 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Language-Model Framework for Automated Humanitarian Situation Reporting
Dec 22, 2025Timely and accurate situational reports are essential for humanitarian decision-making, yet current workflows remain largely manual, resource intensive, and inconsistent. We present a fully automated framework that uses large language models (LLMs) to transform heterogeneous humanitarian documents into structured and evidence-grounded reports. The system integrates semantic text clustering, automatic question generation, retrieval augmented answer extraction with citations, multi-level summarization, and executive summary generation, supported by internal evaluation metrics that emulate expert reasoning. We evaluated the framework across 13 humanitarian events, including natural disasters and conflicts, using more than 1,100 documents from verified sources such as ReliefWeb. The generated questions achieved 84.7 percent relevance, 84.0 percent importance, and 76.4 percent urgency. The extracted answers reached 86.3 percent relevance, with citation precision and recall both exceeding 76 percent. Agreement between human and LLM based evaluations surpassed an F1 score of 0.80. Comparative analysis shows that the proposed framework produces reports that are more structured, interpretable, and actionable than existing baselines. By combining LLM reasoning with transparent citation linking and multi-level evaluation, this study demonstrates that generative AI can autonomously produce accurate, verifiable, and operationally useful humanitarian situation reports.
Language-Agnostic Modeling of Source Reliability on Wikipedia
Oct 24, 2024
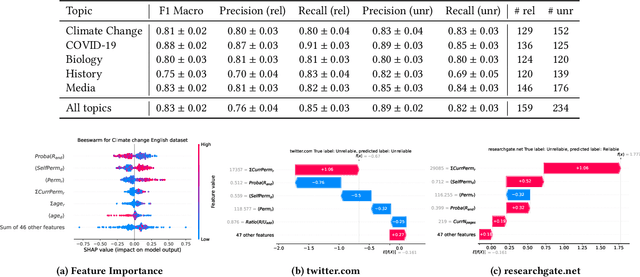
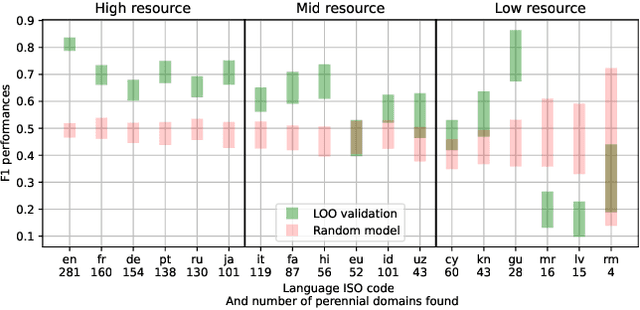
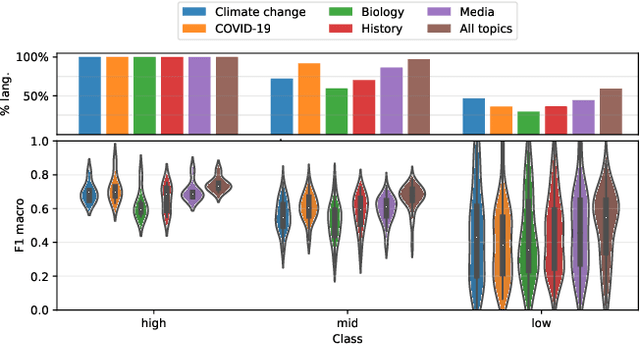
Over the last few years, content verification through reliable sources has become a fundamental need to combat disinformation. Here, we present a language-agnostic model designed to assess the reliability of sources across multiple language editions of Wikipedia. Utilizing editorial activity data, the model evaluates source reliability within different articles of varying controversiality such as Climate Change, COVID-19, History, Media, and Biology topics. Crafting features that express domain usage across articles, the model effectively predicts source reliability, achieving an F1 Macro score of approximately 0.80 for English and other high-resource languages. For mid-resource languages, we achieve 0.65 while the performance of low-resource languages varies; in all cases, the time the domain remains present in the articles (which we dub as permanence) is one of the most predictive features. We highlight the challenge of maintaining consistent model performance across languages of varying resource levels and demonstrate that adapting models from higher-resource languages can improve performance. This work contributes not only to Wikipedia's efforts in ensuring content verifiability but in ensuring reliability across diverse user-generated content in various language communities.
