 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtein sequence classification using natural language processing techniques
Sep 06, 2024Proteins are essential to numerous biological functions, with their sequences determining their roles within organisms. Traditional methods for determining protein function are time-consuming and labor-intensive. This study addresses the increasing demand for precise, effective, and automated protein sequence classification methods by employing natural language processing (NLP) techniques on a dataset comprising 75 target protein classes. We explored various machine learning and deep learning models, including K-Nearest Neighbors (KNN), Multinomial Na\"ive Bayes, Logistic Regression, Multi-Layer Perceptron (MLP), Decision Tree, Random Forest, XGBoost, Voting and Stacking classifiers, Convolutional Neural Network (CNN), Long Short-Term Memory (LSTM), and transformer models (BertForSequenceClassification, DistilBERT, and ProtBert). Experiments were conducted using amino acid ranges of 1-4 grams for machine learning models and different sequence lengths for CNN and LSTM models. The KNN algorithm performed best on tri-gram data with 70.0% accuracy and a macro F1 score of 63.0%. The Voting classifier achieved best performance with 74.0% accuracy and an F1 score of 65.0%, while the Stacking classifier reached 75.0% accuracy and an F1 score of 64.0%. ProtBert demonstrated the highest performance among transformer models, with a accuracy 76.0% and F1 score 61.0% which is same for all three transformer models. Advanced NLP techniques, particularly ensemble methods and transformer models, show great potential in protein classification. Our results demonstrate that ensemble methods, particularly Voting Soft classifiers, achieved superior results, highlighting the importance of sufficient training data and addressing sequence similarity across different classes.
Automated Query Generation for Evidence Collection from Web Search Engines
Mar 15, 2023



It is widely accepted that so-called facts can be checked by searching for information on the Internet. This process requires a fact-checker to formulate a search query based on the fact and to present it to a search engine. Then, relevant and believable passages need to be identified in the search results before a decision is made. This process is carried out by sub-editors at many news and media organisations on a daily basis. Here, we ask the question as to whether it is possible to automate the first step, that of query generation. Can we automatically formulate search queries based on factual statements which are similar to those formulated by human experts? Here, we consider similarity both in terms of textual similarity and with respect to relevant documents being returned by a search engine. First, we introduce a moderate-sized evidence collection dataset which includes 390 factual statements together with associated human-generated search queries and search results. Then, we investigate generating queries using a number of rule-based and automatic text generation methods based on pre-trained large language models (LLMs). We show that these methods have different merits and propose a hybrid approach which has superior performance in practice.
Automatic Scoring of Dream Reports' Emotional Content with Large Language Models
Feb 28, 2023In the field of dream research, the study of dream content typically relies on the analysis of verbal reports provided by dreamers upon awakening from their sleep. This task is classically performed through manual scoring provided by trained annotators, at a great time expense. While a consistent body of work suggests that natural language processing (NLP) tools can support the automatic analysis of dream reports, proposed methods lacked the ability to reason over a report's full context and required extensive data pre-processing. Furthermore, in most cases, these methods were not validated against standard manual scoring approaches. In this work, we address these limitations by adopting large language models (LLMs) to study and replicate the manual annotation of dream reports, using a mixture of off-the-shelf and bespoke approaches, with a focus on references to reports' emotions. Our results show that the off-the-shelf method achieves a low performance probably in light of inherent linguistic differences between reports collected in different (groups of) individuals. On the other hand, the proposed bespoke text classification method achieves a high performance, which is robust against potential biases. Overall, these observations indicate that our approach could find application in the analysis of large dream datasets and may favour reproducibility and comparability of results across studies.
