 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Language Models on the Knowledge Graph: Insights on Hallucinations and Their Detectability
Aug 14, 2024



While many capabilities of language models (LMs) improve with increased training budget, the influence of scale on hallucinations is not yet fully understood. Hallucinations come in many forms, and there is no universally accepted definition. We thus focus on studying only those hallucinations where a correct answer appears verbatim in the training set. To fully control the training data content, we construct a knowledge graph (KG)-based dataset, and use it to train a set of increasingly large LMs. We find that for a fixed dataset, larger and longer-trained LMs hallucinate less. However, hallucinating on $\leq5$% of the training data requires an order of magnitude larger model, and thus an order of magnitude more compute, than Hoffmann et al. (2022) reported was optimal. Given this costliness, we study how hallucination detectors depend on scale. While we see detector size improves performance on fixed LM's outputs, we find an inverse relationship between the scale of the LM and the detectability of its hallucinations.
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
Dec 22, 2023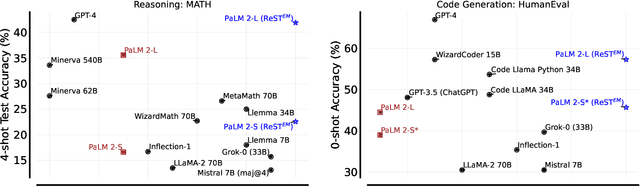
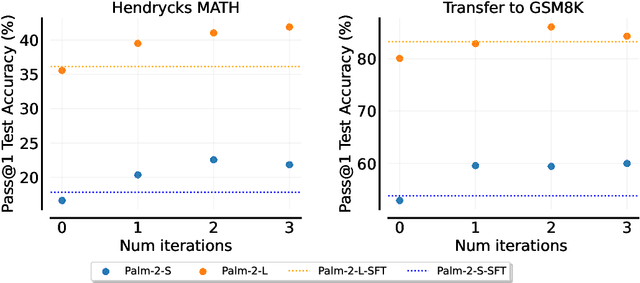
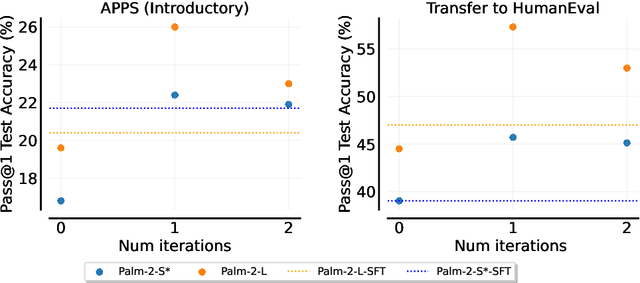
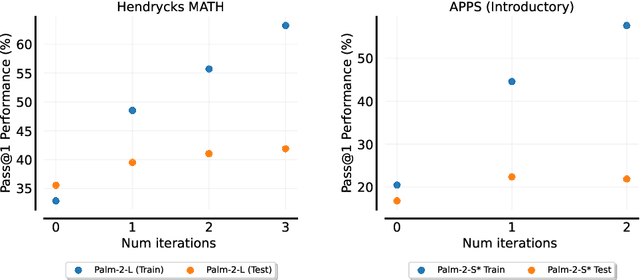
Fine-tuning language models~(LMs) on human-generated data remains a prevalent practice. However, the performance of such models is often limited by the quantity and diversity of high-quality human data. In this paper, we explore whether we can go beyond human data on tasks where we have access to scalar feedback, for example, on math problems where one can verify correctness. To do so, we investigate a simple self-training method based on expectation-maximization, which we call ReST$^{EM}$, where we (1) generate samples from the model and filter them using binary feedback, (2) fine-tune the model on these samples, and (3) repeat this process a few times. Testing on advanced MATH reasoning and APPS coding benchmarks using PaLM-2 models, we find that ReST$^{EM}$ scales favorably with model size and significantly surpasses fine-tuning only on human data. Overall, our findings suggest self-training with feedback can substantially reduce dependence on human-generated data.
