 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Lexicon for the Moral Foundation of Liberty
Jul 16, 2024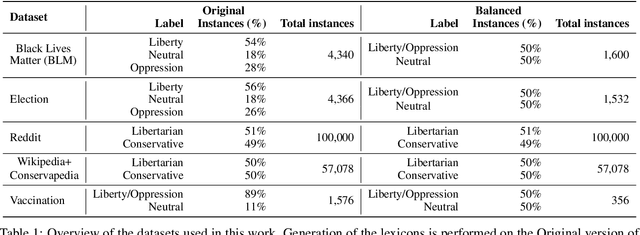
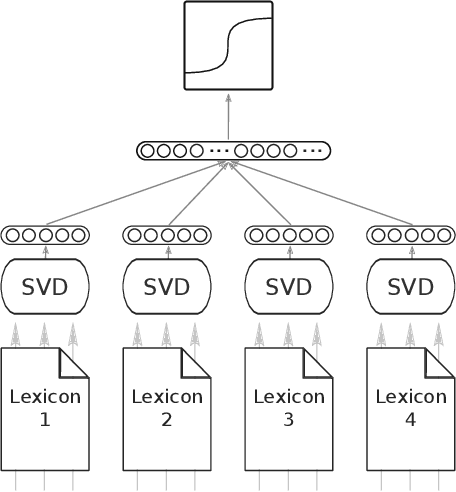

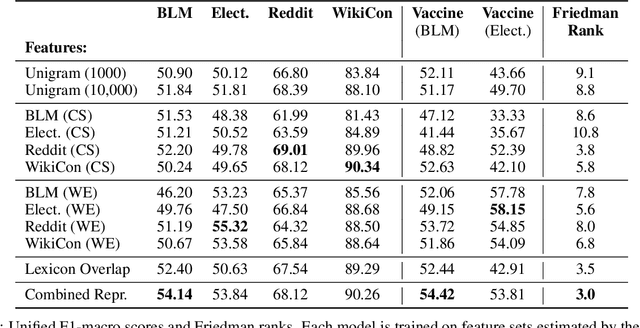
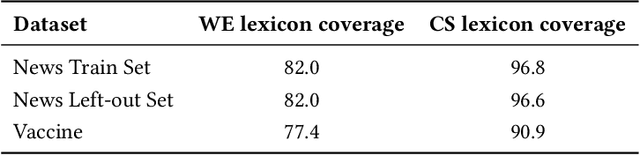
The moral value of liberty is a central concept in our inference system when it comes to taking a stance towards controversial social issues such as vaccine hesitancy, climate change, or the right to abortion. Here, we propose a novel Liberty lexicon evaluated on more than 3,000 manually annotated data both in in- and out-of-domain scenarios. As a result of this evaluation, we produce a combined lexicon that constitutes the main outcome of this work. This final lexicon incorporates information from an ensemble of lexicons that have been generated using word embedding similarity (WE) and compositional semantics (CS). Our key contributions include enriching the liberty annotations, developing a robust liberty lexicon for broader application, and revealing the complexity of expressions related to liberty across different platforms. Through the evaluation, we show that the difficulty of the task calls for designing approaches that combine knowledge, in an effort of improving the representations of learning systems.
LibertyMFD: A Lexicon to Assess the Moral Foundation of Liberty
Sep 14, 2022


Quantifying the moral narratives expressed in the user-generated text, news, or public discourses is fundamental for understanding individuals' concerns and viewpoints and preventing violent protests and social polarisation. The Moral Foundation Theory (MFT) was developed to operationalise morality in a five-dimensional scale system. Recent developments of the theory urged for the introduction of a new foundation, the Liberty Foundation. Being only recently added to the theory, there are no available linguistic resources to assess whether liberty is present in text corpora. Given its importance to current social issues such as the vaccination debate, we propose two data-driven approaches, deriving two candidate lexicons generated based on aligned documents from online news sources with different worldviews. After extensive experimentation, we contribute to the research community a novel lexicon that assesses the liberty moral foundation in the way individuals with contrasting viewpoints express themselves through written text. The LibertyMFD dictionary can be a valuable tool for policymakers to understand diverse viewpoints on controversial social issues such as vaccination, abortion, or even uprisings, as they happen and on a large scale.