Quantitative Information Extraction from Humanitarian Documents
Aug 09, 2024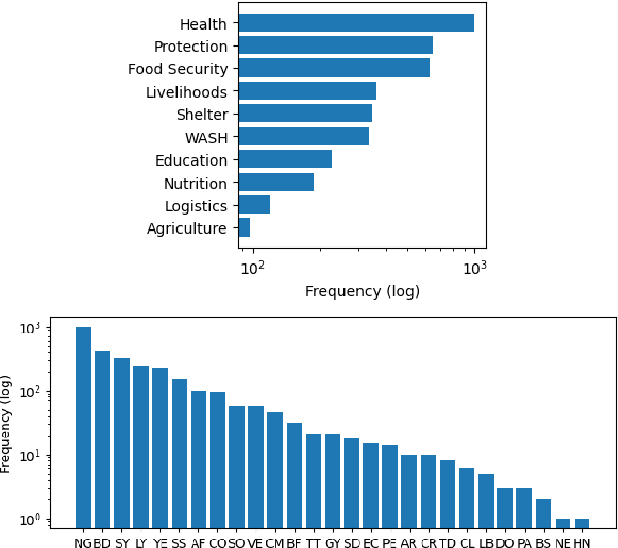
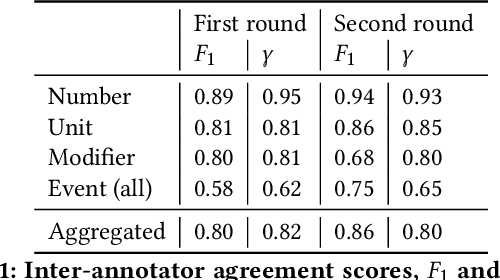


Humanitarian action is accompanied by a mass of reports, summaries, news, and other documents. To guide its activities, important information must be quickly extracted from such free-text resources. Quantities, such as the number of people affected, amount of aid distributed, or the extent of infrastructure damage, are central to emergency response and anticipatory action. In this work, we contribute an annotated dataset for the humanitarian domain for the extraction of such quantitative information, along side its important context, including units it refers to, any modifiers, and the relevant event. Further, we develop a custom Natural Language Processing pipeline to extract the quantities alongside their units, and evaluate it in comparison to baseline and recent literature. The proposed model achieves a consistent improvement in the performance, especially in the documents pertaining to the Dominican Republic and select African countries. We make the dataset and code available to the research community to continue the improvement of NLP tools for the humanitarian domain.
A Novel Lexicon for the Moral Foundation of Liberty
Jul 16, 2024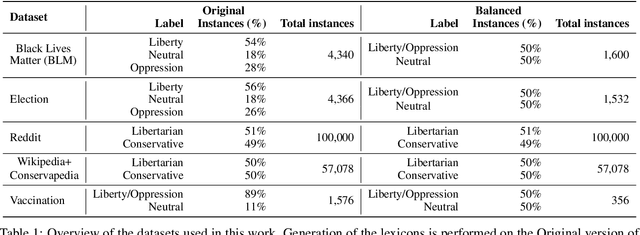
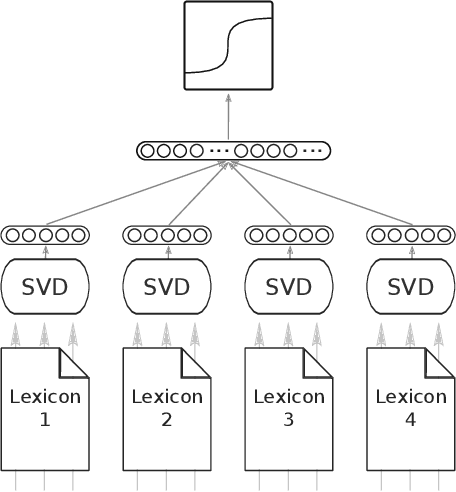

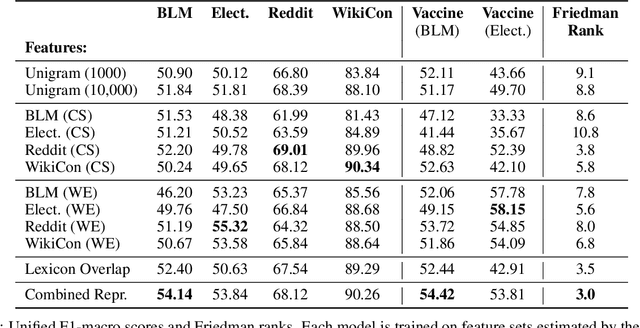
The moral value of liberty is a central concept in our inference system when it comes to taking a stance towards controversial social issues such as vaccine hesitancy, climate change, or the right to abortion. Here, we propose a novel Liberty lexicon evaluated on more than 3,000 manually annotated data both in in- and out-of-domain scenarios. As a result of this evaluation, we produce a combined lexicon that constitutes the main outcome of this work. This final lexicon incorporates information from an ensemble of lexicons that have been generated using word embedding similarity (WE) and compositional semantics (CS). Our key contributions include enriching the liberty annotations, developing a robust liberty lexicon for broader application, and revealing the complexity of expressions related to liberty across different platforms. Through the evaluation, we show that the difficulty of the task calls for designing approaches that combine knowledge, in an effort of improving the representations of learning systems.
