducing annotation effort while maintaining high predictive accuracy. Extensive experiments demonstrate that the proposed framework achieves accurate reachability prediction with substantially fewer labeled samples, yielding approximately 6--8% higher accuracy than random sampling and enabling label-efficient adaptation to new orchard configurations. Among the evaluated strategies, entropy- and margin-based sampling outperform Query-by-Committee and standard uncertainty sampling in low-label regimes, while all strategies converge to comparable performance as the labeled set grows. These results highlight the effectiveness of active learning for task-level perception in agricultural robotics and position our approach as a scalable alternative to computation-heavy kinematic reachability analysis. Our code is available through https://github.com/wsu-cyber-security-lab-ai/active-learning.
Local transfer learning Gaussian process modeling, with applications to surrogate modeling of expensive computer simulators
Oct 17, 2024

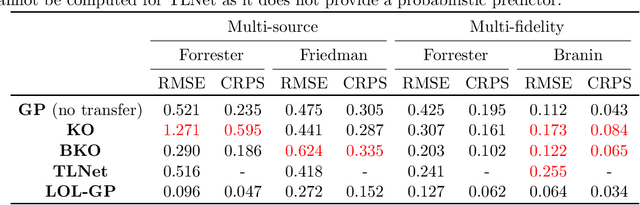

A critical bottleneck for scientific progress is the costly nature of computer simulations for complex systems. Surrogate models provide an appealing solution: such models are trained on simulator evaluations, then used to emulate and quantify uncertainty on the expensive simulator at unexplored inputs. In many applications, one often has available data on related systems. For example, in designing a new jet turbine, there may be existing studies on turbines with similar configurations. A key question is how information from such "source" systems can be transferred for effective surrogate training on the "target" system of interest. We thus propose a new LOcal transfer Learning Gaussian Process (LOL-GP) model, which leverages a carefully-designed Gaussian process to transfer such information for surrogate modeling. The key novelty of the LOL-GP is a latent regularization model, which identifies regions where transfer should be performed and regions where it should be avoided. This "local transfer" property is desirable in scientific systems: at certain parameters, such systems may behave similarly and thus transfer is beneficial; at other parameters, they may behave differently and thus transfer is detrimental. By accounting for local transfer, the LOL-GP can rectify a critical limitation of "negative transfer" in existing transfer learning models, where the transfer of information worsens predictive performance. We derive a Gibbs sampling algorithm for efficient posterior predictive sampling on the LOL-GP, for both the multi-source and multi-fidelity transfer settings. We then show, via a suite of numerical experiments and an application for jet turbine design, the improved surrogate performance of the LOL-GP over existing methods.
DART: Implicit Doppler Tomography for Radar Novel View Synthesis
Mar 06, 2024



Simulation is an invaluable tool for radio-frequency system designers that enables rapid prototyping of various algorithms for imaging, target detection, classification, and tracking. However, simulating realistic radar scans is a challenging task that requires an accurate model of the scene, radio frequency material properties, and a corresponding radar synthesis function. Rather than specifying these models explicitly, we propose DART - Doppler Aided Radar Tomography, a Neural Radiance Field-inspired method which uses radar-specific physics to create a reflectance and transmittance-based rendering pipeline for range-Doppler images. We then evaluate DART by constructing a custom data collection platform and collecting a novel radar dataset together with accurate position and instantaneous velocity measurements from lidar-based localization. In comparison to state-of-the-art baselines, DART synthesizes superior radar range-Doppler images from novel views across all datasets and additionally can be used to generate high quality tomographic images.
