 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal datasheet: An approximate guide to practically assess Bayesian networks in the real world
Mar 12, 2020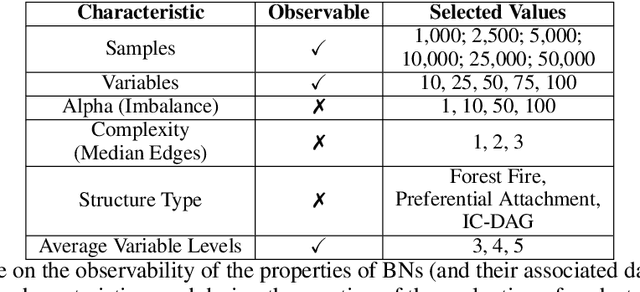
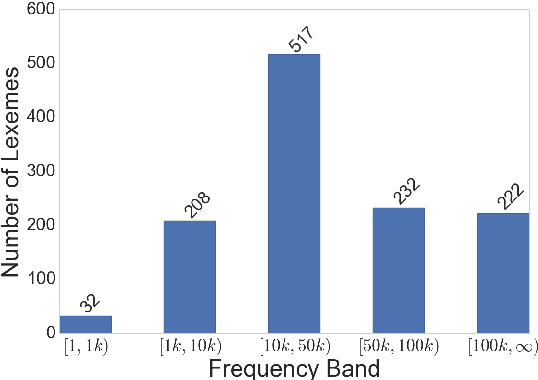
In solving real-world problems like changing healthcare-seeking behaviors, designing interventions to improve downstream outcomes requires an understanding of the causal links within the system. Causal Bayesian Networks (BN) have been proposed as one such powerful method. In real-world applications, however, confidence in the results of BNs are often moderate at best. This is due in part to the inability to validate against some ground truth, as the DAG is not available. This is especially problematic if the learned DAG conflicts with pre-existing domain doctrine. At the policy level, one must justify insights generated by such analysis, preferably accompanying them with uncertainty estimation. Here we propose a causal extension to the datasheet concept proposed by Gebru et al (2018) to include approximate BN performance expectations for any given dataset. To generate the results for a prototype Causal Datasheet, we constructed over 30,000 synthetic datasets with properties mirroring characteristics of real data. We then recorded the results given by state-of-the-art structure learning algorithms. These results were used to populate the Causal Datasheet, and recommendations were automatically generated dependent on expected performance. As a proof of concept, we used our Causal Datasheet Generation Tool (CDG-T) to assign expected performance expectations to a maternal health survey we conducted in Uttar Pradesh, India.
Improving Semantic Composition with Offset Inference
Apr 21, 2017
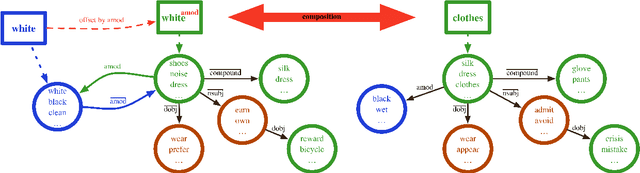

Count-based distributional semantic models suffer from sparsity due to unobserved but plausible co-occurrences in any text collection. This problem is amplified for models like Anchored Packed Trees (APTs), that take the grammatical type of a co-occurrence into account. We therefore introduce a novel form of distributional inference that exploits the rich type structure in APTs and infers missing data by the same mechanism that is used for semantic composition.
One Representation per Word - Does it make Sense for Composition?
Feb 22, 2017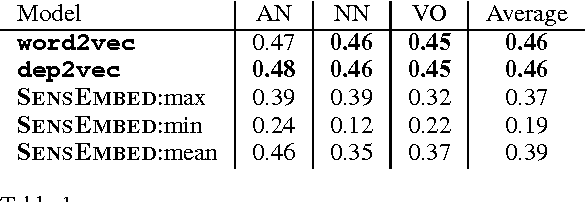