* GoodIT '22: Proceedings of the 2022 ACM Conference on Information Technology for Social Good. GoodIT'22, September 7-9, 2022, Limassol, Cyprus
MoralStrength: Exploiting a Moral Lexicon and Embedding Similarity for Moral Foundations Prediction
Apr 17, 2019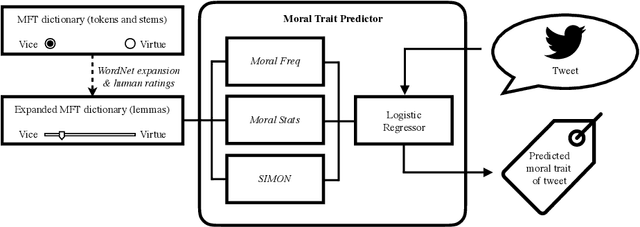
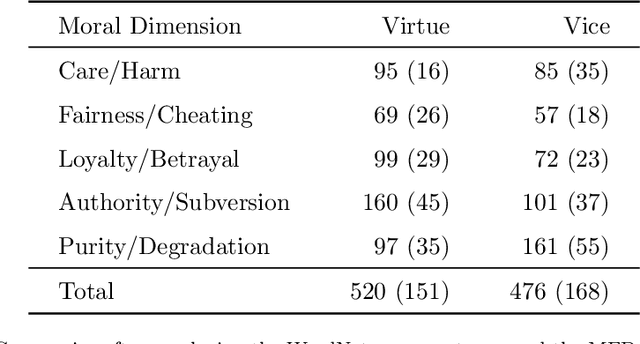
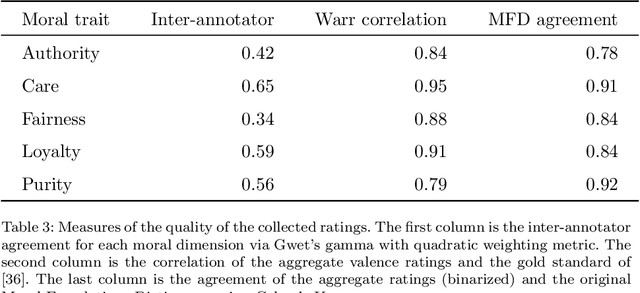
Opinions and attitudes towards controversial social and political issues are hardly ever based on evidence alone. Moral values play a fundamental role in the decision-making process of how we perceive and interpret information. The Moral Foundations Dictionary (MFD) was developed to operationalize moral values in text. In this study, we present MoralStrength, a lexicon of approximately 1,000 lemmas, obtained as an extension of the Moral Foundations Dictionary, based on WordNet synsets. Moreover, for each lemma it provides with a crowdsourced numeric assessment of Moral Valence, indicating the strength with which a lemma is expressing the specific value. We evaluated the predictive potentials of this moral lexicon, defining three utilization approaches of increasing complexity, ranging from statistical properties of the lexicon to a deep learning approach of word embeddings based on semantic similarity. Logistic regression models trained on the features extracted from MoralStrength, significantly outperformed the current state-of-the-art, reaching an F1-score of 87.6% over the previous 62.4% (p-value<0.01). Such findings pave the way for further research, allowing for an in-depth understanding of moral narratives in text for a wide range of social issues.
DepecheMood++: a Bilingual Emotion Lexicon Built Through Simple Yet Powerful Techniques
Oct 08, 2018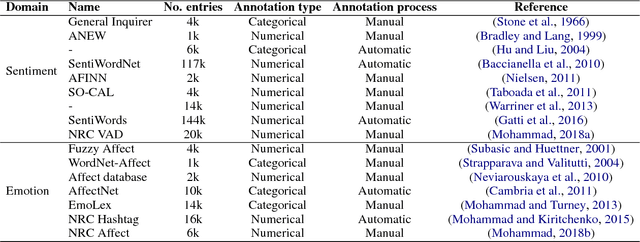

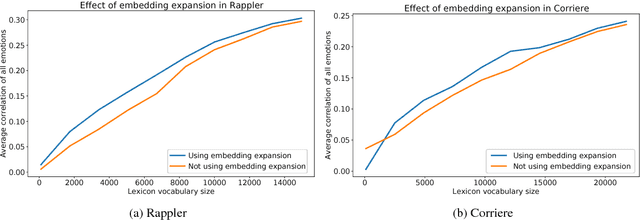
Several lexica for sentiment analysis have been developed and made available in the NLP community. While most of these come with word polarity annotations (e.g. positive/negative), attempts at building lexica for finer-grained emotion analysis (e.g. happiness, sadness) have recently attracted significant attention. Such lexica are often exploited as a building block in the process of developing learning models for which emotion recognition is needed, and/or used as baselines to which compare the performance of the models. In this work, we contribute two new resources to the community: a) an extension of an existing and widely used emotion lexicon for English; and b) a novel version of the lexicon targeting Italian. Furthermore, we show how simple techniques can be used, both in supervised and unsupervised experimental settings, to boost performances on datasets and tasks of varying degree of domain-specificity.