Optimising Human-Machine Collaboration for Efficient High-Precision Information Extraction from Text Documents
Feb 18, 2023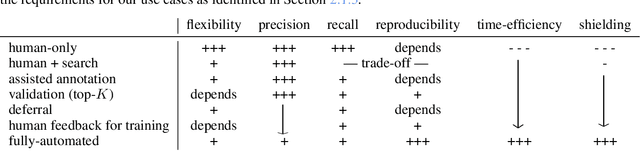
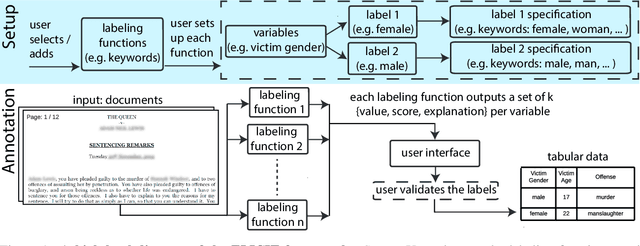
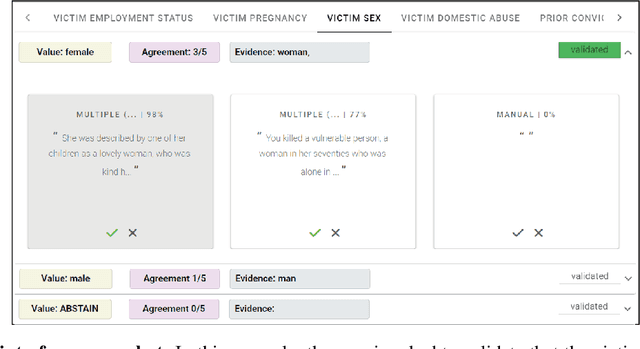
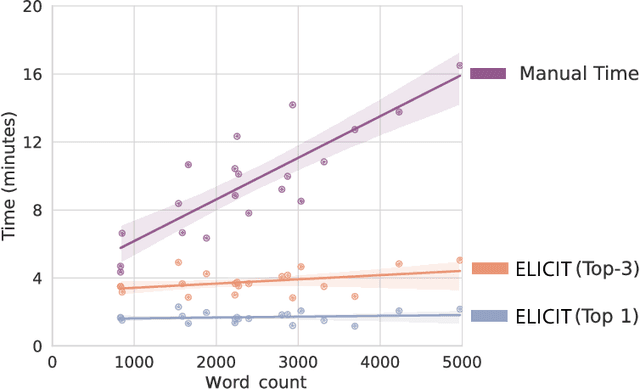
While humans can extract information from unstructured text with high precision and recall, this is often too time-consuming to be practical. Automated approaches, on the other hand, produce nearly-immediate results, but may not be reliable enough for high-stakes applications where precision is essential. In this work, we consider the benefits and drawbacks of various human-only, human-machine, and machine-only information extraction approaches. We argue for the utility of a human-in-the-loop approach in applications where high precision is required, but purely manual extraction is infeasible. We present a framework and an accompanying tool for information extraction using weak-supervision labelling with human validation. We demonstrate our approach on three criminal justice datasets. We find that the combination of computer speed and human understanding yields precision comparable to manual annotation while requiring only a fraction of time, and significantly outperforms fully automated baselines in terms of precision.
