 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Augmented Generation Evaluation for Health Documents
May 07, 2025Safe and trustworthy use of Large Language Models (LLM) in the processing of healthcare documents and scientific papers could substantially help clinicians, scientists and policymakers in overcoming information overload and focusing on the most relevant information at a given moment. Retrieval Augmented Generation (RAG) is a promising method to leverage the potential of LLMs while enhancing the accuracy of their outcomes. This report assesses the potentials and shortcomings of such approaches in the automatic knowledge synthesis of different types of documents in the health domain. To this end, it describes: (1) an internally developed proof of concept pipeline that employs state-of-the-art practices to deliver safe and trustable analysis for healthcare documents and scientific papers called RAGEv (Retrieval Augmented Generation Evaluation); (2) a set of evaluation tools for LLM-based document retrieval and generation; (3) a benchmark dataset to verify the accuracy and veracity of the results called RAGEv-Bench. It concludes that careful implementations of RAG techniques could minimize most of the common problems in the use of LLMs for document processing in the health domain, obtaining very high scores both on short yes/no answers and long answers. There is a high potential for incorporating it into the day-to-day work of policy support tasks, but additional efforts are required to obtain a consistent and trustworthy tool.
Sentiment Analysis of Economic Text: A Lexicon-Based Approach
Nov 21, 2024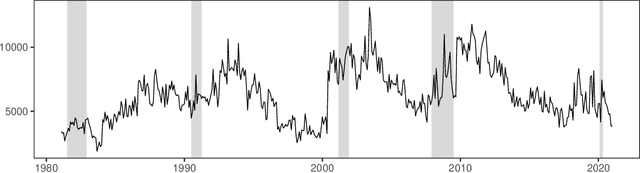
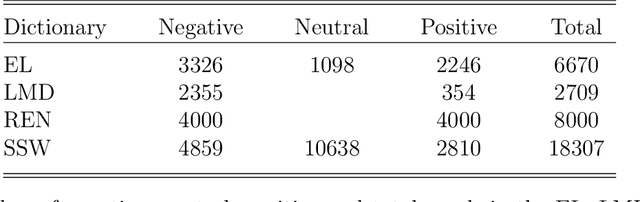
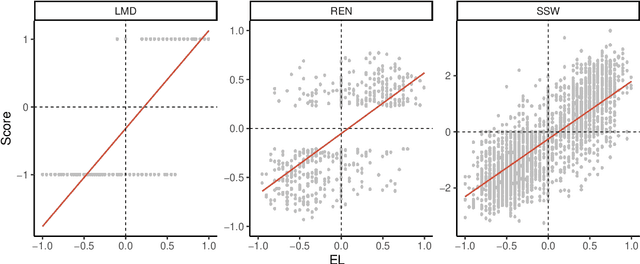
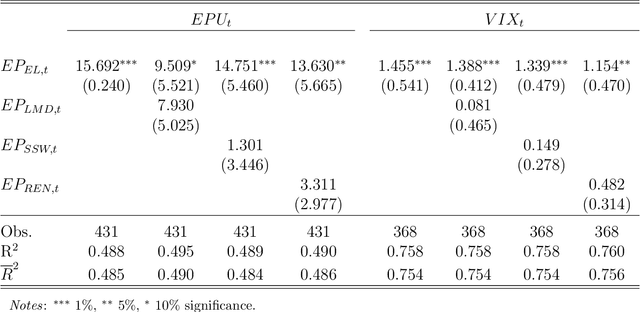
We propose an Economic Lexicon (EL) specifically designed for textual applications in economics. We construct the dictionary with two important characteristics: 1) to have a wide coverage of terms used in documents discussing economic concepts, and 2) to provide a human-annotated sentiment score in the range [-1,1]. We illustrate the use of the EL in the context of a simple sentiment measure and consider several applications in economics. The comparison to other lexicons shows that the EL is superior due to its wider coverage of domain relevant terms and its more accurate categorization of the word sentiment.