MoralBERT: Detecting Moral Values in Social Discourse
Mar 12, 2024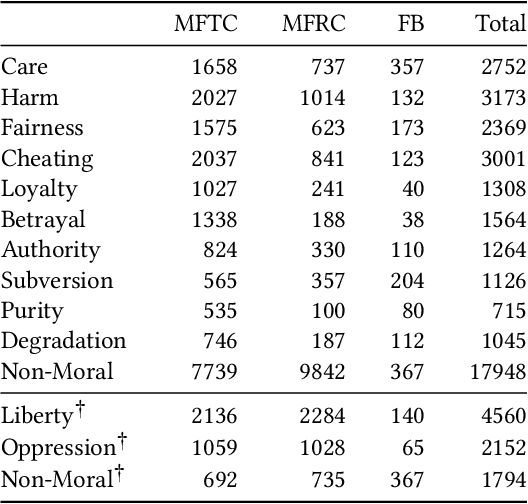
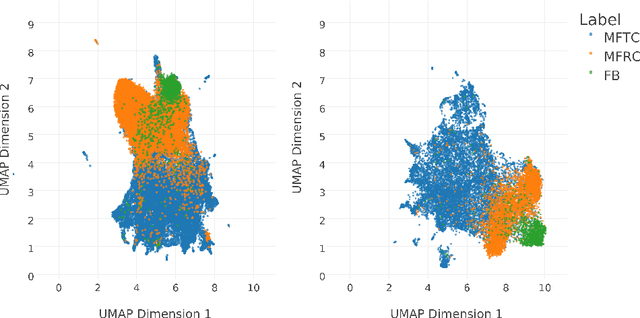
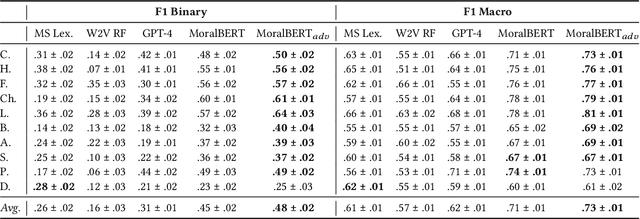
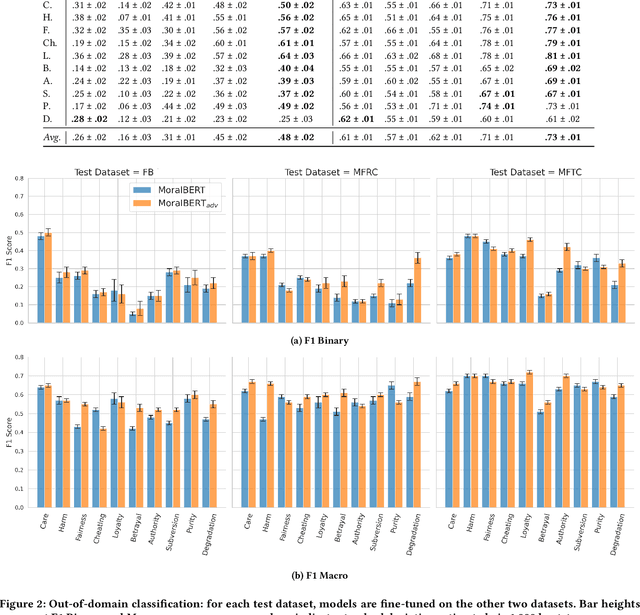
Morality plays a fundamental role in how we perceive information while greatly influencing our decisions and judgements. Controversial topics, including vaccination, abortion, racism, and sexuality, often elicit opinions and attitudes that are not solely based on evidence but rather reflect moral worldviews. Recent advances in natural language processing have demonstrated that moral values can be gauged in human-generated textual content. Here, we design a range of language representation models fine-tuned to capture exactly the moral nuances in text, called MoralBERT. We leverage annotated moral data from three distinct sources: Twitter, Reddit, and Facebook user-generated content covering various socially relevant topics. This approach broadens linguistic diversity and potentially enhances the models' ability to comprehend morality in various contexts. We also explore a domain adaptation technique and compare it to the standard fine-tuned BERT model, using two different frameworks for moral prediction: single-label and multi-label. We compare in-domain approaches with conventional models relying on lexicon-based techniques, as well as a Machine Learning classifier with Word2Vec representation. Our results showed that in-domain prediction models significantly outperformed traditional models. While the single-label setting reaches a higher accuracy than previously achieved for the task when using BERT pretrained models. Experiments in an out-of-domain