Modeling Content Creator Incentives on Algorithm-Curated Platforms
Jun 27, 2022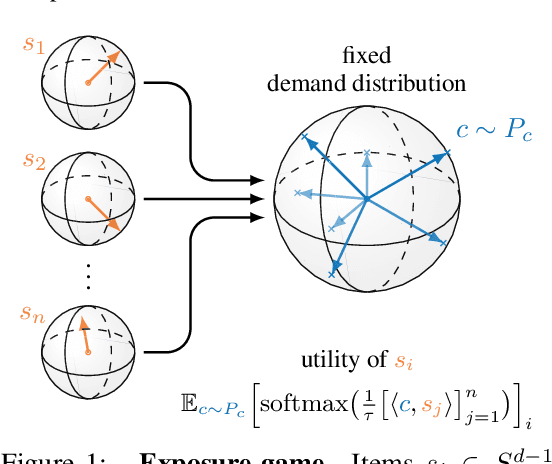

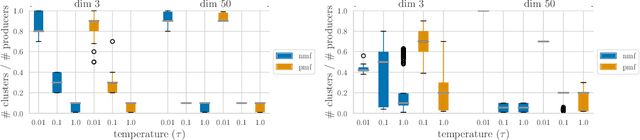
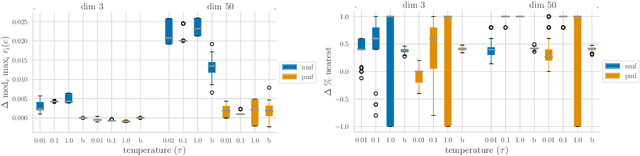
Content creators compete for user attention. Their reach crucially depends on algorithmic choices made by developers on online platforms. To maximize exposure, many creators adapt strategically, as evidenced by examples like the sprawling search engine optimization industry. This begets competition for the finite user attention pool. We formalize these dynamics in what we call an exposure game, a model of incentives induced by algorithms including modern factorization and (deep) two-tower architectures. We prove that seemingly innocuous algorithmic choices -- e.g., non-negative vs. unconstrained factorization -- significantly affect the existence and character of (Nash) equilibria in exposure games. We proffer use of creator behavior models like ours for an (ex-ante) pre-deployment audit. Such an audit can identify misalignment between desirable and incentivized content, and thus complement post-hoc measures like content filtering and moderation. To this end, we propose tools for numerically finding equilibria in exposure games, and illustrate results of an audit on the MovieLens and LastFM datasets. Among else, we find that the strategically produced content exhibits strong dependence between algorithmic exploration and content diversity, and between model expressivity and bias towards gender-based user and creator groups.
Wide Bayesian neural networks have a simple weight posterior: theory and accelerated sampling
Jun 15, 2022

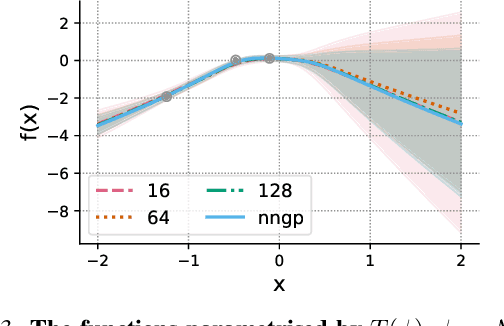
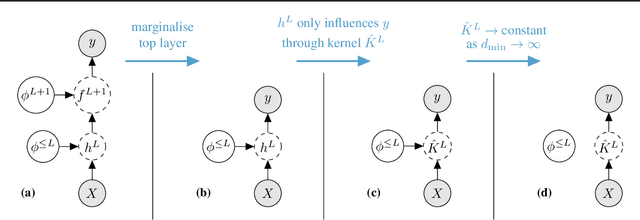
We introduce repriorisation, a data-dependent reparameterisation which transforms a Bayesian neural network (BNN) posterior to a distribution whose KL divergence to the BNN prior vanishes as layer widths grow. The repriorisation map acts directly on parameters, and its analytic simplicity complements the known neural network Gaussian process (NNGP) behaviour of wide BNNs in function space. Exploiting the repriorisation, we develop a Markov chain Monte Carlo (MCMC) posterior sampling algorithm which mixes faster the wider the BNN. This contrasts with the typically poor performance of MCMC in high dimensions. We observe up to 50x higher effective sample size relative to no reparametrisation for both fully-connected and residual networks. Improvements are achieved at all widths, with the margin between reparametrised and standard BNNs growing with layer width.