* 37 pages, 9 figures, 6 tables, in press
Triplètoile: Extraction of Knowledge from Microblogging Text
Aug 27, 2024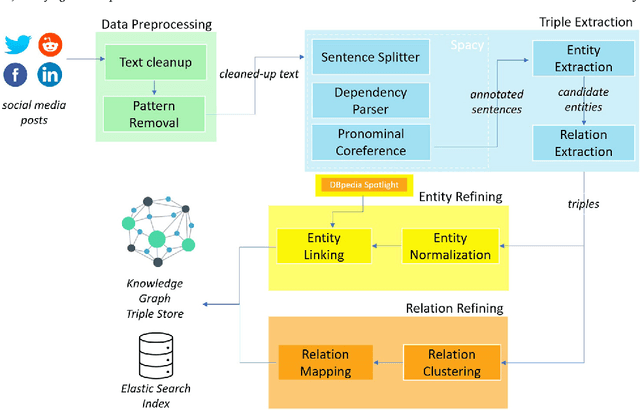



Numerous methods and pipelines have recently emerged for the automatic extraction of knowledge graphs from documents such as scientific publications and patents. However, adapting these methods to incorporate alternative text sources like micro-blogging posts and news has proven challenging as they struggle to model open-domain entities and relations, typically found in these sources. In this paper, we propose an enhanced information extraction pipeline tailored to the extraction of a knowledge graph comprising open-domain entities from micro-blogging posts on social media platforms. Our pipeline leverages dependency parsing and classifies entity relations in an unsupervised manner through hierarchical clustering over word embeddings. We provide a use case on extracting semantic triples from a corpus of 100 thousand tweets about digital transformation and publicly release the generated knowledge graph. On the same dataset, we conduct two experimental evaluations, showing that the system produces triples with precision over 95% and outperforms similar pipelines of around 5% in terms of precision, while generating a comparatively higher number of triples.
* 42 pages, 6 figures
Epidemic Information Extraction for Event-Based Surveillance using Large Language Models
Aug 26, 2024This paper presents a novel approach to epidemic surveillance, leveraging the power of Artificial Intelligence and Large Language Models (LLMs) for effective interpretation of unstructured big data sources, like the popular ProMED and WHO Disease Outbreak News. We explore several LLMs, evaluating their capabilities in extracting valuable epidemic information. We further enhance the capabilities of the LLMs using in-context learning, and test the performance of an ensemble model incorporating multiple open-source LLMs. The findings indicate that LLMs can significantly enhance the accuracy and timeliness of epidemic modelling and forecasting, offering a promising tool for managing future pandemic events.
* 11 pages, 4 figures, Ninth International Congress on Information and Communication Technology (ICICT 2024)
A Few-Shot Approach for Relation Extraction Domain Adaptation using Large Language Models
Aug 05, 2024
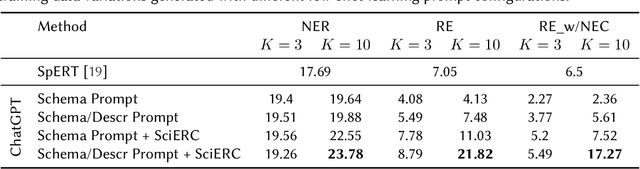

Knowledge graphs (KGs) have been successfully applied to the analysis of complex scientific and technological domains, with automatic KG generation methods typically building upon relation extraction models capturing fine-grained relations between domain entities in text. While these relations are fully applicable across scientific areas, existing models are trained on few domain-specific datasets such as SciERC and do not perform well on new target domains. In this paper, we experiment with leveraging in-context learning capabilities of Large Language Models to perform schema-constrained data annotation, collecting in-domain training instances for a Transformer-based relation extraction model deployed on titles and abstracts of research papers in the Architecture, Construction, Engineering and Operations (AECO) domain. By assessing the performance gain with respect to a baseline Deep Learning architecture trained on off-domain data, we show that by using a few-shot learning strategy with structured prompts and only minimal expert annotation the presented approach can potentially support domain adaptation of a science KG generation model.
