 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Augmented Generation Evaluation for Health Documents
May 07, 2025Safe and trustworthy use of Large Language Models (LLM) in the processing of healthcare documents and scientific papers could substantially help clinicians, scientists and policymakers in overcoming information overload and focusing on the most relevant information at a given moment. Retrieval Augmented Generation (RAG) is a promising method to leverage the potential of LLMs while enhancing the accuracy of their outcomes. This report assesses the potentials and shortcomings of such approaches in the automatic knowledge synthesis of different types of documents in the health domain. To this end, it describes: (1) an internally developed proof of concept pipeline that employs state-of-the-art practices to deliver safe and trustable analysis for healthcare documents and scientific papers called RAGEv (Retrieval Augmented Generation Evaluation); (2) a set of evaluation tools for LLM-based document retrieval and generation; (3) a benchmark dataset to verify the accuracy and veracity of the results called RAGEv-Bench. It concludes that careful implementations of RAG techniques could minimize most of the common problems in the use of LLMs for document processing in the health domain, obtaining very high scores both on short yes/no answers and long answers. There is a high potential for incorporating it into the day-to-day work of policy support tasks, but additional efforts are required to obtain a consistent and trustworthy tool.
Conformal Risk Control for Pulmonary Nodule Detection
Dec 28, 2024



Quantitative tools are increasingly appealing for decision support in healthcare, driven by the growing capabilities of advanced AI systems. However, understanding the predictive uncertainties surrounding a tool's output is crucial for decision-makers to ensure reliable and transparent decisions. In this paper, we present a case study on pulmonary nodule detection for lung cancer screening, enhancing an advanced detection model with an uncertainty quantification technique called conformal risk control (CRC). We demonstrate that prediction sets with conformal guarantees are attractive measures of predictive uncertainty in the safety-critical healthcare domain, allowing end-users to achieve arbitrary validity by trading off false positives and providing formal statistical guarantees on model performance. Among ground-truth nodules annotated by at least three radiologists, our model achieves a sensitivity that is competitive with that generally achieved by individual radiologists, with a slight increase in false positives. Furthermore, we illustrate the risks of using off-the-shelve prediction models when faced with ontological uncertainty, such as when radiologists disagree on what constitutes the ground truth on pulmonary nodules.
Epidemic Information Extraction for Event-Based Surveillance using Large Language Models
Aug 26, 2024This paper presents a novel approach to epidemic surveillance, leveraging the power of Artificial Intelligence and Large Language Models (LLMs) for effective interpretation of unstructured big data sources, like the popular ProMED and WHO Disease Outbreak News. We explore several LLMs, evaluating their capabilities in extracting valuable epidemic information. We further enhance the capabilities of the LLMs using in-context learning, and test the performance of an ensemble model incorporating multiple open-source LLMs. The findings indicate that LLMs can significantly enhance the accuracy and timeliness of epidemic modelling and forecasting, offering a promising tool for managing future pandemic events.
* 11 pages, 4 figures, Ninth International Congress on Information and Communication Technology (ICICT 2024)
Dreams Are More "Predictable'' Than You Think
May 08, 2023A consistent body of evidence suggests that dream reports significantly vary from other types of textual transcripts with respect to semantic content. Furthermore, it appears to be a widespread belief in the dream/sleep research community that dream reports constitute rather ``unique'' strings of text. This might be a notable issue for the growing amount of approaches using natural language processing (NLP) tools to automatically analyse dream reports, as they largely rely on neural models trained on non-dream corpora scraped from the web. In this work, I will adopt state-of-the-art (SotA) large language models (LLMs), to study if and how dream reports deviate from other human-generated text strings, such as Wikipedia. Results show that, taken as a whole, DreamBank does not deviate from Wikipedia. Moreover, on average, single dream reports are significantly more predictable than Wikipedia articles. Preliminary evidence suggests that word count, gender, and visual impairment can significantly shape how predictable a dream report can appear to the model.
Automatic Scoring of Dream Reports' Emotional Content with Large Language Models
Feb 28, 2023In the field of dream research, the study of dream content typically relies on the analysis of verbal reports provided by dreamers upon awakening from their sleep. This task is classically performed through manual scoring provided by trained annotators, at a great time expense. While a consistent body of work suggests that natural language processing (NLP) tools can support the automatic analysis of dream reports, proposed methods lacked the ability to reason over a report's full context and required extensive data pre-processing. Furthermore, in most cases, these methods were not validated against standard manual scoring approaches. In this work, we address these limitations by adopting large language models (LLMs) to study and replicate the manual annotation of dream reports, using a mixture of off-the-shelf and bespoke approaches, with a focus on references to reports' emotions. Our results show that the off-the-shelf method achieves a low performance probably in light of inherent linguistic differences between reports collected in different (groups of) individuals. On the other hand, the proposed bespoke text classification method achieves a high performance, which is robust against potential biases. Overall, these observations indicate that our approach could find application in the analysis of large dream datasets and may favour reproducibility and comparability of results across studies.