Fortia-FBK at SemEval-2017 Task 5: Bullish or Bearish? Inferring Sentiment towards Brands from Financial News Headlines
Apr 04, 2017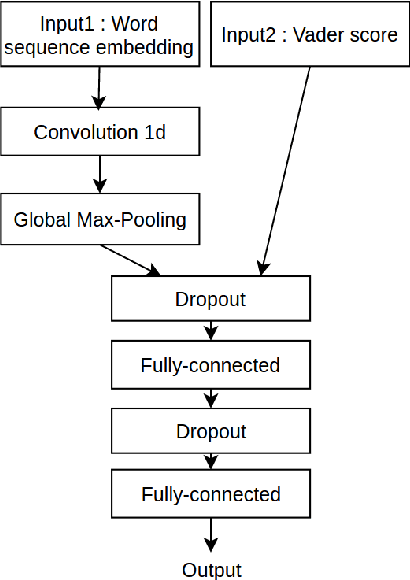


In this paper, we describe a methodology to infer Bullish or Bearish sentiment towards companies/brands. More specifically, our approach leverages affective lexica and word embeddings in combination with convolutional neural networks to infer the sentiment of financial news headlines towards a target company. Such architecture was used and evaluated in the context of the SemEval 2017 challenge (task 5, subtask 2), in which it obtained the best performance.
SentiWords: Deriving a High Precision and High Coverage Lexicon for Sentiment Analysis
Oct 30, 2015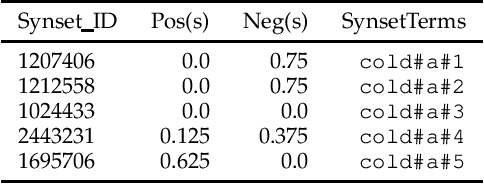
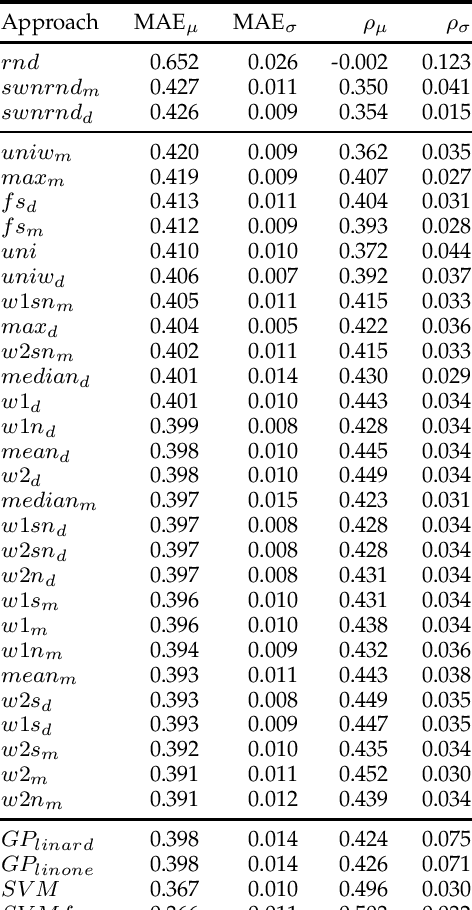
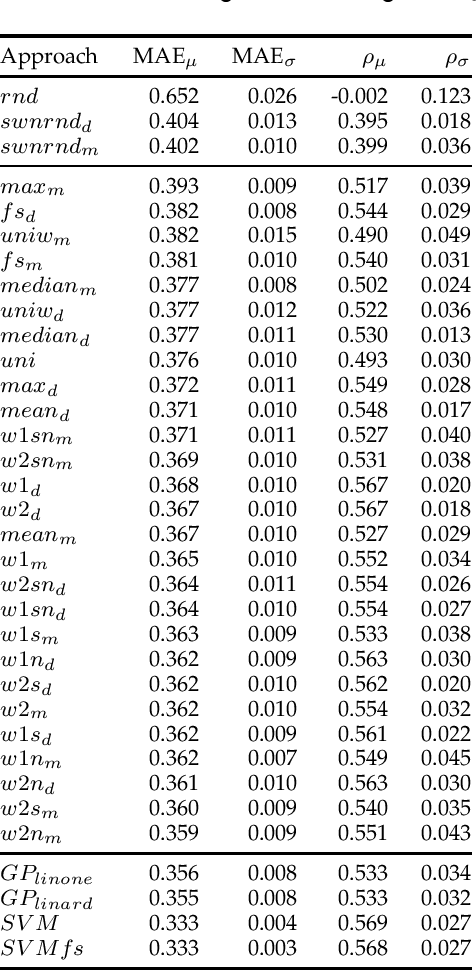
Deriving prior polarity lexica for sentiment analysis - where positive or negative scores are associated with words out of context - is a challenging task. Usually, a trade-off between precision and coverage is hard to find, and it depends on the methodology used to build the lexicon. Manually annotated lexica provide a high precision but lack in coverage, whereas automatic derivation from pre-existing knowledge guarantees high coverage at the cost of a lower precision. Since the automatic derivation of prior polarities is less time