Adversarial Scrutiny of Evidentiary Statistical Software
Jun 19, 2022
The U.S. criminal legal system increasingly relies on software output to convict and incarcerate people. In a large number of cases each year, the government makes these consequential decisions based on evidence from statistical software -- such as probabilistic genotyping, environmental audio detection, and toolmark analysis tools -- that defense counsel cannot fully cross-examine or scrutinize. This undermines the commitments of the adversarial criminal legal system, which relies on the defense's ability to probe and test the prosecution's case to safeguard individual rights. Responding to this need to adversarially scrutinize output from such software, we propose robust adversarial testing as an audit framework to examine the validity of evidentiary statistical software. We define and operationalize this notion of robust adversarial testing for defense use by drawing on a large body of recent work in robust machine learning and algorithmic fairness. We demonstrate how this framework both standardizes the process for scrutinizing such tools and empowers defense lawyers to examine their validity for instances most relevant to the case at hand. We further discuss existing structural and institutional challenges within the U.S. criminal legal system that may create barriers for implementing this and other such audit frameworks and close with a discussion on policy changes that could help address these concerns.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Retiring Adult: New Datasets for Fair Machine Learning
Aug 10, 2021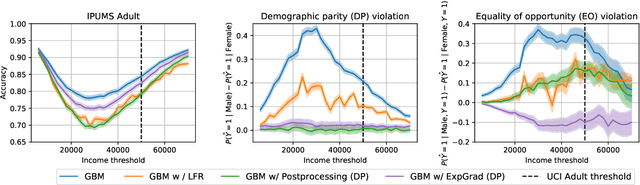
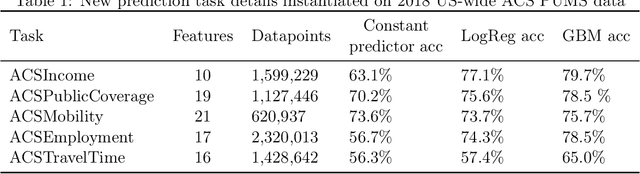
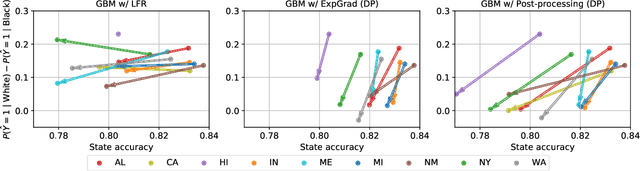

Although the fairness community has recognized the importance of data, researchers in the area primarily rely on UCI Adult when it comes to tabular data. Derived from a 1994 US Census survey, this dataset has appeared in hundreds of research papers where it served as the basis for the development and comparison of many algorithmic fairness interventions. We reconstruct a superset of the UCI Adult data from available US Census sources and reveal idiosyncrasies of the UCI Adult dataset that limit its external validity. Our primary contribution is a suite of new datasets derived from US Census surveys that extend the existing