 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Breaking Feedback Loops in Recommender Systems with Causal Inference
Jul 15, 2022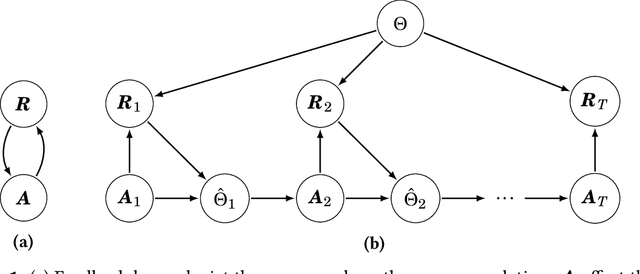
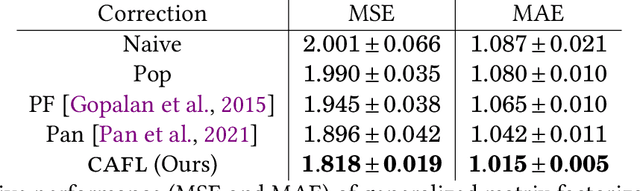
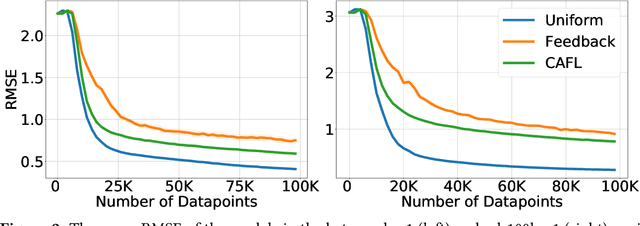
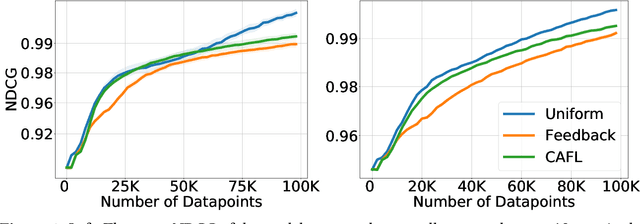
Recommender systems play a key role in shaping modern web ecosystems. These systems alternate between (1) making recommendations (2) collecting user responses to these recommendations, and (3) retraining the recommendation algorithm based on this feedback. During this process the recommender system influences the user behavioral data that is subsequently used to update it, thus creating a feedback loop. Recent work has shown that feedback loops may compromise recommendation quality and homogenize user behavior, raising ethical and performance concerns when deploying recommender systems. To address these issues, we propose the Causal Adjustment for Feedback Loops (CAFL), an algorithm that provably breaks feedback loops using causal inference and can be applied to any recommendation algorithm that optimizes a training loss. Our main observation is that a recommender system does not suffer from feedback loops if it reasons about causal quantities, namely the intervention distributions of recommendations on user ratings. Moreover, we can calculate this intervention distribution from observational data by adjusting for the recommender system's predictions of user preferences. Using simulated environments, we demonstrate that CAFL improves recommendation quality when compared to prior correction methods.
Recommendation Systems with Distribution-Free Reliability Guarantees
Jul 04, 2022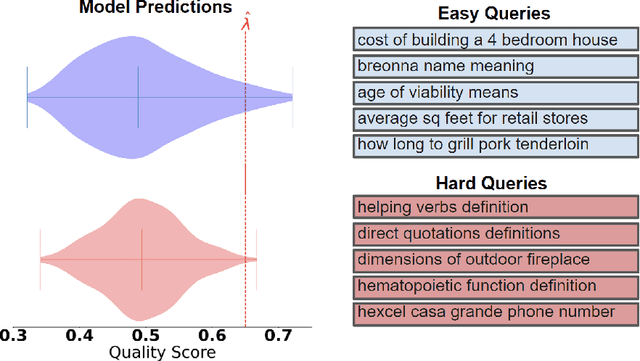
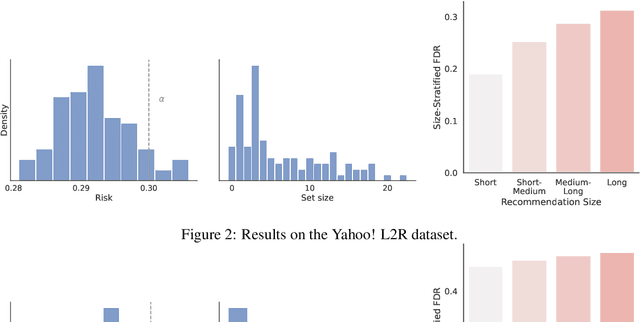
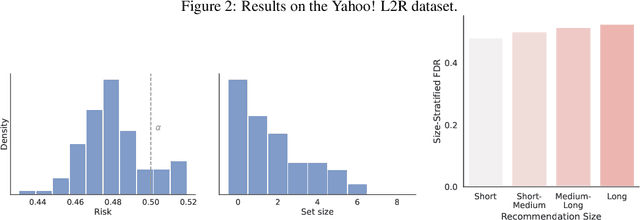
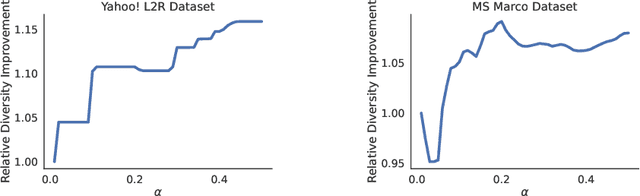
When building recommendation systems, we seek to output a helpful set of items to the user. Under the hood, a ranking model predicts which of two candidate items is better, and we must distill these pairwise comparisons into the user-facing output. However, a learned ranking model is never perfect, so taking its predictions at face value gives no guarantee that the user-facing output is reliable. Building from a pre-trained ranking model, we show how to return a set of items that is rigorously guaranteed to contain mostly good items. Our procedure endows any ranking model with rigorous finite-sample control of the false discovery rate (FDR), regardless of the (unknown) data distribution. Moreover, our