consuming than manual annotation, there has been a great bloom of these approaches, in particular based on the SentiWordNet resource. In this paper, we compare the most frequently used techniques based on SentiWordNet with newer ones and blend them in a learning framework (a so called 'ensemble method'). By taking advantage of manually built prior polarity lexica, our ensemble method is better able to predict the prior value of unseen words and to outperform all the other SentiWordNet approaches. Using this technique we have built SentiWords, a prior polarity lexicon of approximately 155,000 words, that has both a high precision and a high coverage. We finally show that in sentiment analysis tasks, using our lexicon allows us to outperform both the single metrics derived from SentiWordNet and popular manually annotated sentiment lexica.
Sentiment Analysis: How to Derive Prior Polarities from SentiWordNet
Sep 23, 2013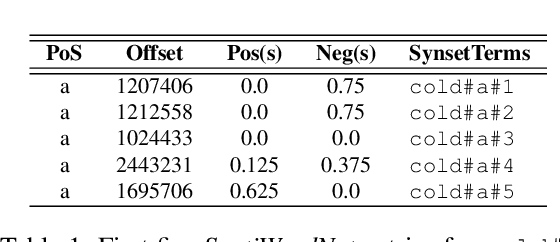
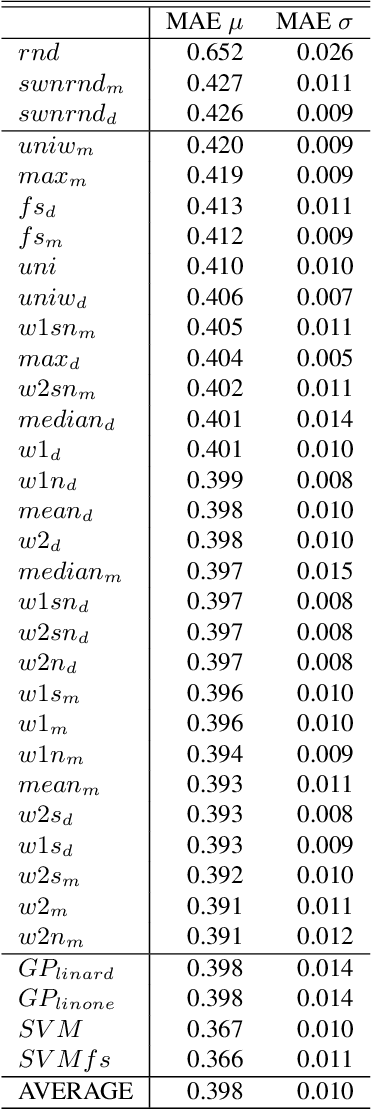
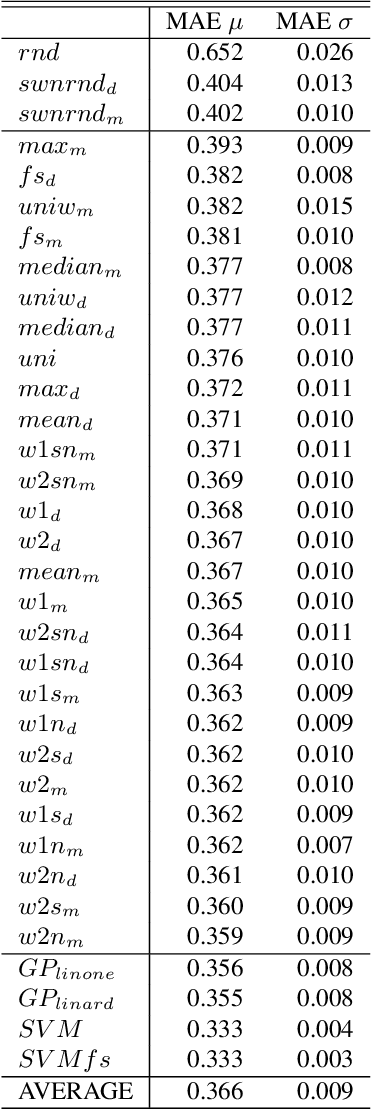
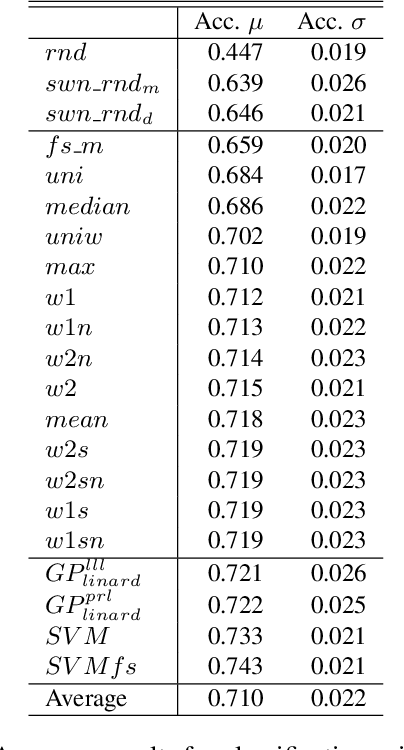
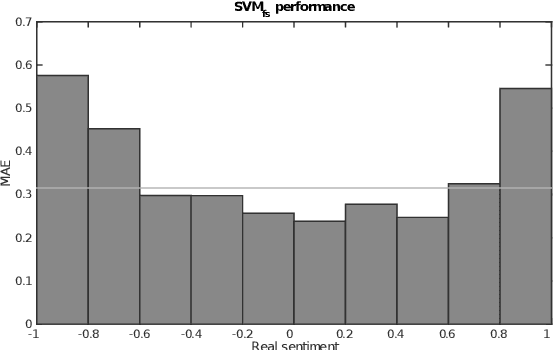
Assigning a positive or negative score to a word out of context (i.e. a word's prior polarity) is a challenging task for sentiment analysis. In the literature, various approaches based on SentiWordNet have been proposed. In this paper, we compare the most often used techniques together with newly proposed ones and incorporate all of them in a learning framework to see whether blending them can further improve the estimation of prior polarity scores. Using two different versions of SentiWordNet and testing regression and classification models across tasks and datasets, our learning approach consistently outperforms the single metrics, providing a new state-of-the-art approach in computing words' prior polarity for sentiment analysis. We conclude our investigation showing interesting biases in calculated prior polarity scores when word Part of Speech and annotator gender are considered.
Assessing Sentiment Strength in Words Prior Polarities
Dec 18, 2012



Many approaches to sentiment analysis rely on lexica where words are tagged with their prior polarity - i.e. if a word out of context evokes something positive or something negative. In particular, broad-coverage resources like SentiWordNet provide polarities for (almost) every word. Since words can have multiple senses, we address the problem of how to compute the prior polarity of a word starting from the polarity of each sense and returning its polarity strength as an index between -1 and 1. We compare 14 such formulae that appear in the literature, and assess which one best approximates the human judgement of prior polarities, with both regression and classification models.