data ecosystem for research on fair machine learning. We create prediction tasks relating to income, employment, health, transportation, and housing. The data span multiple years and all states of the United States, allowing researchers to study temporal shift and geographic variation. We highlight a broad initial sweep of new empirical insights relating to trade-offs between fairness criteria, performance of algorithmic interventions, and the role of distribution shift based on our new datasets. Our findings inform ongoing debates, challenge some existing narratives, and point to future research directions. Our datasets are available at https://github.com/zykls/folktables.
Improving COVID-19 Forecasting using eXogenous Variables
Jul 20, 2021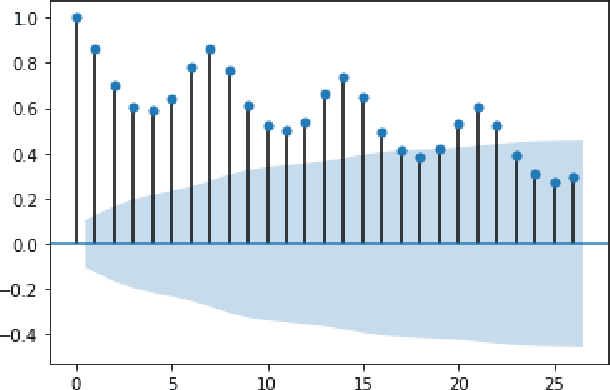
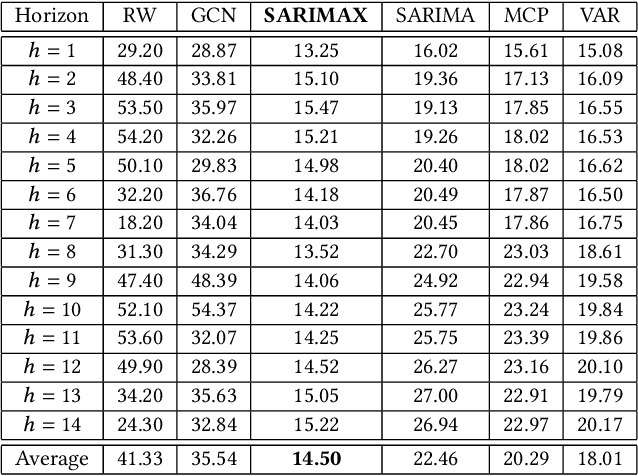
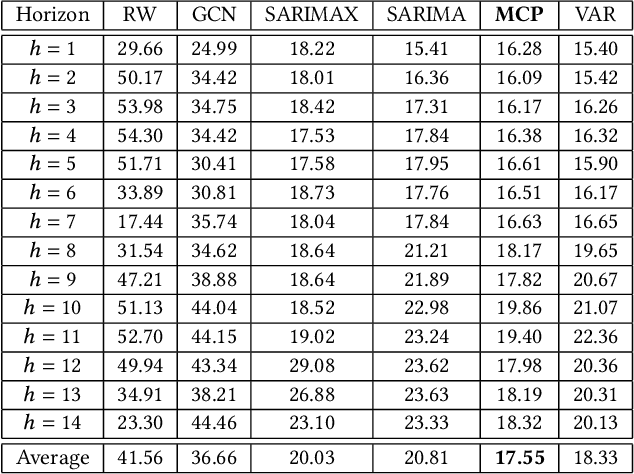
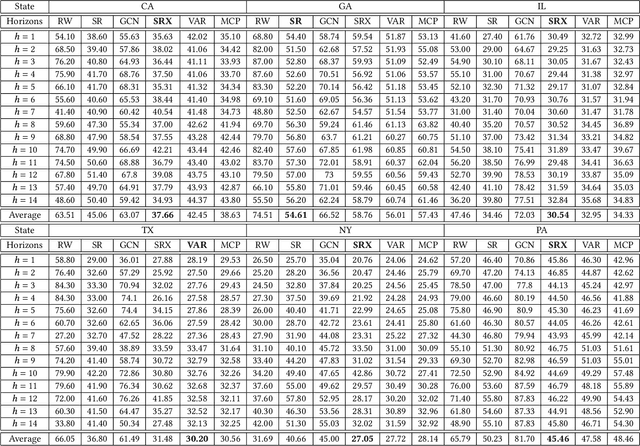
In this work, we study the pandemic course in the United States by considering national and state levels data. We propose and compare multiple time-series prediction techniques which incorporate auxiliary variables. One type of approach is based on spatio-temporal graph neural networks which forecast the pandemic course by utilizing a hybrid deep learning architecture and human mobility data. Nodes in this graph represent the state-level deaths due to COVID-19, edges represent the human mobility trend and temporal edges correspond to node attributes across time. The second approach is based on a statistical technique for COVID-19 mortality prediction in the United States that uses the SARIMA model and eXogenous variables. We evaluate these techniques on both state and national levels COVID-19 data in the United States and claim that the SARIMA and MCP models generated forecast values by the eXogenous variables can enrich the underlying model to capture complexity in respectively national and state levels data. We demonstrate significant enhancement in the forecasting accuracy for a COVID-19 dataset, with a maximum improvement in forecasting accuracy by 64.58% and 59.18% (on average) over the GCN-LSTM model in the national level data, and 58.79% and 52.40% (on average) over the GCN-LSTM model in the state level data. Additionally, our proposed model outperforms a parallel study (AUG-NN) by 27.35% improvement of accuracy on average.
