 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecise Length Control in Large Language Models
Dec 16, 2024
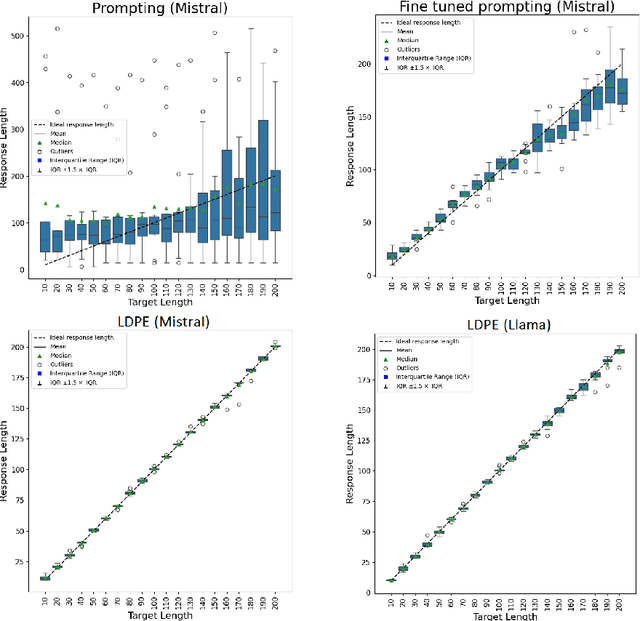


Large Language Models (LLMs) are increasingly used in production systems, powering applications such as chatbots, summarization, and question answering. Despite their success, controlling the length of their response remains a significant challenge, particularly for tasks requiring structured outputs or specific levels of detail. In this work, we propose a method to adapt pre-trained decoder-only LLMs for precise control of response length. Our approach incorporates a secondary length-difference positional encoding (LDPE) into the input embeddings, which counts down to a user-set response termination length. Fine-tuning with LDPE allows the model to learn to terminate responses coherently at the desired length, achieving mean token errors of less than 3 tokens. We also introduce Max New Tokens++, an extension that enables flexible upper-bound length control, rather than an exact target. Experimental results on tasks such as question answering and document summarization demonstrate that our method enables precise length control without compromising response quality.
Aligning Large Language Models with Counterfactual DPO
Jan 19, 2024Advancements in large language models (LLMs) have demonstrated remarkable capabilities across a diverse range of applications. These models excel in generating text completions that are contextually coherent and cover an extensive array of subjects. However, the vast datasets required for their training make aligning response styles during the pretraining and instruction tuning phases challenging. Consequently, an additional alignment phase is typically employed, wherein the model is further trained with human preference data to better align its outputs with human expectations. While this process doesn't introduce new capabilities per se, it does accentuate generation styles innate to the model. This paper explores the utilization of counterfactual prompting within the framework of Direct Preference Optimization (DPO) to align the model's style without relying on human intervention. We demonstrate that this method effectively instils desirable behaviour, mitigates undesirable ones, and encourages the model to disregard inappropriate instructions. Our findings suggest that counterfactual prompting with DPO presents a low-resource way to fine-tune LLMs to meet the demands for responsible and ethically aligned AI systems.