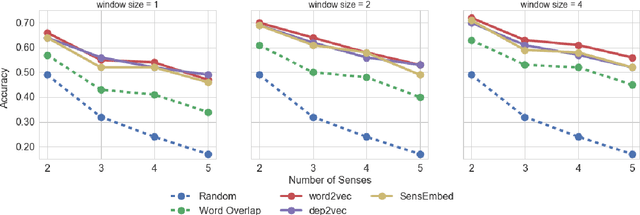
In this paper, we investigate whether an a priori disambiguation of word senses is strictly necessary or whether the meaning of a word in context can be disambiguated through composition alone. We evaluate the performance of off-the-shelf single-vector and multi-sense vector models on a benchmark phrase similarity task and a novel task for word-sense discrimination. We find that single-sense vector models perform as well or better than multi-sense vector models despite arguably less clean elementary representations. Our findings furthermore show that simple composition functions such as pointwise addition are able to recover sense specific information from a single-sense vector model remarkably well.
Aligning Packed Dependency Trees: a theory of composition for distributional semantics
Aug 25, 2016We present a new framework for compositional distributional semantics in which the distributional contexts of lexemes are expressed in terms of anchored packed dependency trees. We show that these structures have the potential to capture the full sentential contexts of a lexeme and provide a uniform basis for the composition of distributional knowledge in a way that captures both mutual disambiguation and generalization.
Improving Sparse Word Representations with Distributional Inference for Semantic Composition
Aug 24, 2016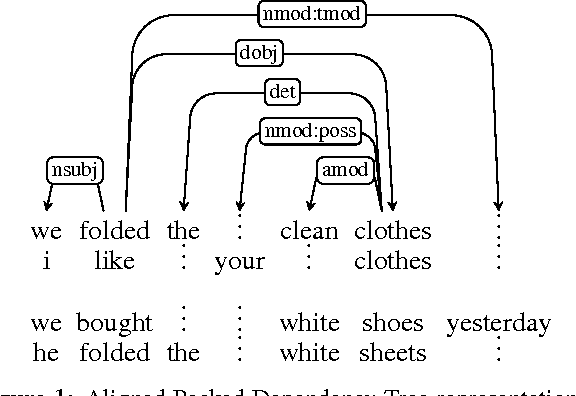


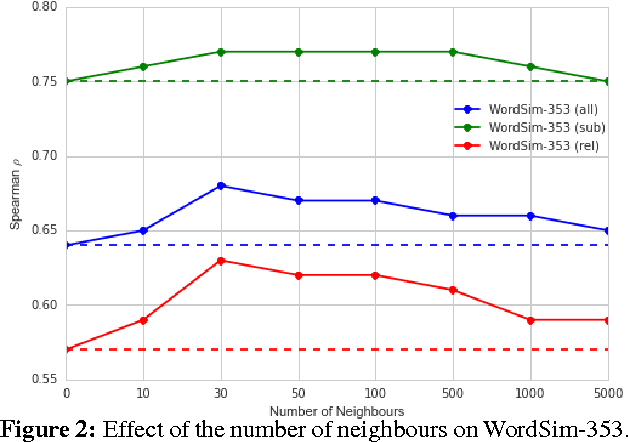
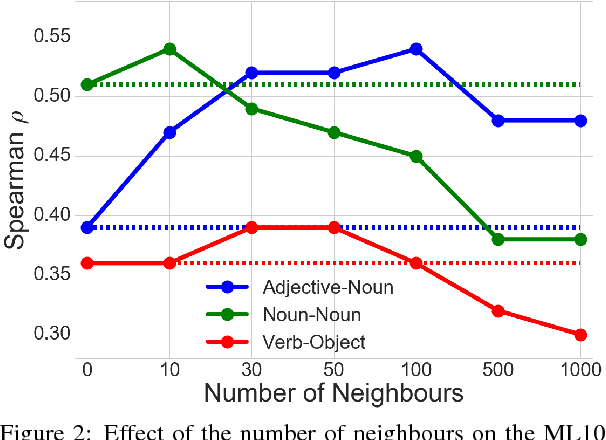
Distributional models are derived from co-occurrences in a corpus, where only a small proportion of all possible plausible co-occurrences will be observed. This results in a very sparse vector space, requiring a mechanism for inferring missing knowledge. Most methods face this challenge in ways that render the resulting word representations uninterpretable, with the consequence that semantic composition becomes hard to model. In this paper we explore an alternative which involves explicitly inferring unobserved co-occurrences using the distributional neighbourhood. We show that distributional inference improves sparse word representations on several word similarity benchmarks and demonstrate that our model is competitive with the state-of-the-art for adjective-noun, noun-noun and verb-object compositions while being fully interpretable.