setting, instead, suggest that further work is needed for existing domain adaptation techniques to generalise between different social media platforms, especially for the multi-label task. The investigations and outcomes from this study pave the way for further exploration, enabling a more profound comprehension of moral narratives about controversial social issues.
Leave no Place Behind: Improved Geolocation in Humanitarian Documents
Sep 06, 2023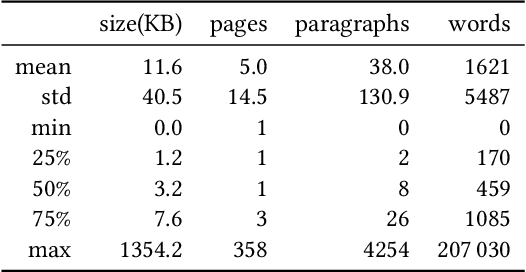

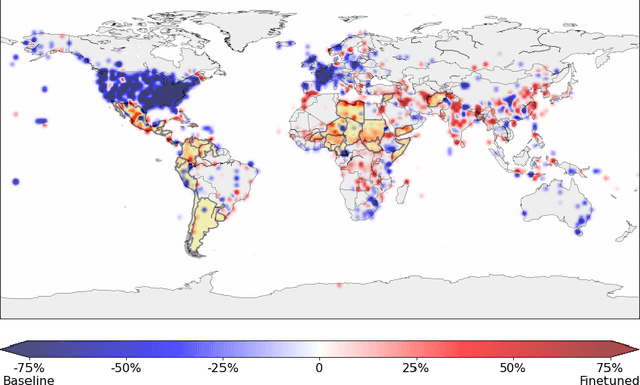
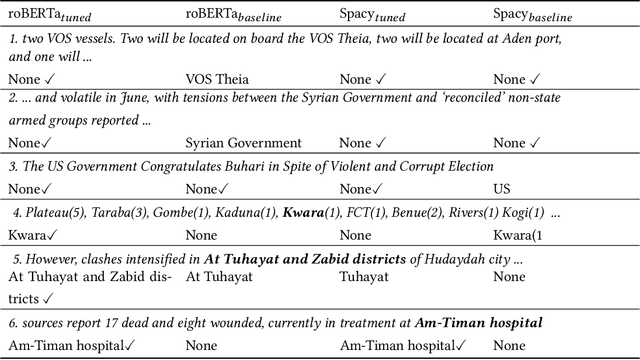
Geographical location is a crucial element of humanitarian response, outlining vulnerable populations, ongoing events, and available resources. Latest developments in Natural Language Processing may help in extracting vital information from the deluge of reports and documents produced by the humanitarian sector. However, the performance and biases of existing state-of-the-art information extraction tools are unknown. In this work, we develop annotated resources to fine-tune the popular Named Entity Recognition (NER) tools Spacy and roBERTa to perform geotagging of humanitarian texts. We then propose a geocoding method FeatureRank which links the candidate locations to the GeoNames database. We find that not only does the humanitarian-domain data improves the performance of the classifiers (up to F1 = 0.92), but it also alleviates some of the bias of the existing tools, which erroneously favor locations in the Western countries. Thus, we conclude that more resources from non-Western documents are necessary to ensure that off-the-shelf NER systems are suitable for the deployment in the humanitarian sector.