On component interactions in two-stage recommender systems
Jun 28, 2021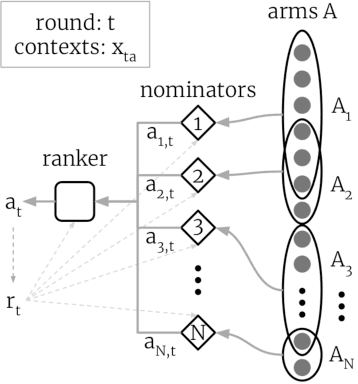

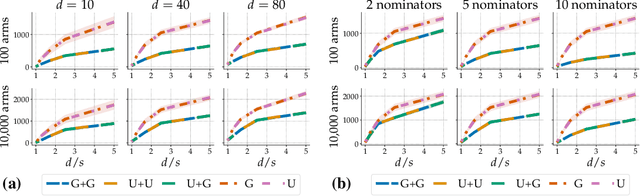
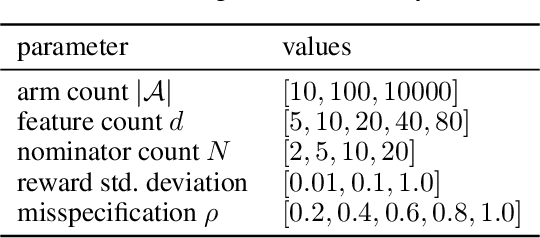
Thanks to their scalability, two-stage recommenders are used by many of today's largest online platforms, including YouTube, LinkedIn, and Pinterest. These systems produce recommendations in two steps: (i) multiple nominators -- tuned for low prediction latency -- preselect a small subset of candidates from the whole item pool; (ii)~a slower but more accurate ranker further narrows down the nominated items, and serves to the user. Despite their popularity, the literature on two-stage recommenders is relatively scarce, and the algorithms are often treated as the sum of their parts. Such treatment presupposes that the two-stage performance is explained by the behavior of individual components if they were deployed independently. This is not the case: using synthetic and real-world data, we demonstrate that interactions between the ranker and the nominators substantially affect the overall performance. Motivated by these findings, we derive a generalization lower bound which shows that careful choice of each nominator's training set is sometimes the only difference between a poor and an optimal two-stage recommender. Since searching for a good choice manually is difficult, we learn one instead. In particular, using a Mixture-of-Experts approach, we train the nominators (experts) to specialize on different subsets of the item pool. This significantly improves performance.
Exploration in two-stage recommender systems
Sep 01, 2020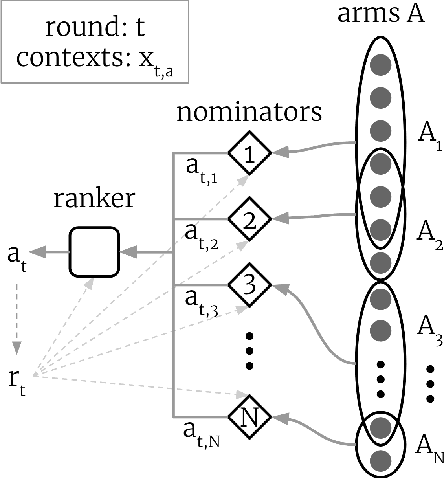
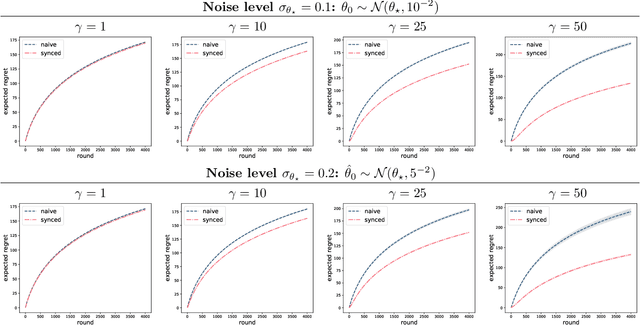
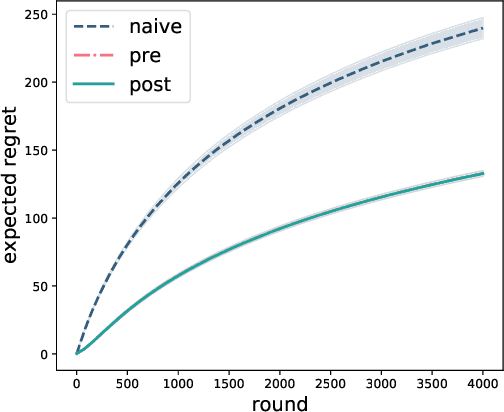
Two-stage recommender systems are widely adopted in industry due to their scalability and maintainability. These systems produce recommendations in two steps: (i) multiple nominators preselect a small number of items from a large pool using cheap-to-compute item embeddings; (ii) with a richer set of features, a ranker rearranges the nominated items and serves them to the user. A key challenge of this setup is that optimal performance of each stage in isolation does not imply optimal global performance. In response to this issue, Ma et al. (2020) proposed a nominator training objective importance weighted by the ranker's probability of recommending each item. In this work, we focus on the complementary issue of exploration. Modeled as a contextual bandit problem, we find LinUCB (a near optimal exploration strategy for single-stage systems) may lead to linear regret when deployed in two-stage recommenders. We therefore propose a method of synchronising the exploration strategies between the ranker and the nominators. Our algorithm only relies on quantities already computed by standard LinUCB at each stage and can be implemented in three lines of additional code. We end by demonstrating the effectiveness of our algorithm experimentally.