Towards Structure-aware Paraphrase Identification with Phrase Alignment Using Sentence Encoders
Oct 11, 2022

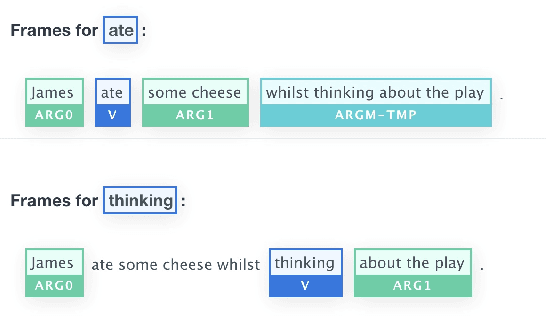
Previous works have demonstrated the effectiveness of utilising pre-trained sentence encoders based on their sentence representations for meaning comparison tasks. Though such representations are shown to capture hidden syntax structures, the direct similarity comparison between them exhibits weak sensitivity to word order and structural differences in given sentences. A single similarity score further makes the comparison process hard to interpret. Therefore, we here propose to combine sentence encoders with an alignment component by representing each sentence as a list of predicate-argument spans (where their span representations are derived from sentence encoders), and decomposing the sentence-level meaning comparison into the alignment between their spans for paraphrase identification tasks. Empirical results show that the alignment component brings in both improved performance and interpretability for various sentence encoders. After closer investigation, the proposed approach indicates increased sensitivity to structural difference and enhanced ability to distinguish non-paraphrases with high lexical overlap.
Representing Syntax and Composition with Geometric Transformations
Jun 03, 2021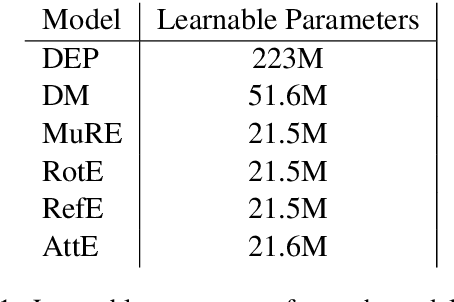
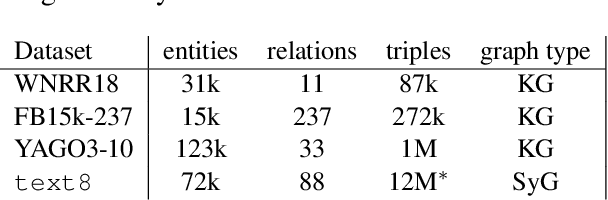
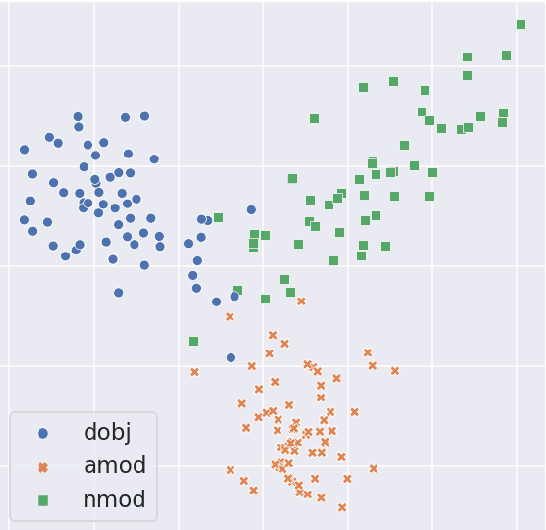
The exploitation of syntactic graphs (SyGs) as a word's context has been shown to be beneficial for distributional semantic models (DSMs), both at the level of individual word representations and in deriving phrasal representations via composition. However, notwithstanding the potential performance benefit, the syntactically-aware DSMs proposed to date have huge numbers of parameters (compared to conventional DSMs) and suffer from data sparsity. Furthermore, the encoding of the SyG links (i.e., the syntactic relations) has been largely limited to linear maps. The knowledge graphs' literature, on the other hand, has proposed light-weight models employing different geometric transformations (GTs) to encode edges in a knowledge graph (KG). Our work explores the possibility of adopting this family of models to encode SyGs. Furthermore, we investigate which GT better encodes syntactic relations, so that these representations can be used to enhance phrase-level composition via syntactic contextualisation.