calibration algorithm enables the easy and principled integration of multiple objectives in recommender systems. As an example, we show how to optimize for recommendation diversity subject to a user-specified level of FDR control, circumventing the need to specify ad hoc weights of a diversity loss against an accuracy loss. Throughout, we focus on the problem of learning to rank a set of possible recommendations, evaluating our methods on the Yahoo! Learning to Rank and MSMarco datasets.
Modeling Content Creator Incentives on Algorithm-Curated Platforms
Jun 27, 2022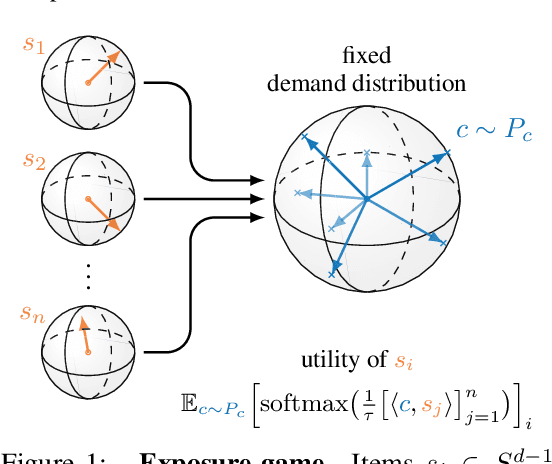

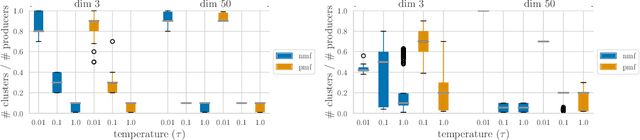
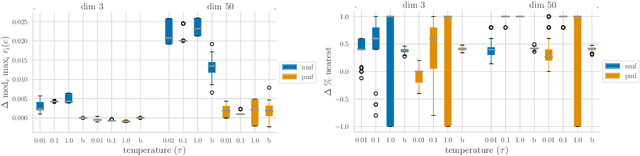
Content creators compete for user attention. Their reach crucially depends on algorithmic choices made by developers on online platforms. To maximize exposure, many creators adapt strategically, as evidenced by examples like the sprawling search engine optimization industry. This begets competition for the finite user attention pool. We formalize these dynamics in what we call an exposure game, a model of incentives induced by algorithms including modern factorization and (deep) two-tower architectures. We prove that seemingly innocuous algorithmic choices -- e.g., non-negative vs. unconstrained factorization -- significantly affect the existence and character of (Nash) equilibria in exposure games. We proffer use of creator behavior models like ours for an (ex-ante) pre-deployment audit. Such an audit can identify misalignment between desirable and incentivized content, and thus complement post-hoc measures like content filtering and moderation. To this end, we propose tools for numerically finding equilibria in exposure games, and illustrate results of an audit on the MovieLens and LastFM datasets. Among else, we find that the strategically produced content exhibits strong dependence between algorithmic exploration and content diversity, and between model expressivity and bias towards gender-based user and creator groups.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
On component interactions in two-stage recommender systems
Jun 28, 2021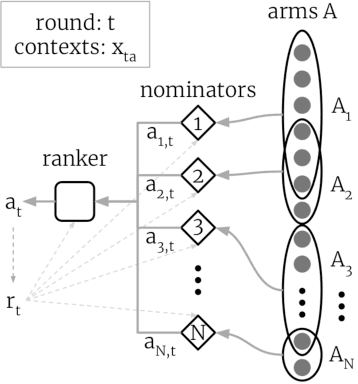

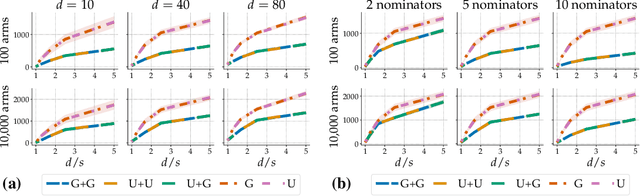