Exact posterior distributions of wide Bayesian neural networks
Jun 18, 2020
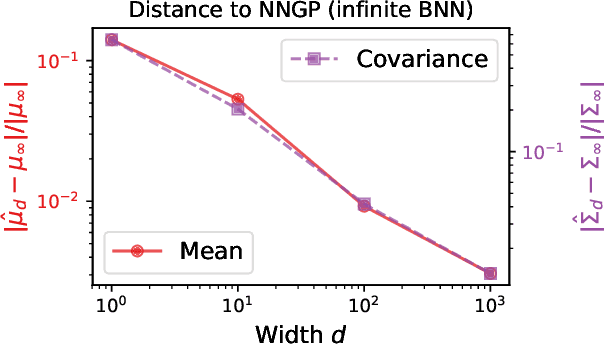
Recent work has shown that the prior over functions induced by a deep Bayesian neural network (BNN) behaves as a Gaussian process (GP) as the width of all layers becomes large. However, many BNN applications are concerned with the BNN function space posterior. While some empirical evidence of the posterior convergence was provided in the original works of Neal (1996) and Matthews et al. (2018), it is limited to small datasets or architectures due to the notorious difficulty of obtaining and verifying exactness of BNN posterior approximations. We provide the missing theoretical proof that the exact BNN posterior converges (weakly) to the one induced by the GP limit of the prior. For empirical validation, we show how to generate exact samples from a finite BNN on a small dataset via rejection sampling.
Infinite attention: NNGP and NTK for deep attention networks
Jun 18, 2020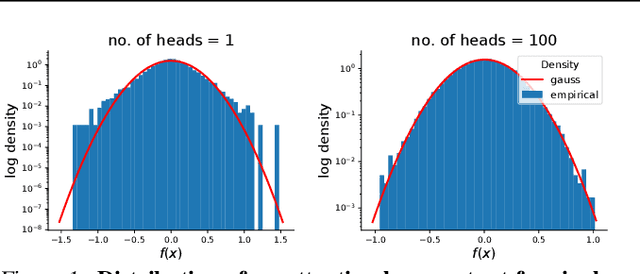

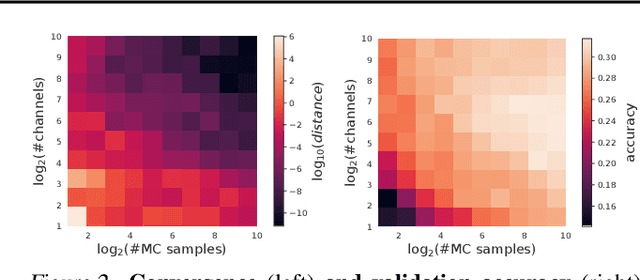

There is a growing amount of literature on the relationship between wide neural networks (NNs) and Gaussian processes (GPs), identifying an equivalence between the two for a variety of NN architectures. This equivalence enables, for instance, accurate approximation of the behaviour of wide Bayesian NNs without MCMC or variational approximations, or characterisation of the distribution of randomly initialised wide NNs optimised by gradient descent without ever running an optimiser. We provide a rigorous extension of these results to NNs involving attention layers, showing that unlike single-head attention, which induces non-Gaussian behaviour, multi-head attention architectures behave as GPs as the number of heads tends to infinity. We further discuss the effects of positional encodings and layer normalisation, and propose modifications of the attention mechanism which lead to improved results for both finite and infinitely wide NNs. We evaluate attention kernels empirically, leading to a moderate improvement upon the previous state-of-the-art on CIFAR-10 for GPs without trainable kernels and advanced data preprocessing. Finally, we introduce new features to the Neural Tangents library (Novak et al., 2020) allowing applications of NNGP/NTK models, with and without attention, to variable-length sequences, with an example on the IMDb reviews dataset.