Accuracy on the Line: On the Strong Correlation Between Out-of-Distribution and In-Distribution Generalization
Jul 09, 2021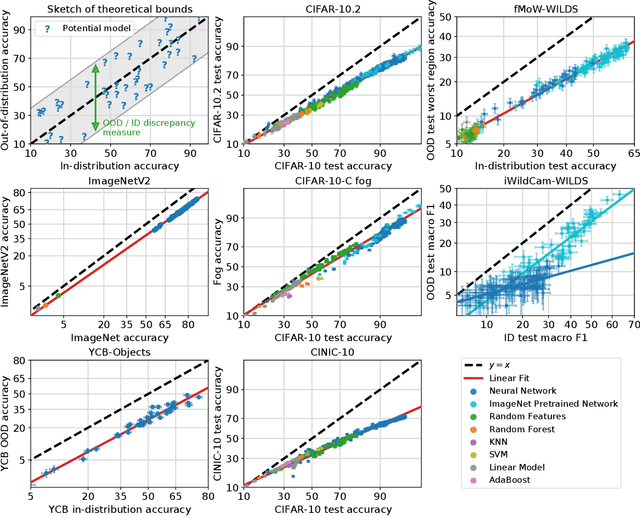
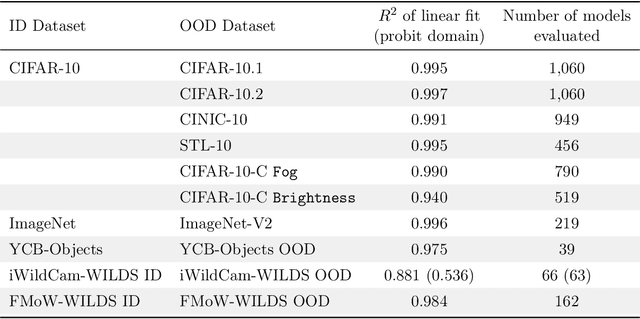
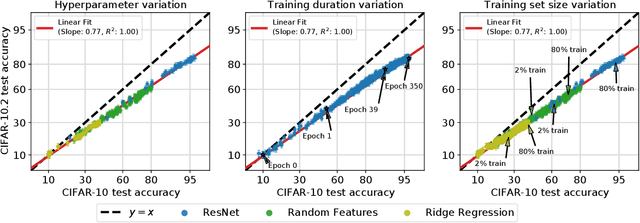

For machine learning systems to be reliable, we must understand their performance in unseen, out-of-distribution environments. In this paper, we empirically show that out-of-distribution performance is strongly correlated with in-distribution performance for a wide range of models and distribution shifts. Specifically, we demonstrate strong correlations between in-distribution and out-of-distribution performance on variants of CIFAR-10 & ImageNet, a synthetic pose estimation task derived from YCB objects, satellite imagery classification in FMoW-WILDS, and wildlife classification in iWildCam-WILDS. The strong correlations hold across model architectures, hyperparameters, training set size, and training duration, and are more precise than what is expected from existing domain adaptation theory. To complete the picture, we also investigate cases where the correlation is weaker, for instance some synthetic distribution shifts from CIFAR-10-C and the tissue classification dataset Camelyon17-WILDS. Finally, we provide a candidate theory based on a Gaussian data model that shows how changes in the data covariance arising from distribution shift can affect the observed correlations.
Outside the Echo Chamber: Optimizing the Performative Risk
Feb 17, 2021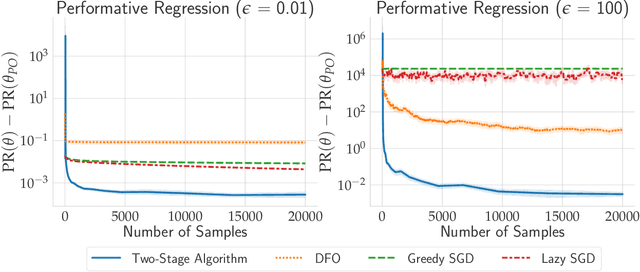
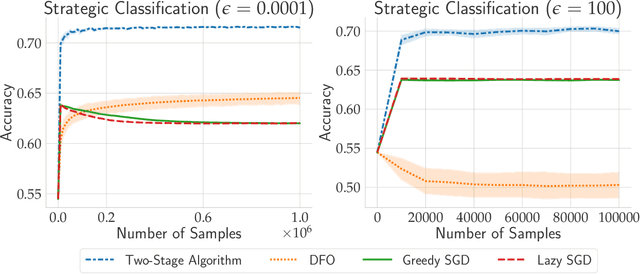
In performative prediction, predictions guide decision-making and hence can influence the distribution of future data. To date, work on performative prediction has focused on finding performatively stable models, which are the fixed points of repeated retraining. However, stable solutions can be far from optimal when evaluated in terms of the performative risk, the loss experienced by the decision maker when deploying a model. In this paper, we shift attention beyond performative stability and focus on optimizing the performative risk directly. We identify a natural set of properties of the loss function and model-induced distribution shift under which the performative risk is convex, a property which does not follow from convexity of the loss alone. Furthermore, we develop algorithms that leverage our structural assumptions to optimize the performative risk with better sample efficiency than generic methods for derivative-free convex optimization.
