 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitative Information Extraction from Humanitarian Documents
Aug 09, 2024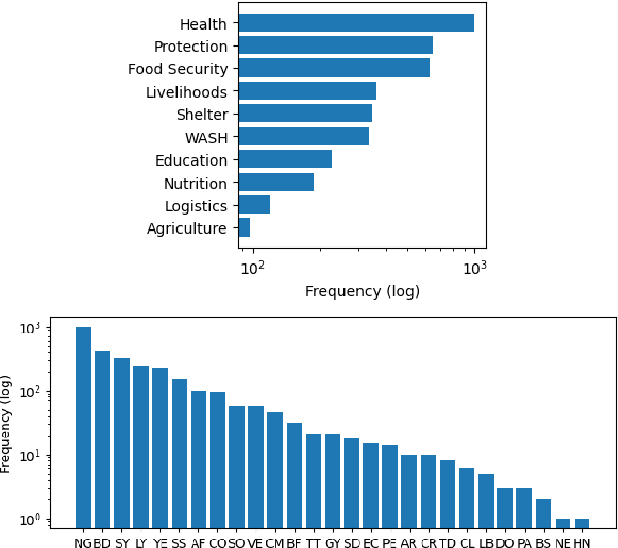
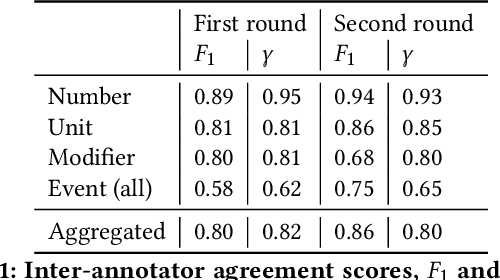


Humanitarian action is accompanied by a mass of reports, summaries, news, and other documents. To guide its activities, important information must be quickly extracted from such free-text resources. Quantities, such as the number of people affected, amount of aid distributed, or the extent of infrastructure damage, are central to emergency response and anticipatory action. In this work, we contribute an annotated dataset for the humanitarian domain for the extraction of such quantitative information, along side its important context, including units it refers to, any modifiers, and the relevant event. Further, we develop a custom Natural Language Processing pipeline to extract the quantities alongside their units, and evaluate it in comparison to baseline and recent literature. The proposed model achieves a consistent improvement in the performance, especially in the documents pertaining to the Dominican Republic and select African countries. We make the dataset and code available to the research community to continue the improvement of NLP tools for the humanitarian domain.