A Novel Lexicon for the Moral Foundation of Liberty
Jul 16, 2024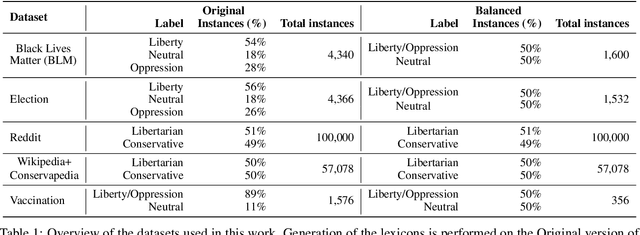
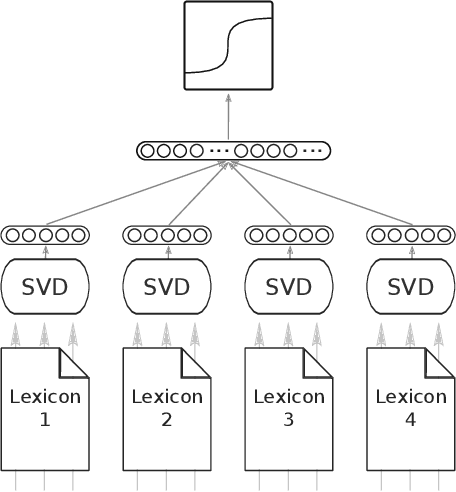

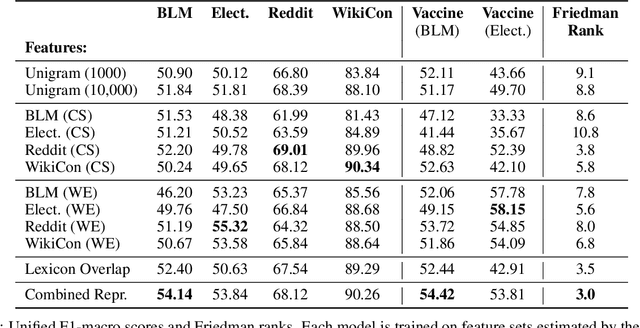
The moral value of liberty is a central concept in our inference system when it comes to taking a stance towards controversial social issues such as vaccine hesitancy, climate change, or the right to abortion. Here, we propose a novel Liberty lexicon evaluated on more than 3,000 manually annotated data both in in- and out-of-domain scenarios. As a result of this evaluation, we produce a combined lexicon that constitutes the main outcome of this work. This final lexicon incorporates information from an ensemble of lexicons that have been generated using word embedding similarity (WE) and compositional semantics (CS). Our key contributions include enriching the liberty annotations, developing a robust liberty lexicon for broader application, and revealing the complexity of expressions related to liberty across different platforms. Through the evaluation, we show that the difficulty of the task calls for designing approaches that combine knowledge, in an effort of improving the representations of learning systems.
Forecasting GDP in Europe with Textual Data
Jan 14, 2024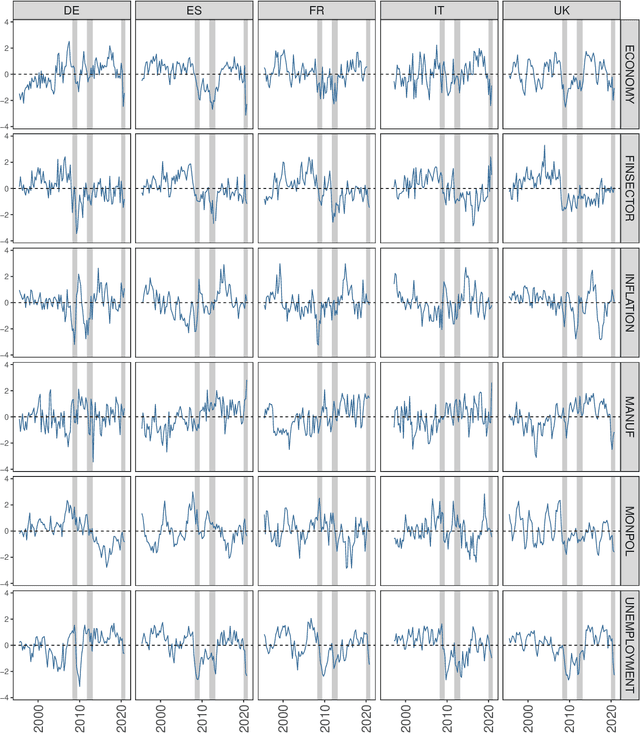
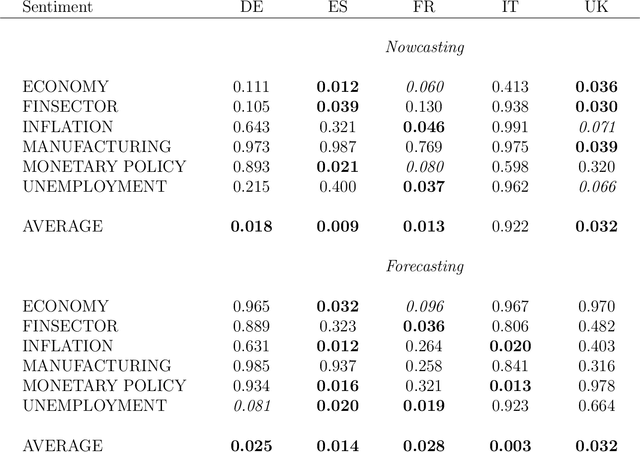
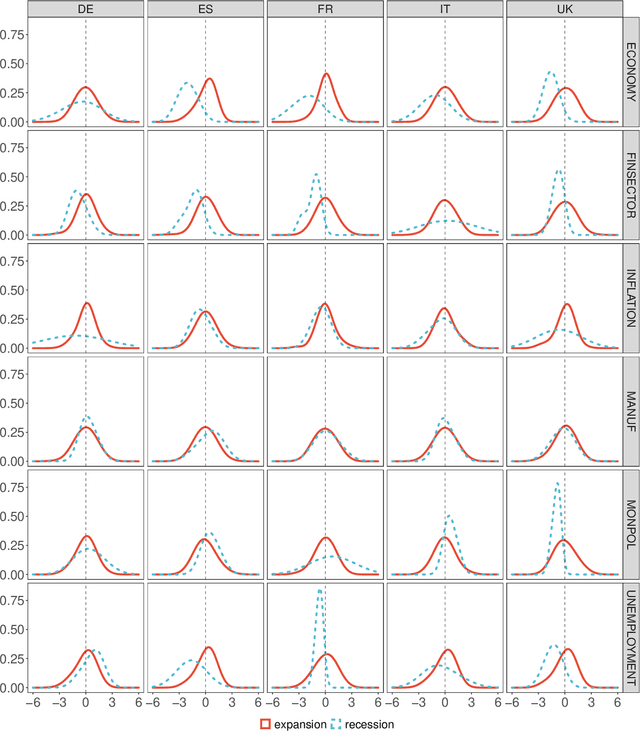
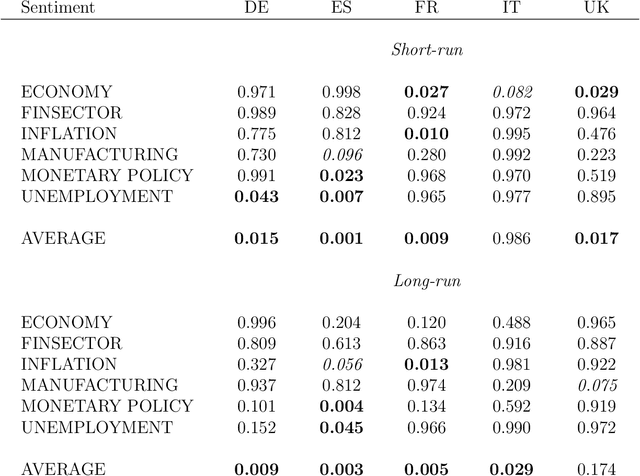
We evaluate the informational content of news-based sentiment indicators for forecasting Gross Domestic Product (GDP) and other macroeconomic variables of the five major European economies. Our data set includes over 27 million articles for 26 major newspapers in 5 different languages. The evidence indicates that these sentiment indicators are significant predictors to forecast macroeconomic variables and their predictive content is robust to controlling for other indicators available to forecasters in real-time.
Forecasting with Economic News
Mar 29, 2022The goal of this paper is to evaluate the informational content of sentiment extracted from news articles about the state of the economy. We propose a fine-grained aspect-based sentiment analysis that has two main characteristics: 1) we consider only the text in the article that is semantically dependent on a term of interest (aspect-based) and, 2) assign a sentiment score to each word based on a dictionary that we develop for applications in economics and finance (fine-grained). Our data set includes six large US newspapers, for a total of over 6.6 million articles and 4.2 billion words. Our findings suggest that several measures of economic sentiment track closely business cycle fluctuations and that they are relevant predictors for four major macroeconomic variables. We find that there are significant improvements in forecasting when sentiment is considered along with macroeconomic factors. In addition, we also find that sentiment matters to explains the tails of the probability distribution across several macroeconomic variables.