LibertyMFD: A Lexicon to Assess the Moral Foundation of Liberty
Sep 14, 2022

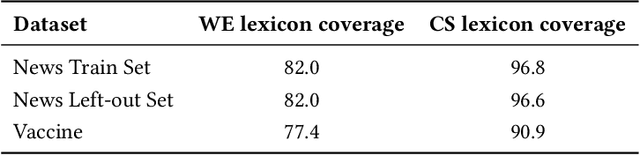

Quantifying the moral narratives expressed in the user-generated text, news, or public discourses is fundamental for understanding individuals' concerns and viewpoints and preventing violent protests and social polarisation. The Moral Foundation Theory (MFT) was developed to operationalise morality in a five-dimensional scale system. Recent developments of the theory urged for the introduction of a new foundation, the Liberty Foundation. Being only recently added to the theory, there are no available linguistic resources to assess whether liberty is present in text corpora. Given its importance to current social issues such as the vaccination debate, we propose two data-driven approaches, deriving two candidate lexicons generated based on aligned documents from online news sources with different worldviews. After extensive experimentation, we contribute to the research community a novel lexicon that assesses the liberty moral foundation in the way individuals with contrasting viewpoints express themselves through written text. The LibertyMFD dictionary can be a valuable tool for policymakers to understand diverse viewpoints on controversial social issues such as vaccination, abortion, or even uprisings, as they happen and on a large scale.
* GoodIT '22: Proceedings of the 2022 ACM Conference on Information Technology for Social Good. GoodIT'22, September 7-9, 2022, Limassol, Cyprus
"More Than Words": Linking Music Preferences and Moral Values Through Lyrics
Sep 02, 2022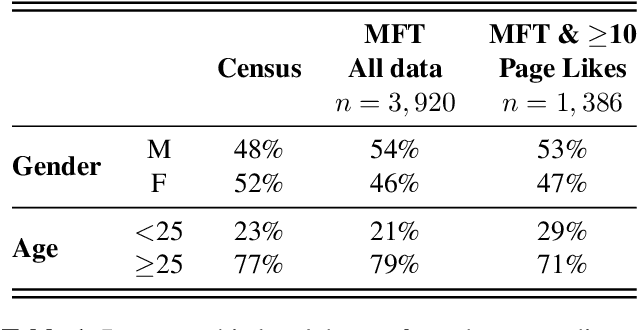
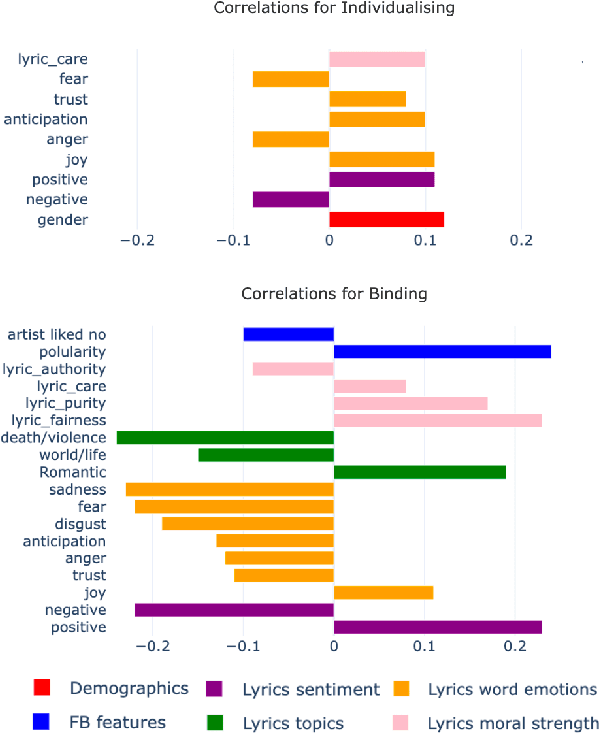
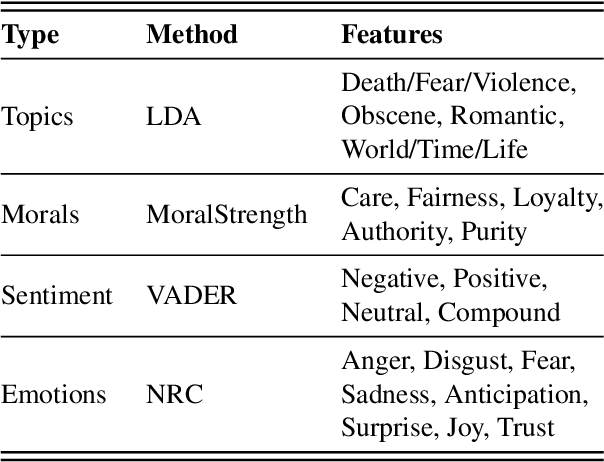
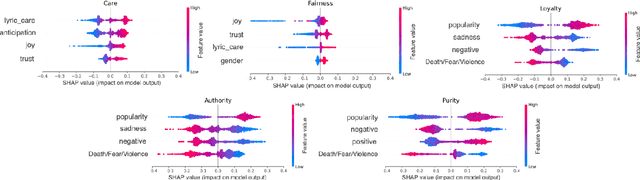
This study explores the association between music preferences and moral values by applying text analysis techniques to lyrics. Harvesting data from a Facebook-hosted application, we align psychometric scores of 1,386 users to lyrics from the top 5 songs of their preferred music artists as emerged from Facebook Page Likes. We extract a set of lyrical features related to each song's overarching narrative, moral valence, sentiment, and emotion. A