 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-enhanced conversational agents for personalized asthma support Factors for engagement, value and efficacy
Jul 22, 2025Asthma-related deaths in the UK are the highest in Europe, and only 30% of patients access basic care. There is a need for alternative approaches to reaching people with asthma in order to provide health education, self-management support and bridges to care. Automated conversational agents (specifically, mobile chatbots) present opportunities for providing alternative and individually tailored access to health education, self-management support and risk self-assessment. But would patients engage with a chatbot, and what factors influence engagement? We present results from a patient survey (N=1257) devised by a team of asthma clinicians, patients, and technology developers, conducted to identify optimal factors for efficacy, value and engagement for a chatbot. Results indicate that most adults with asthma (53%) are interested in using a chatbot and the patients most likely to do so are those who believe their asthma is more serious and who are less confident about self-management. Results also indicate enthusiasm for 24/7 access, personalisation, and for WhatsApp as the preferred access method (compared to app, voice assistant, SMS or website). Obstacles to uptake include security/privacy concerns and skepticism of technological capabilities. We present detailed findings and consolidate these into 7 recommendations for developers for optimising efficacy of chatbot-based health support.
Optimising Human-Machine Collaboration for Efficient High-Precision Information Extraction from Text Documents
Feb 18, 2023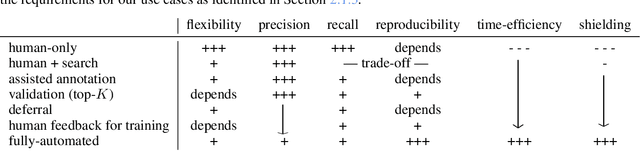
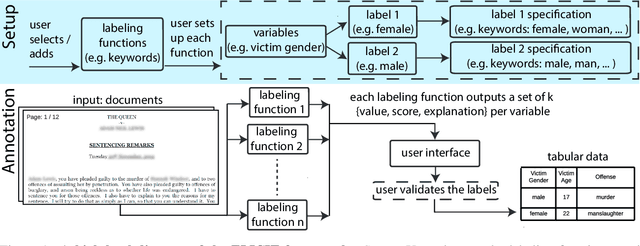
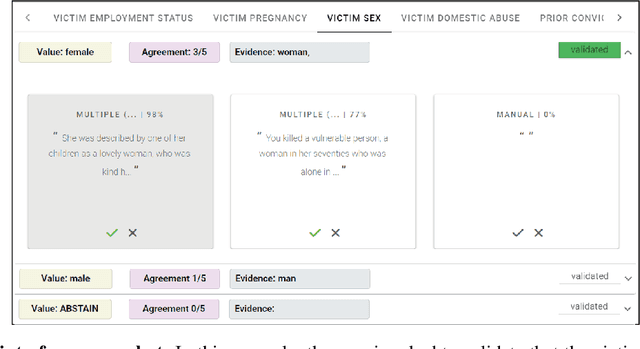
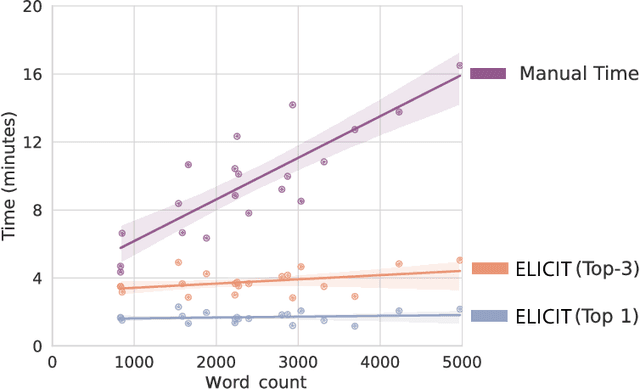
While humans can extract information from unstructured text with high precision and recall, this is often too time-consuming to be practical. Automated approaches, on the other hand, produce nearly-immediate results, but may not be reliable enough for high-stakes applications where precision is essential. In this work, we consider the benefits and drawbacks of various human-only, human-machine, and machine-only information extraction approaches. We argue for the utility of a human-in-the-loop approach in applications where high precision is required, but purely manual extraction is infeasible. We present a framework and an accompanying tool for information extraction using weak-supervision labelling with human validation. We demonstrate our approach on three criminal justice datasets. We find that the combination of computer speed and human understanding yields precision comparable to manual annotation while requiring only a fraction of time, and significantly outperforms fully automated baselines in terms of precision.