Neural Forecasting of the Italian Sovereign Bond Market with Economic News
Mar 11, 2022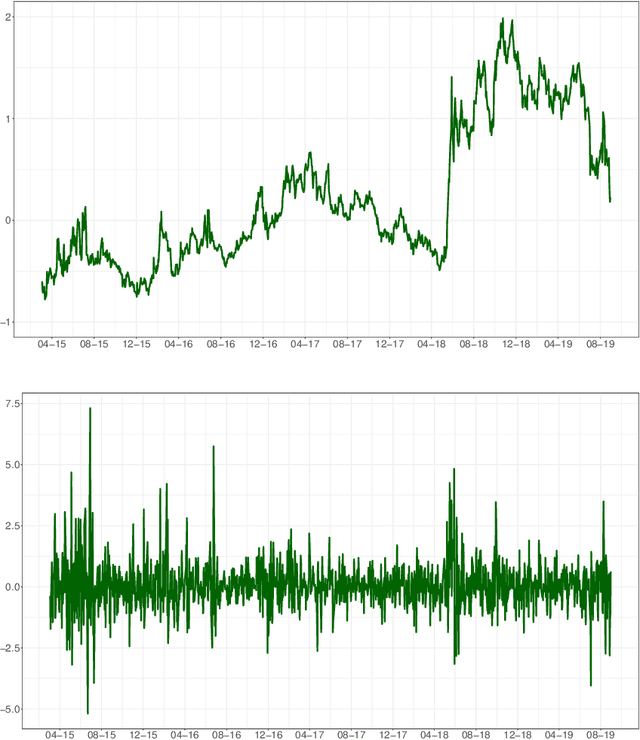
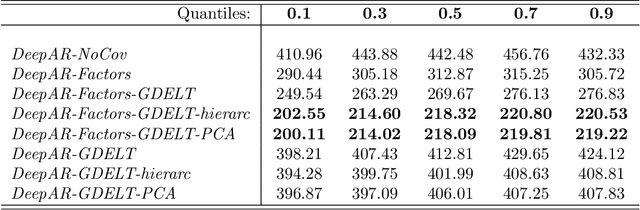
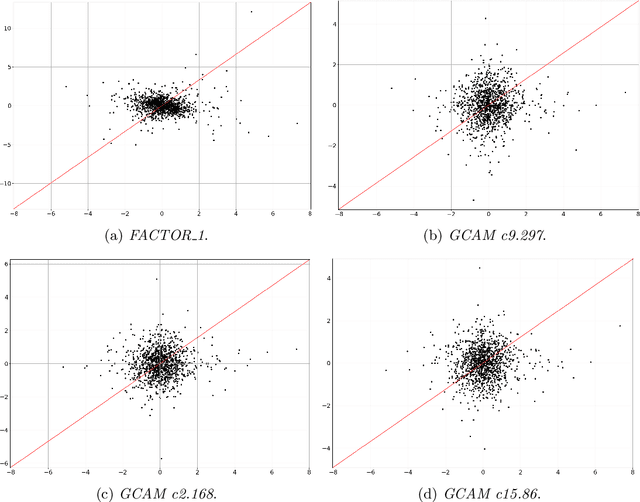
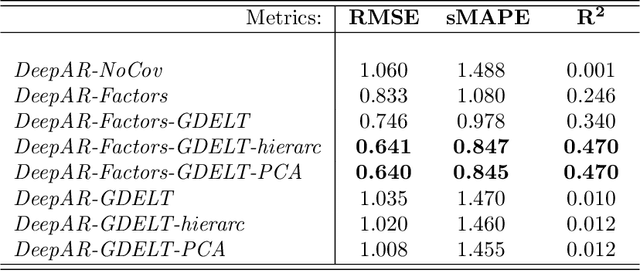
In this paper we employ economic news within a neural network framework to forecast the Italian 10-year interest rate spread. We use a big, open-source, database known as Global Database of Events, Language and Tone to extract topical and emotional news content linked to bond markets dynamics. We deploy such information within a probabilistic forecasting framework with autoregressive recurrent networks (DeepAR). Our findings suggest that a deep learning network based on Long-Short Term Memory cells outperforms classical machine learning techniques and provides a forecasting performance that is over and above that obtained by using conventional determinants of interest rates alone.