Data Augmentation for Hypernymy Detection
May 04, 2020
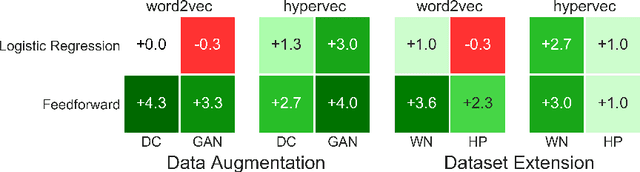
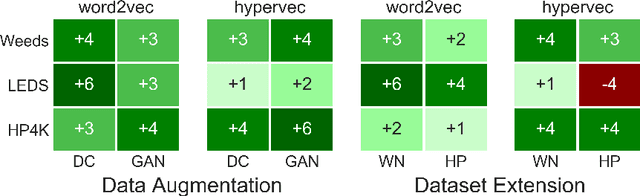
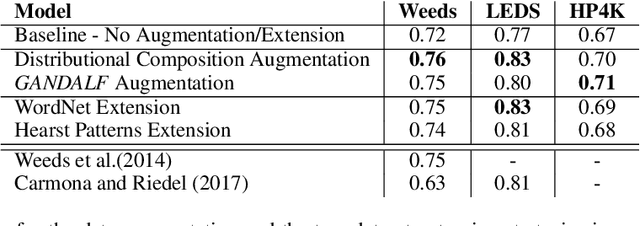
The automatic detection of hypernymy relationships represents a challenging problem in NLP. The successful application of state-of-the-art supervised approaches using distributed representations has generally been impeded by the limited availability of high quality training data. We have developed two novel data augmentation techniques which generate new training examples from existing ones. First, we combine the linguistic principles of hypernym transitivity and intersective modifier-noun composition to generate additional pairs of vectors, such as "small dog - dog" or "small dog - animal", for which a hypernymy relationship can be assumed. Second, we use generative adversarial networks (GANs) to generate pairs of vectors for which the hypernymy relation can also be assumed. We furthermore present two complementary strategies for extending an existing dataset by leveraging linguistic resources such as WordNet. Using an evaluation across 3 different datasets for hypernymy detection and 2 different vector spaces, we demonstrate that both of the proposed automatic data augmentation and dataset extension strategies substantially improve classifier performance.
Data Mining in Clinical Trial Text: Transformers for Classification and Question Answering Tasks
Jan 30, 2020


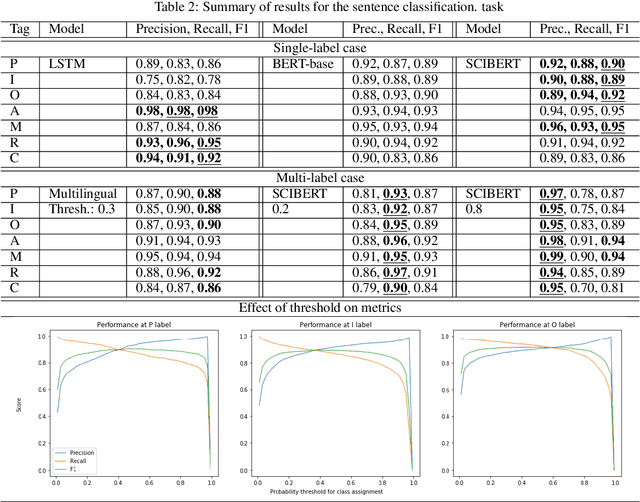
This research on data extraction methods applies recent advances in natural language processing to evidence synthesis based on medical texts. Texts of interest include abstracts of clinical trials in English and in multilingual contexts. The main focus is on information characterized via the Population, Intervention, Comparator, and Outcome (PICO) framework, but data extraction is not limited to these fields. Recent neural network architectures based on transformers show capacities for transfer learning and increased performance on downstream natural language processing tasks such as universal reading comprehension, brought forward by this architecture's use of contextualized word embeddings and self-attention mechanisms. This paper contributes to solving problems related to ambiguity in PICO sentence prediction tasks, as well as highlighting how annotations for training named entity recognition systems are used to train a high-performing, but nevertheless flexible architecture for question answering in systematic review automation. Additionally, it demonstrates how the problem of insufficient amounts of training annotations for PICO entity extraction is tackled by augmentation. All models in this paper were created with the aim to support systematic review (semi)automation. They achieve high F1 scores, and demonstrate the feasibility of applying transformer-based classification methods to support data mining in the biomedical literature.