Optimising Human-Machine Collaboration for Efficient High-Precision Information Extraction from Text Documents
Feb 18, 2023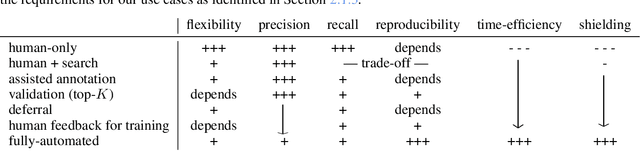
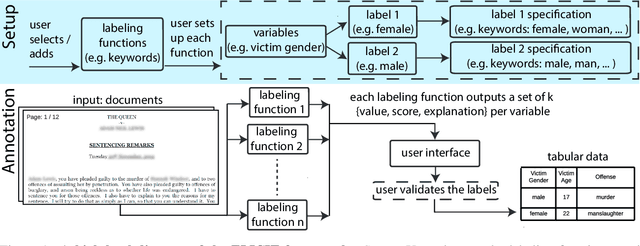
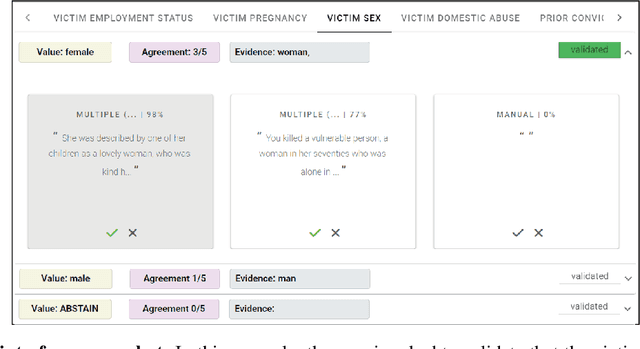
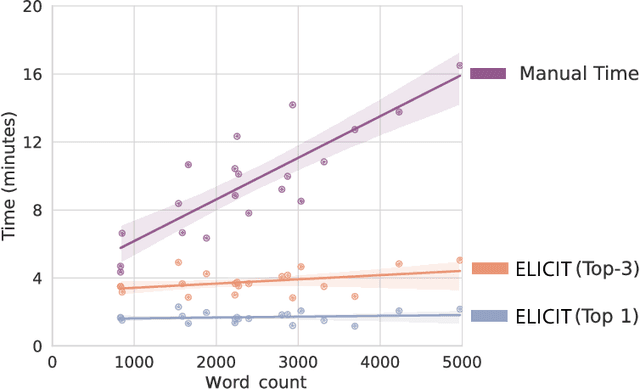
While humans can extract information from unstructured text with high precision and recall, this is often too time-consuming to be practical. Automated approaches, on the other hand, produce nearly-immediate results, but may not be reliable enough for high-stakes applications where precision is essential. In this work, we consider the benefits and drawbacks of various human-only, human-machine, and machine-only information extraction approaches. We argue for the utility of a human-in-the-loop approach in applications where high precision is required, but purely manual extraction is infeasible. We present a framework and an accompanying tool for information extraction using weak-supervision labelling with human validation. We demonstrate our approach on three criminal justice datasets. We find that the combination of computer speed and human understanding yields precision comparable to manual annotation while requiring only a fraction of time, and significantly outperforms fully automated baselines in terms of precision.
Causal datasheet: An approximate guide to practically assess Bayesian networks in the real world
Mar 12, 2020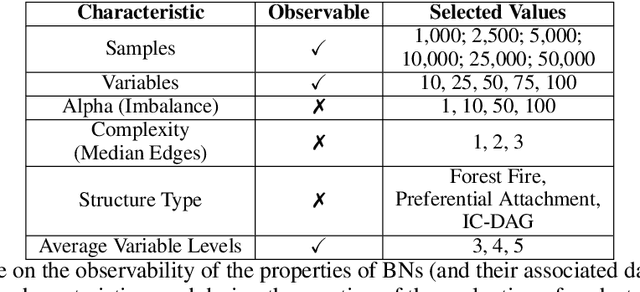
In solving real-world problems like changing healthcare-seeking behaviors, designing interventions to improve downstream outcomes requires an understanding of the causal links within the system. Causal Bayesian Networks (BN) have been proposed as one such powerful method. In real-world applications, however, confidence in the results of BNs are often moderate at best. This is due in part to the inability to validate against some ground truth, as the DAG is not available. This is especially problematic if the learned DAG conflicts with pre-existing domain doctrine. At the policy level, one must justify insights generated by such analysis, preferably accompanying them with uncertainty estimation. Here we propose a causal extension to the datasheet concept proposed by Gebru et al (2018) to include approximate BN performance expectations for any given dataset. To generate the results for a prototype Causal Datasheet, we constructed over 30,000 synthetic datasets with properties mirroring characteristics of real data. We then recorded the results given by state-of-the-art structure learning algorithms. These results were used to populate the Causal Datasheet, and recommendations were automatically generated dependent on expected performance. As a proof of concept, we used our Causal Datasheet Generation Tool (CDG-T) to assign expected performance expectations to a maternal health survey we conducted in Uttar Pradesh, India.