Neural Tangents: Fast and Easy Infinite Neural Networks in Python
Dec 05, 2019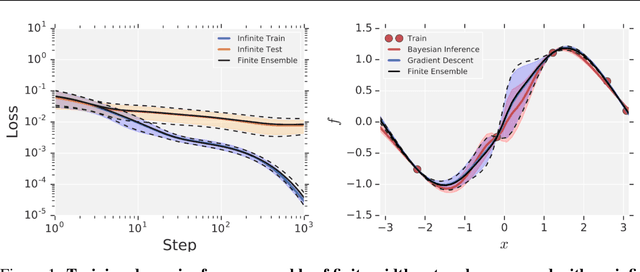
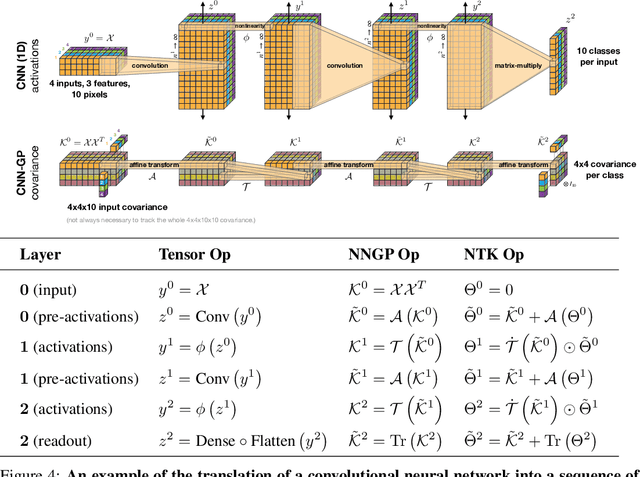

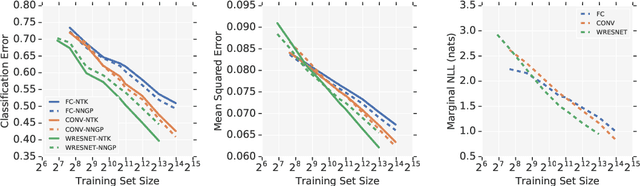
Neural Tangents is a library designed to enable research into infinite-width neural networks. It provides a high-level API for specifying complex and hierarchical neural network architectures. These networks can then be trained and evaluated either at finite-width as usual or in their infinite-width limit. Infinite-width networks can be trained analytically using exact Bayesian inference or using gradient descent via the Neural Tangent Kernel. Additionally, Neural Tangents provides tools to study gradient descent training dynamics of wide but finite networks in either function space or weight space. The entire library runs out-of-the-box on CPU, GPU, or TPU. All computations can be automatically distributed over multiple accelerators with near-linear scaling in the number of devices. Neural Tangents is available at www.github.com/google/neural-tangents. We also provide an accompanying interactive Colab notebook.