 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Mining in Clinical Trial Text: Transformers for Classification and Question Answering Tasks
Jan 30, 2020


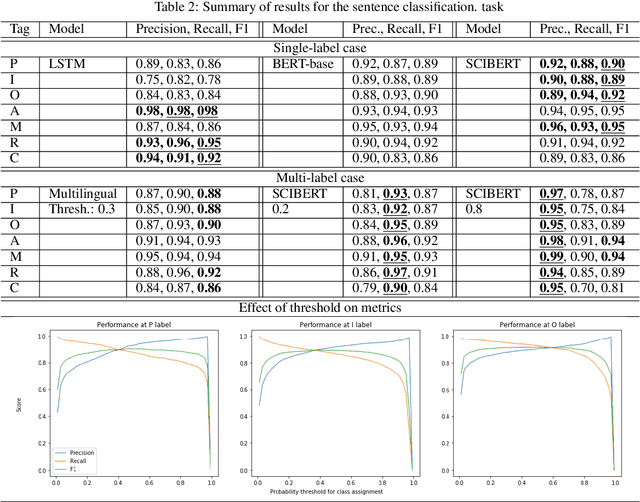
This research on data extraction methods applies recent advances in natural language processing to evidence synthesis based on medical texts. Texts of interest include abstracts of clinical trials in English and in multilingual contexts. The main focus is on information characterized via the Population, Intervention, Comparator, and Outcome (PICO) framework, but data extraction is not limited to these fields. Recent neural network architectures based on transformers show capacities for transfer learning and increased performance on downstream natural language processing tasks such as universal reading comprehension, brought forward by this architecture's use of contextualized word embeddings and self-attention mechanisms. This paper contributes to solving problems related to ambiguity in PICO sentence prediction tasks, as well as highlighting how annotations for training named entity recognition systems are used to train a high-performing, but nevertheless flexible architecture for question answering in systematic review automation. Additionally, it demonstrates how the problem of insufficient amounts of training annotations for PICO entity extraction is tackled by augmentation. All models in this paper were created with the aim to support systematic review (semi)automation. They achieve high F1 scores, and demonstrate the feasibility of applying transformer-based classification methods to support data mining in the biomedical literature.