Can We Automate the Analysis of Online Child Sexual Exploitation Discourse?
Sep 25, 2022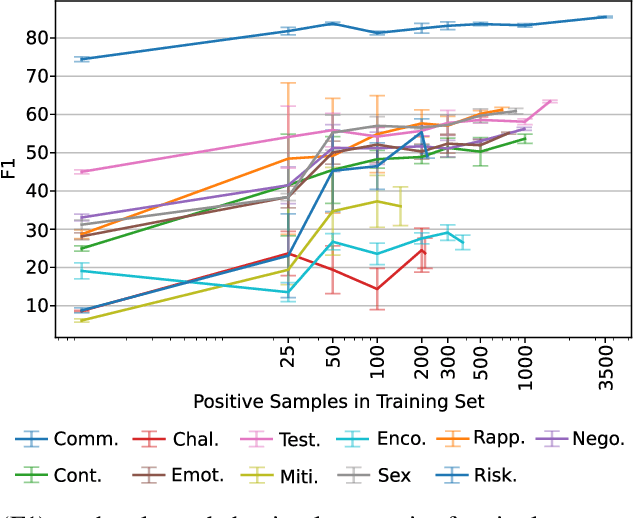

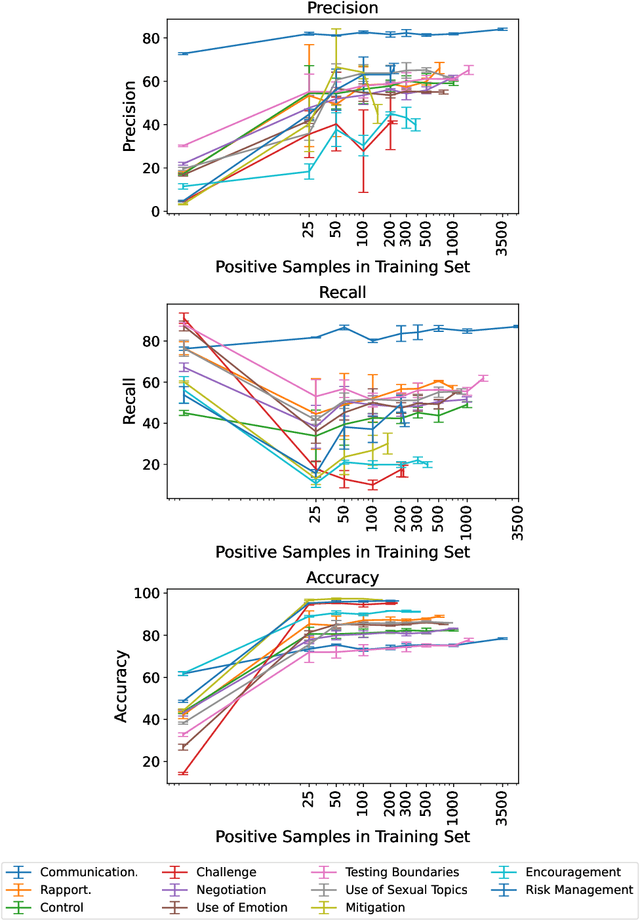
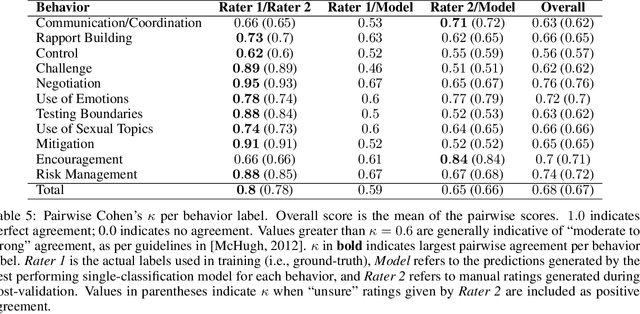
Social media's growing popularity raises concerns around children's online safety. Interactions between minors and adults with predatory intentions is a particularly grave concern. Research into online sexual grooming has often relied on domain experts to manually annotate conversations, limiting both scale and scope. In this work, we test how well-automated methods can detect conversational behaviors and replace an expert human annotator. Informed by psychological theories of online grooming, we label $6772$ chat messages sent by child-sex offenders with one of eleven predatory behaviors. We train bag-of-words and natural language inference models to classify each behavior, and show that the best performing models classify behaviors in a manner that is consistent, but not on-par, with human annotation.