machine learning framework was designed to exploit regression approaches and evaluate the predictive power of lyrical features for inferring moral values. Results suggest that lyrics from top songs of artists people like inform their morality. Virtues of hierarchy and tradition achieve higher prediction scores ($.20 \leq r \leq .30$) than values of empathy and equality ($.08 \leq r \leq .11$), while basic demographic variables only account for a small part in the models' explainability. This shows the importance of music listening behaviours, as assessed via lyrical preferences, alone in capturing moral values. We discuss the technological and musicological implications and possible future improvements.
MoralStrength: Exploiting a Moral Lexicon and Embedding Similarity for Moral Foundations Prediction
Apr 17, 2019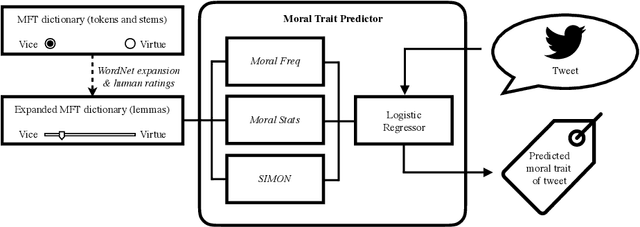
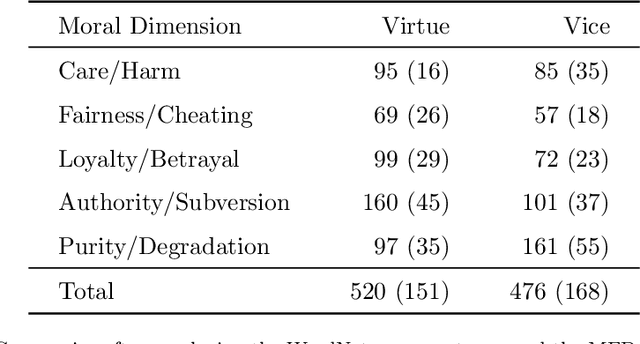
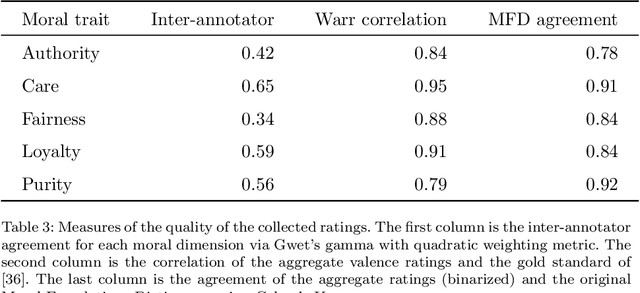
Opinions and attitudes towards controversial social and political issues are hardly ever based on evidence alone. Moral values play a fundamental role in the decision-making process of how we perceive and interpret information. The Moral Foundations Dictionary (MFD) was developed to operationalize moral values in text. In this study, we present MoralStrength, a lexicon of approximately 1,000 lemmas, obtained as an extension of the Moral Foundations Dictionary, based on WordNet synsets. Moreover, for each lemma it provides with a crowdsourced numeric assessment of Moral Valence, indicating the strength with which a lemma is expressing the specific value. We evaluated the predictive potentials of this moral lexicon, defining three utilization approaches of increasing complexity, ranging from statistical properties of the lexicon to a deep learning approach of word embeddings based on semantic similarity. Logistic regression models trained on the features extracted from MoralStrength, significantly outperformed the current state-of-the-art, reaching an F1-score of 87.6% over the previous 62.4% (p-value<0.01). Such findings pave the way for further research, allowing for an in-depth understanding of moral narratives in text for a wide range of social issues.