Gaussian Function On Response Surface Estimation
Jan 04, 2021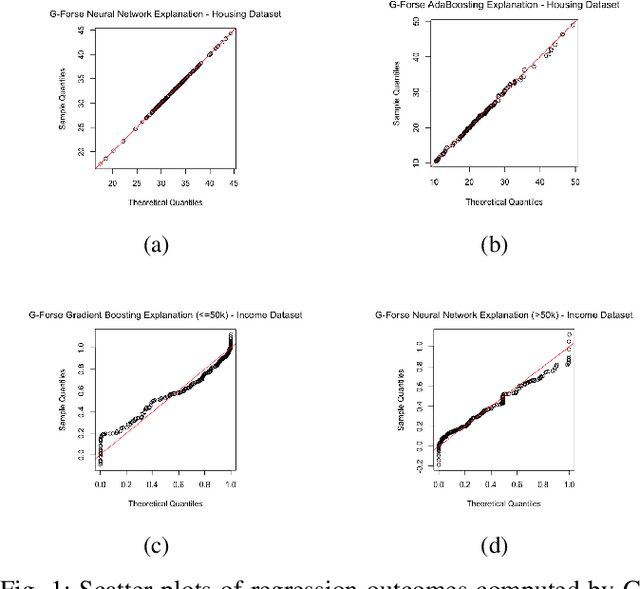
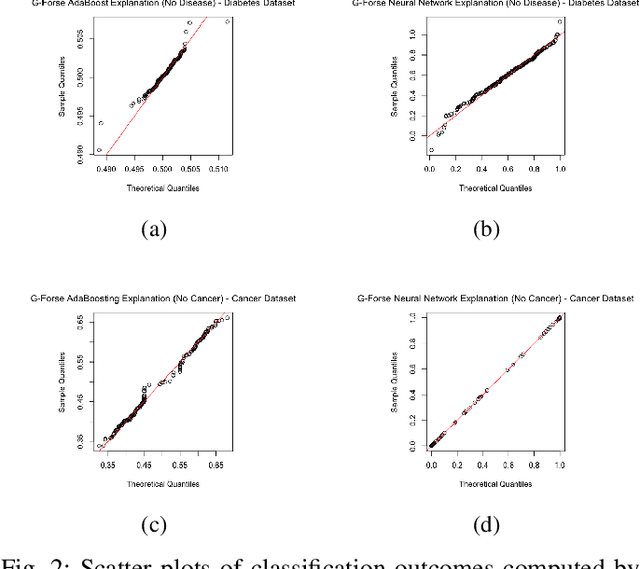
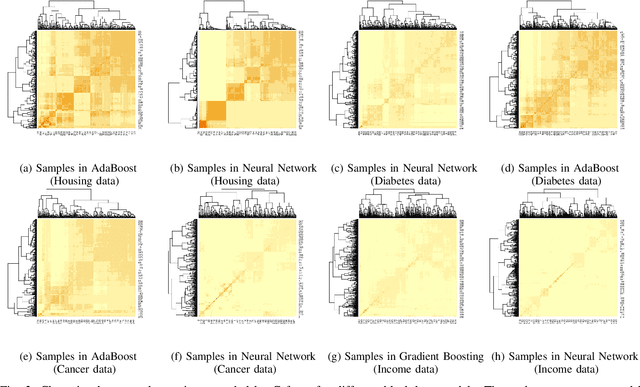
We propose a new framework for 2-D interpreting (features and samples) black-box machine learning models via a metamodeling technique, by which we study the output and input relationships of the underlying machine learning model. The metamodel can be estimated from data generated via a trained complex model by running the computer experiment on samples of data in the region of interest. We utilize a Gaussian process as a surrogate to capture the response surface of a complex model, in which we incorporate two parts in the process: interpolated values that are modeled by a stationary Gaussian process Z governed by a prior covariance function, and a mean function mu that captures the known trends in the underlying model. The optimization procedure for the variable importance parameter theta is to maximize the likelihood function. This theta corresponds to the correlation of individual variables with the target response. There is no need for any pre-assumed models since it depends on empirical observations. Experiments demonstrate the potential of the interpretable model through quantitative assessment of the predicted samples.