* 24 pages, 8 figures, in press
Emotions in Macroeconomic News and their Impact on the European Bond Market
Jun 15, 2021
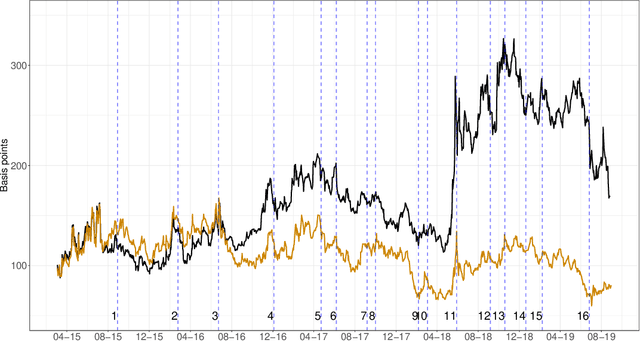
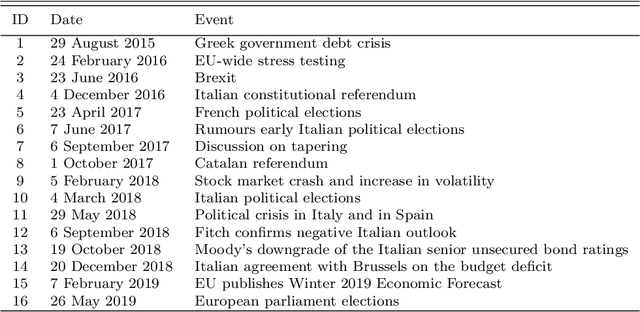
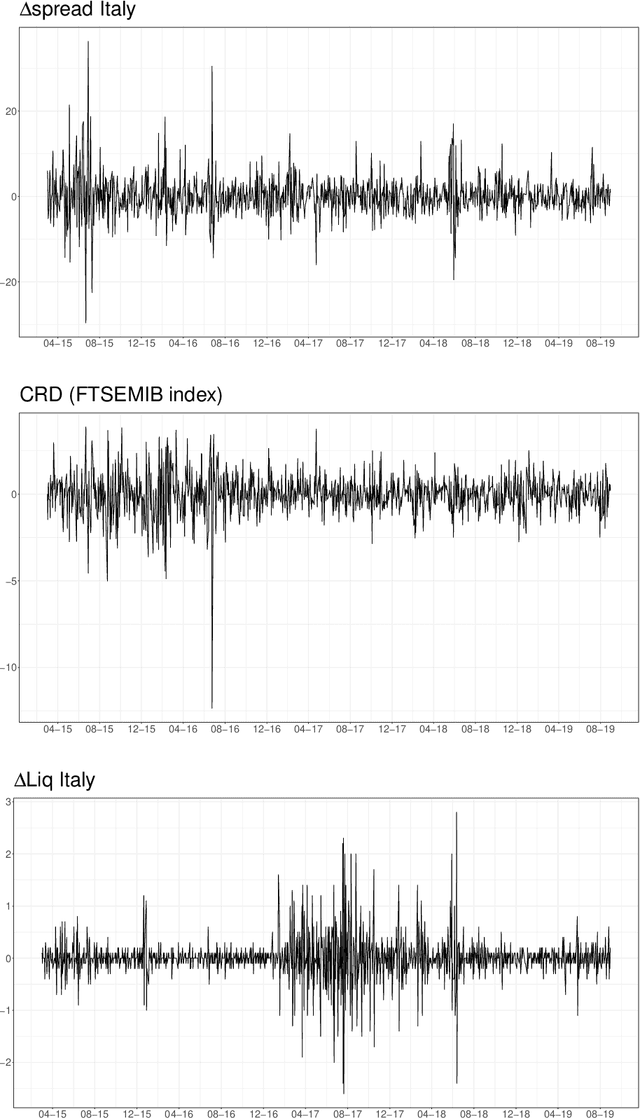
We show how emotions extracted from macroeconomic news can be used to explain and forecast future behaviour of sovereign bond yield spreads in Italy and Spain. We use a big, open-source, database known as Global Database of Events, Language and Tone to construct emotion indicators of bond market affective states. We find that negative emotions extracted from news improve the forecasting power of government yield spread models during distressed periods even after controlling for the number of negative words present in the text. In addition, stronger negative emotions, such as panic, reveal useful information for predicting changes in spread at the short-term horizon, while milder emotions, such as distress, are useful at longer time horizons. Emotions generated by the Italian political turmoil propagate to the Spanish news affecting this neighbourhood market.