Representing Syntax and Composition with Geometric Transformations
Jun 03, 2021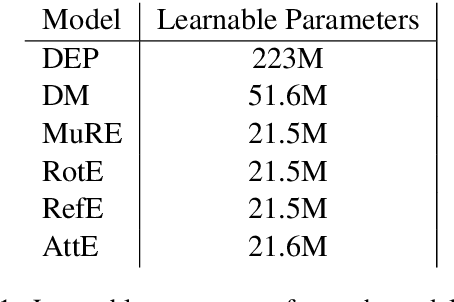
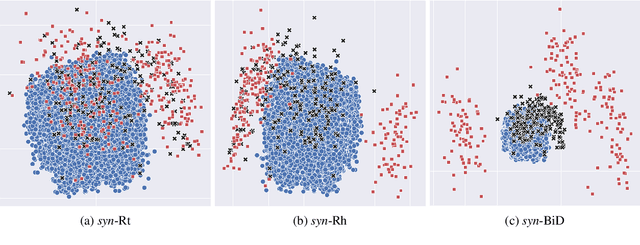
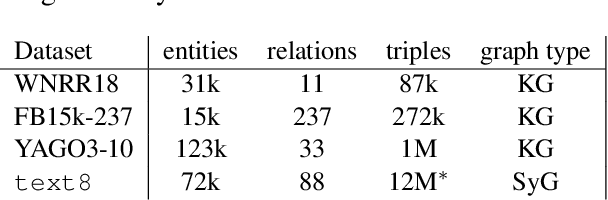
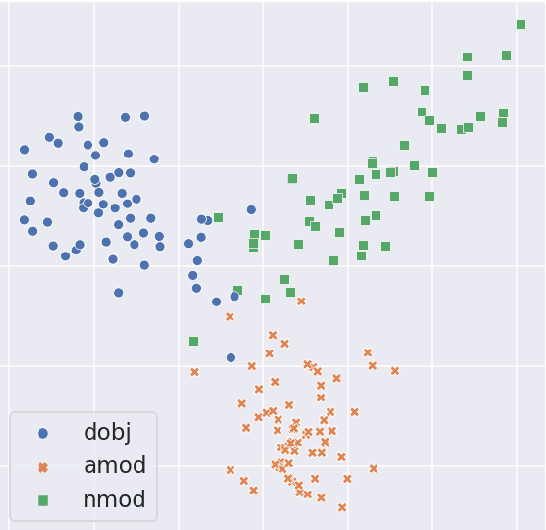
The exploitation of syntactic graphs (SyGs) as a word's context has been shown to be beneficial for distributional semantic models (DSMs), both at the level of individual word representations and in deriving phrasal representations via composition. However, notwithstanding the potential performance benefit, the syntactically-aware DSMs proposed to date have huge numbers of parameters (compared to conventional DSMs) and suffer from data sparsity. Furthermore, the encoding of the SyG links (i.e., the syntactic relations) has been largely limited to linear maps. The knowledge graphs' literature, on the other hand, has proposed light-weight models employing different geometric transformations (GTs) to encode edges in a knowledge graph (KG). Our work explores the possibility of adopting this family of models to encode SyGs. Furthermore, we investigate which GT better encodes syntactic relations, so that these representations can be used to enhance phrase-level composition via syntactic contextualisation.
Data Augmentation for Hypernymy Detection
May 04, 2020
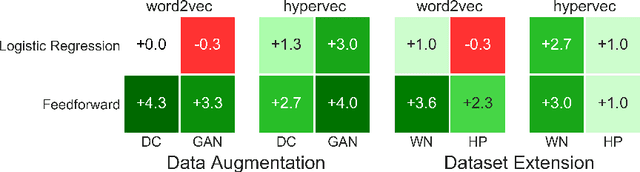
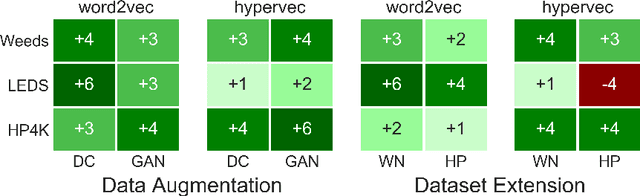
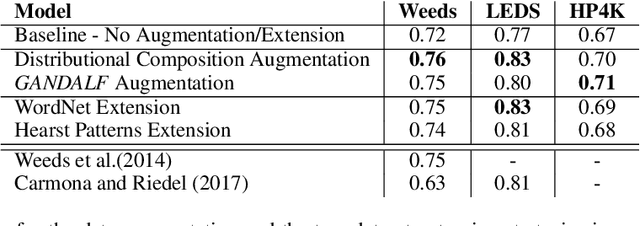
The automatic detection of hypernymy relationships represents a challenging problem in NLP. The successful application of state-of-the-art supervised approaches using distributed representations has generally been impeded by the limited availability of high quality training data. We have developed two novel data augmentation techniques which generate new training examples from existing ones. First, we combine the linguistic principles of hypernym transitivity and intersective modifier-noun composition to generate additional pairs of vectors, such as "small dog - dog" or "small dog - animal", for which a hypernymy relationship can be assumed. Second, we use generative adversarial networks (GANs) to generate pairs of vectors for which the hypernymy relation can also be assumed. We furthermore present two complementary strategies for extending an existing dataset by leveraging linguistic resources such as WordNet. Using an evaluation across 3 different datasets for hypernymy detection and 2 different vector spaces, we demonstrate that both of the proposed automatic data augmentation and dataset extension strategies substantially improve classifier performance.