 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn component interactions in two-stage recommender systems
Paper and Code
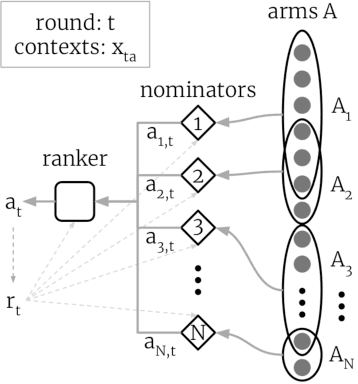

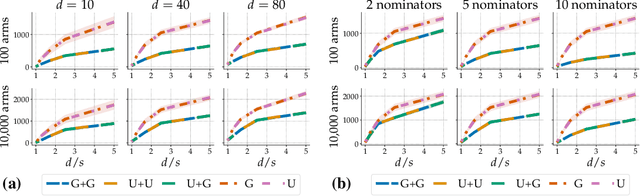
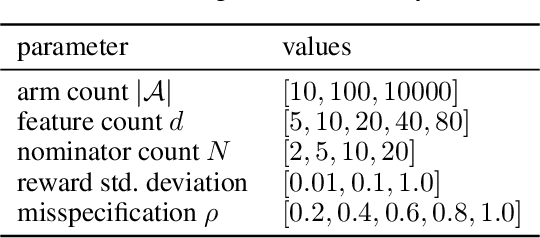
Thanks to their scalability, two-stage recommenders are used by many of today's largest online platforms, including YouTube, LinkedIn, and Pinterest. These systems produce recommendations in two steps: (i) multiple nominators -- tuned for low prediction latency -- preselect a small subset of candidates from the whole item pool; (ii)~a slower but more accurate ranker further narrows down the nominated items, and serves to the user. Despite their popularity, the literature on two-stage recommenders is relatively scarce, and the algorithms are often treated as the sum of their parts. Such treatment presupposes that the two-stage performance is explained by the behavior of individual components if they were deployed independently. This is not the case: using synthetic and real-world data, we demonstrate that interactions between the ranker and the nominators substantially affect the overall performance. Motivated by these findings, we derive a generalization lower bound which shows that careful choice of each nominator's training set is sometimes the only difference between a poor and an optimal two-stage recommender. Since searching for a good choice manually is difficult, we learn one instead. In particular, using a Mixture-of-Experts approach, we train the nominators (experts) to specialize on different subsets of the item pool. This significantly improves performance.