Improving Semantic Composition with Offset Inference
Apr 21, 2017
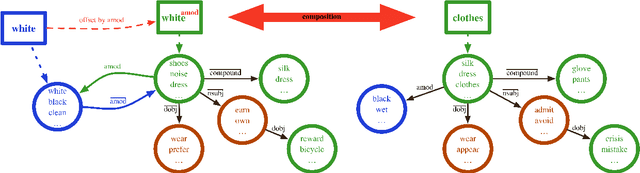

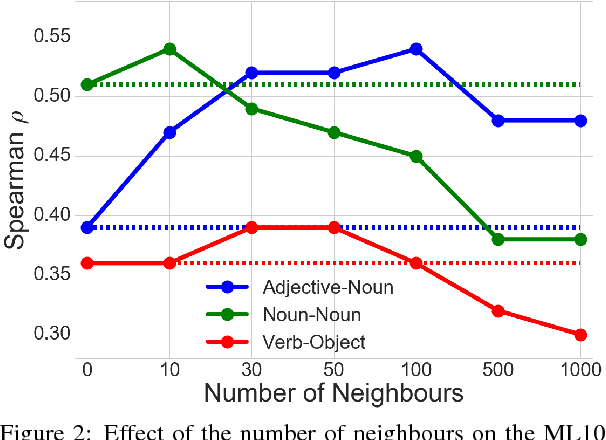
Count-based distributional semantic models suffer from sparsity due to unobserved but plausible co-occurrences in any text collection. This problem is amplified for models like Anchored Packed Trees (APTs), that take the grammatical type of a co-occurrence into account. We therefore introduce a novel form of distributional inference that exploits the rich type structure in APTs and infers missing data by the same mechanism that is used for semantic composition.
One Representation per Word - Does it make Sense for Composition?
Feb 22, 2017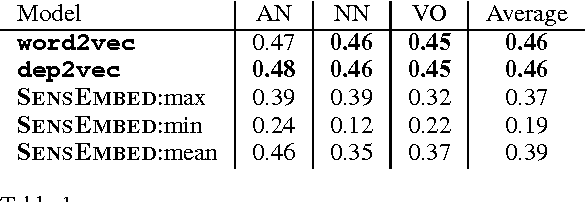

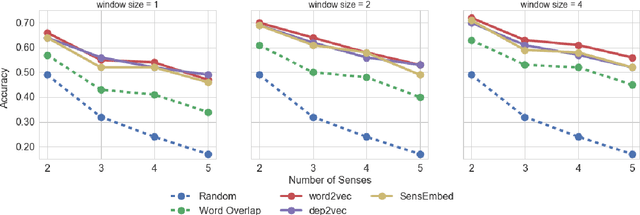
In this paper, we investigate whether an a priori disambiguation of word senses is strictly necessary or whether the meaning of a word in context can be disambiguated through composition alone. We evaluate the performance of off-the-shelf single-vector and multi-sense vector models on a benchmark phrase similarity task and a novel task for word-sense discrimination. We find that single-sense vector models perform as well or better than multi-sense vector models despite arguably less clean elementary representations. Our findings furthermore show that simple composition functions such as pointwise addition are able to recover sense specific information from a single-sense vector model remarkably well.
Aligning Packed Dependency Trees: a theory of composition for distributional semantics
Aug 25, 2016We present a new framework for compositional distributional semantics in which the distributional contexts of lexemes are expressed in terms of anchored packed dependency trees. We show that these structures have the potential to capture the full sentential contexts of a lexeme and provide a uniform basis for the composition of distributional knowledge in a way that captures both mutual disambiguation and generalization.