Thanks to their scalability, two-stage recommenders are used by many of today's largest online platforms, including YouTube, LinkedIn, and Pinterest. These systems produce recommendations in two steps: (i) multiple nominators -- tuned for low prediction latency -- preselect a small subset of candidates from the whole item pool; (ii)~a slower but more accurate ranker further narrows down the nominated items, and serves to the user. Despite their popularity, the literature on two-stage recommenders is relatively scarce, and the algorithms are often treated as the sum of their parts. Such treatment presupposes that the two-stage performance is explained by the behavior of individual components if they were deployed independently. This is not the case: using synthetic and real-world data, we demonstrate that interactions between the ranker and the nominators substantially affect the overall performance. Motivated by these findings, we derive a generalization lower bound which shows that careful choice of each nominator's training set is sometimes the only difference between a poor and an optimal two-stage recommender. Since searching for a good choice manually is difficult, we learn one instead. In particular, using a Mixture-of-Experts approach, we train the nominators (experts) to specialize on different subsets of the item pool. This significantly improves performance.
The Stereotyping Problem in Collaboratively Filtered Recommender Systems
Jun 23, 2021
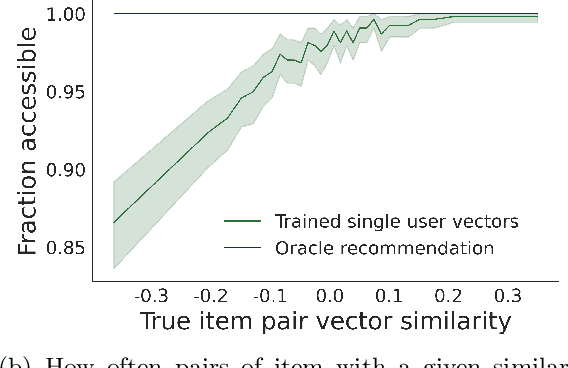

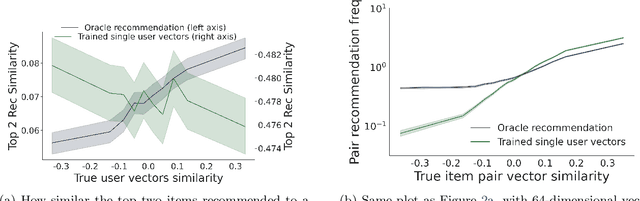
Recommender systems -- and especially matrix factorization-based collaborative filtering algorithms -- play a crucial role in mediating our access to online information. We show that such algorithms induce a particular kind of stereotyping: if preferences for a \textit{set} of items are anti-correlated in the general user population, then those items may not be recommended together to a user, regardless of that user's preferences and ratings history. First, we introduce a notion of \textit{joint accessibility}, which measures the extent to which a set of items can jointly be accessed by users. We then study joint accessibility under the standard factorization-based collaborative filtering framework, and provide theoretical necessary and sufficient conditions when joint accessibility is violated. Moreover, we show that these conditions can easily be violated when the users are represented by a single feature vector. To improve joint accessibility, we further propose an alternative modelling fix, which is designed to capture the diverse multiple interests of each user using a multi-vector representation. We conduct extensive experiments on real and simulated datasets, demonstrating the stereotyping problem with standard single-vector matrix factorization models.
Do Offline Metrics Predict Online Performance in Recommender Systems?