Predicting Demographics, Moral Foundations, and Human Values from Digital Behaviors
Nov 02, 2018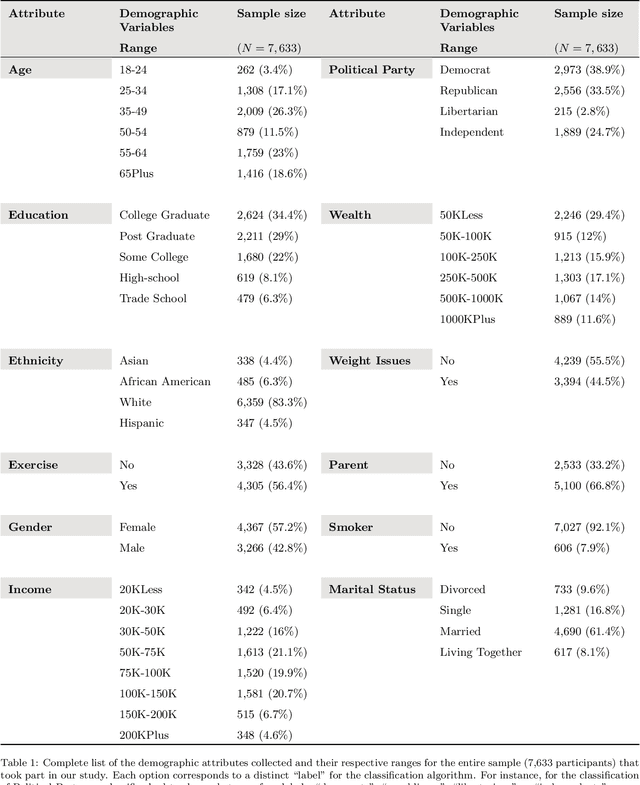
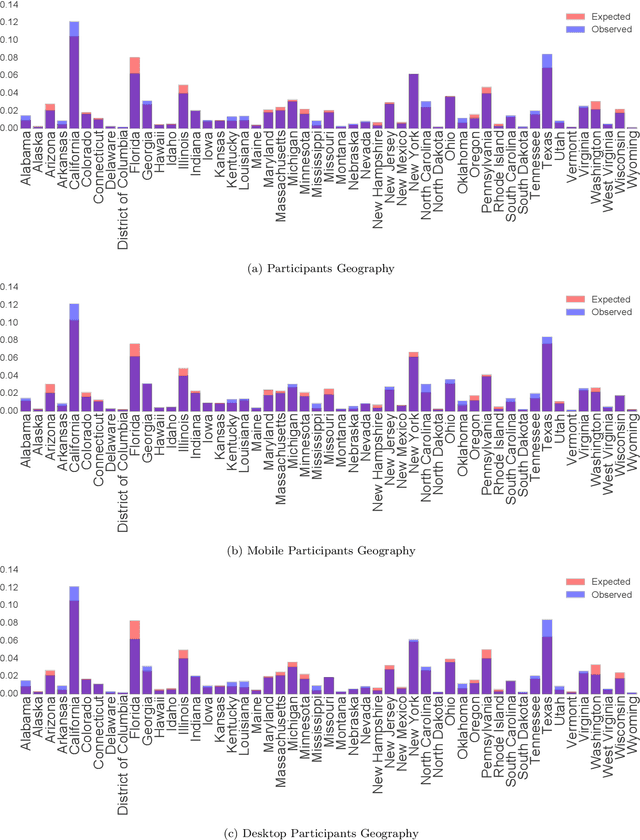
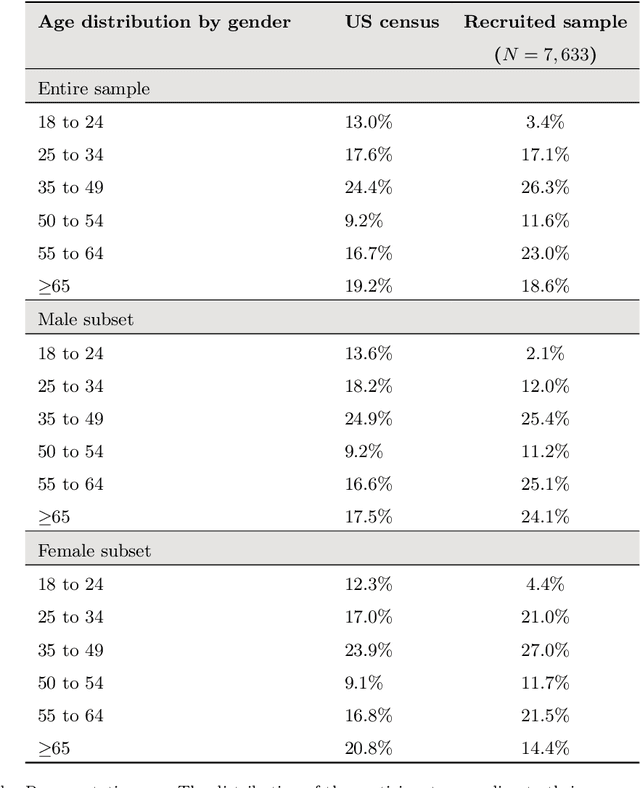
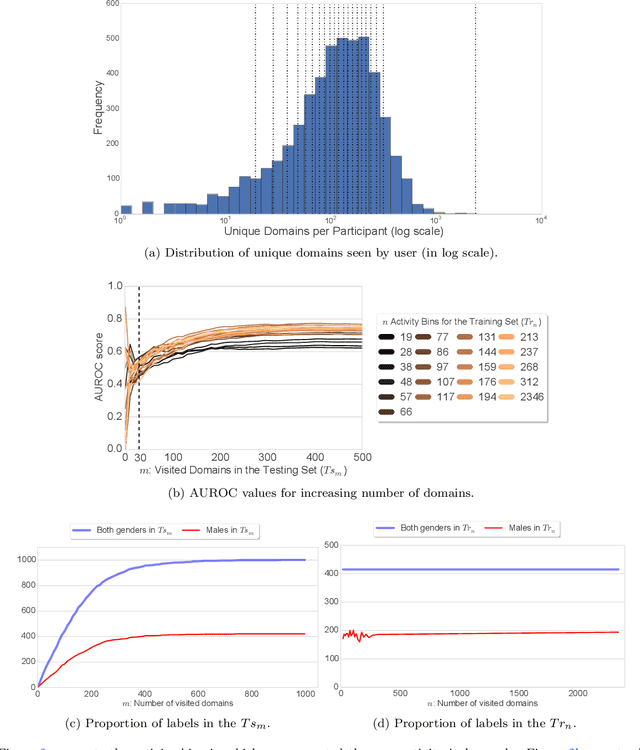
Personal electronic devices such as smartphones give access to a broad range of behavioral signals that can be used to learn about the characteristics and preferences of individuals. In this study we explore the connection between demographic and psychological attributes and digital records for a cohort of 7,633 people, closely representative of the US population with respect to gender, age, geographical distribution, education, and income. We collected self-reported assessments on validated psychometric questionnaires based on both the Moral Foundations and Basic Human Values theories, and combined this information with passively-collected multi-modal digital data from web browsing behavior, smartphone usage and demographic data. Then, we designed a machine learning framework to infer both the demographic and psychological attributes from the behavioral data. In a cross-validated setting, our model is found to predict demographic attributes with good accuracy (weighted AUC scores of 0.90 for gender, 0.71 for age, 0.74 for ethnicity). Our weighted AUC scores for Moral Foundation attributes (0.66) and Human Values attributes (0.60) suggest that accurate prediction of complex psychometric attributes is more challenging but feasible. This connection might prove useful for designing personalized services, communication strategies, and interventions, and can be used to sketch a portrait of people with similar worldviews.