Nov 07, 2020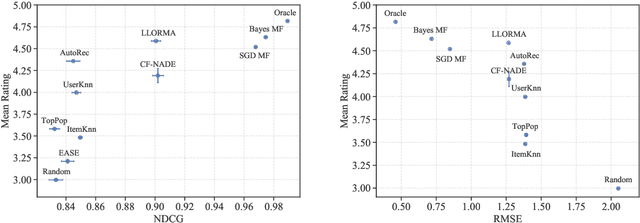
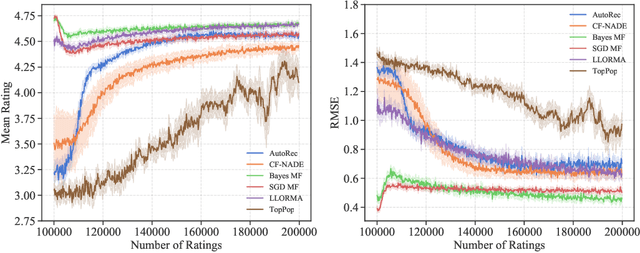
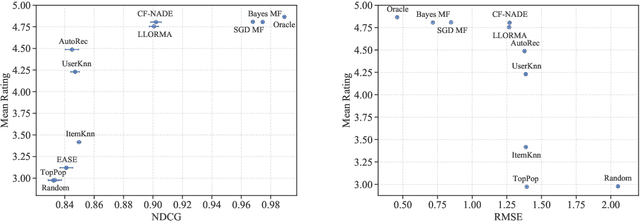
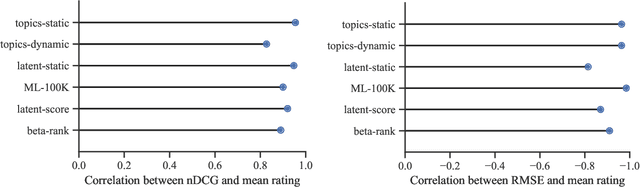
Recommender systems operate in an inherently dynamical setting. Past recommendations influence future behavior, including which data points are observed and how user preferences change. However, experimenting in production systems with real user dynamics is often infeasible, and existing simulation-based approaches have limited scale. As a result, many state-of-the-art algorithms are designed to solve supervised learning problems, and progress is judged only by offline metrics. In this work we investigate the extent to which offline metrics predict online performance by evaluating eleven recommenders across six controlled simulated environments. We observe that offline metrics are correlated with online performance over a range of environments. However, improvements in offline metrics lead to diminishing returns in online performance. Furthermore, we observe that the ranking of recommenders varies depending on the amount of initial offline data available. We study the impact of adding exploration strategies, and observe that their effectiveness, when compared to greedy recommendation, is highly dependent on the recommendation algorithm. We provide the environments and recommenders described in this paper as Reclab: an extensible ready-to-use simulation framework at https://github.com/berkeley-reclab/RecLab.
Exploration in two-stage recommender systems
Sep 01, 2020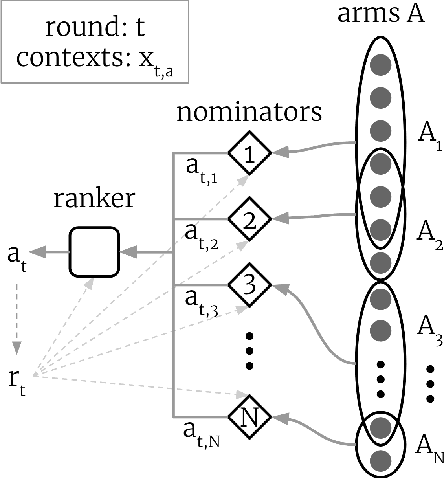
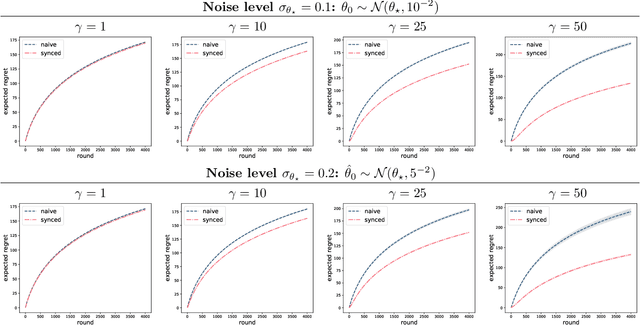
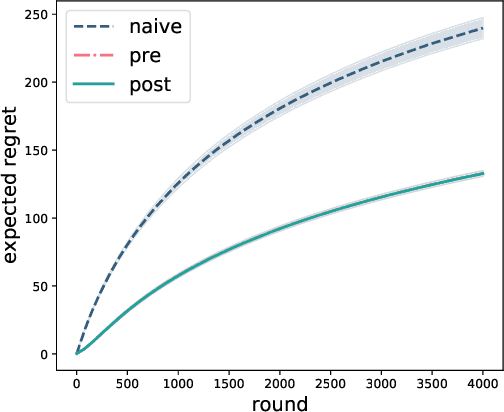
Two-stage recommender systems are widely adopted in industry due to their scalability and maintainability. These systems produce recommendations in two steps: (i) multiple nominators preselect a small number of items from a large pool using cheap-to-compute item embeddings; (ii) with a richer set of features, a ranker rearranges the nominated items and serves them to the user. A key challenge of this setup is that optimal performance of each stage in isolation does not imply optimal global performance. In response to this issue, Ma et al. (2020) proposed a nominator training objective importance weighted by the ranker's probability of recommending each item. In this work, we focus on the complementary issue of exploration. Modeled as a contextual bandit problem, we find LinUCB (a near optimal exploration strategy for single-stage systems) may lead to linear regret when deployed in two-stage recommenders. We therefore propose a method of synchronising the exploration strategies between the ranker and the nominators. Our algorithm only relies on quantities already computed by standard LinUCB at each stage and can be implemented in three lines of additional code. We end by demonstrating the effectiveness of our algorithm experimentally.
The Effect of Natural Distribution Shift on Question Answering Models
Apr 29, 2020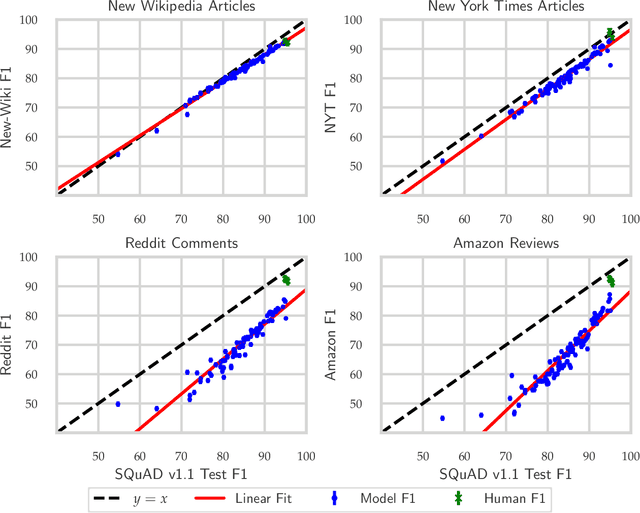
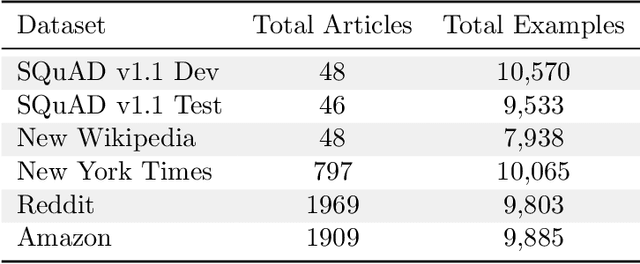

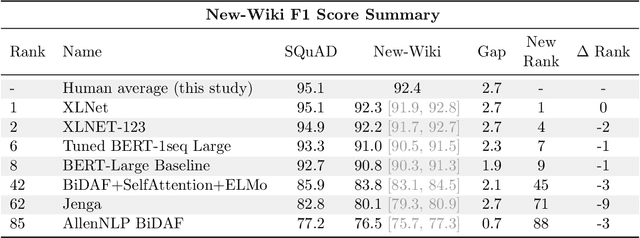
We build four new test sets for the Stanford Question Answering Dataset (SQuAD) and evaluate the ability of question-answering systems to generalize to new data. Our first test set is from the original Wikipedia domain and measures the extent to which existing systems overfit the original test set. Despite several years of heavy test set re-use, we find no evidence of adaptive overfitting. The remaining three test sets are constructed from New York Times articles, Reddit posts, and Amazon product reviews and measure robustness to natural distribution shifts. Across a broad range of models, we observe average performance drops of 3.8, 14.0, and 17.4 F1 points, respectively. In contrast, a strong human baseline matches or exceeds the performance of SQuAD models on the original domain and exhibits little to no drop in new domains. Taken together, our results confirm the surprising resilience of the holdout method and emphasize the need to move towards evaluation metrics that incorporate robustness to natural distribution shifts.