 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Language-Model Framework for Automated Humanitarian Situation Reporting
Dec 22, 2025Timely and accurate situational reports are essential for humanitarian decision-making, yet current workflows remain largely manual, resource intensive, and inconsistent. We present a fully automated framework that uses large language models (LLMs) to transform heterogeneous humanitarian documents into structured and evidence-grounded reports. The system integrates semantic text clustering, automatic question generation, retrieval augmented answer extraction with citations, multi-level summarization, and executive summary generation, supported by internal evaluation metrics that emulate expert reasoning. We evaluated the framework across 13 humanitarian events, including natural disasters and conflicts, using more than 1,100 documents from verified sources such as ReliefWeb. The generated questions achieved 84.7 percent relevance, 84.0 percent importance, and 76.4 percent urgency. The extracted answers reached 86.3 percent relevance, with citation precision and recall both exceeding 76 percent. Agreement between human and LLM based evaluations surpassed an F1 score of 0.80. Comparative analysis shows that the proposed framework produces reports that are more structured, interpretable, and actionable than existing baselines. By combining LLM reasoning with transparent citation linking and multi-level evaluation, this study demonstrates that generative AI can autonomously produce accurate, verifiable, and operationally useful humanitarian situation reports.
Language-Agnostic Modeling of Source Reliability on Wikipedia
Oct 24, 2024
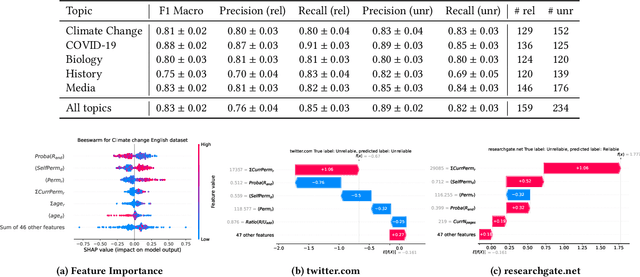
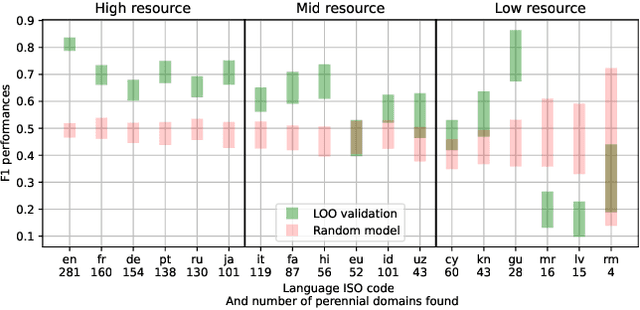
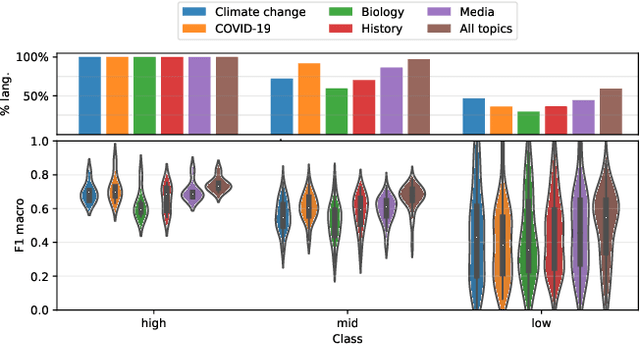
Over the last few years, content verification through reliable sources has become a fundamental need to combat disinformation. Here, we present a language-agnostic model designed to assess the reliability of sources across multiple language editions of Wikipedia. Utilizing editorial activity data, the model evaluates source reliability within different articles of varying controversiality such as Climate Change, COVID-19, History, Media, and Biology topics. Crafting features that express domain usage across articles, the model effectively predicts source reliability, achieving an F1 Macro score of approximately 0.80 for English and other high-resource languages. For mid-resource languages, we achieve 0.65 while the performance of low-resource languages varies; in all cases, the time the domain remains present in the articles (which we dub as permanence) is one of the most predictive features. We highlight the challenge of maintaining consistent model performance across languages of varying resource levels and demonstrate that adapting models from higher-resource languages can improve performance. This work contributes not only to Wikipedia's efforts in ensuring content verifiability but in ensuring reliability across diverse user-generated content in various language communities.
Quantitative Information Extraction from Humanitarian Documents
Aug 09, 2024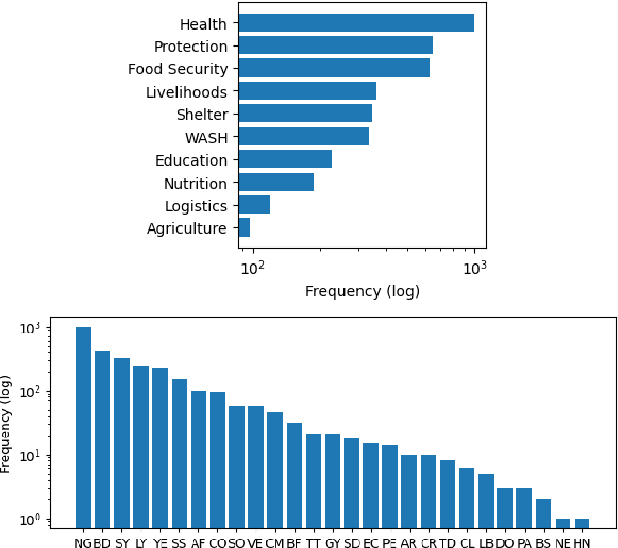
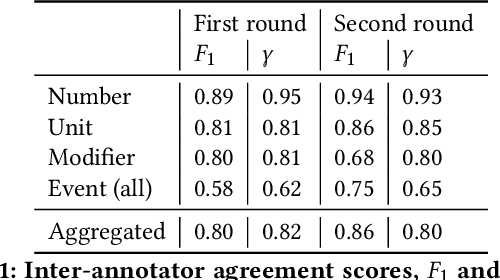


Humanitarian action is accompanied by a mass of reports, summaries, news, and other documents. To guide its activities, important information must be quickly extracted from such free-text resources. Quantities, such as the number of people affected, amount of aid distributed, or the extent of infrastructure damage, are central to emergency response and anticipatory action. In this work, we contribute an annotated dataset for the humanitarian domain for the extraction of such quantitative information, along side its important context, including units it refers to, any modifiers, and the relevant event. Further, we develop a custom Natural Language Processing pipeline to extract the quantities alongside their units, and evaluate it in comparison to baseline and recent literature. The proposed model achieves a consistent improvement in the performance, especially in the documents pertaining to the Dominican Republic and select African countries. We make the dataset and code available to the research community to continue the improvement of NLP tools for the humanitarian domain.
Leave no Place Behind: Improved Geolocation in Humanitarian Documents
Sep 06, 2023

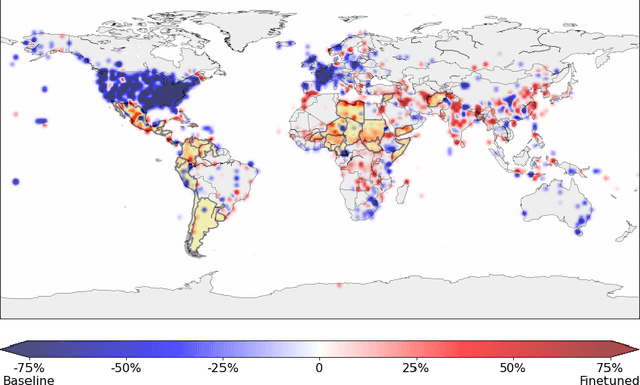
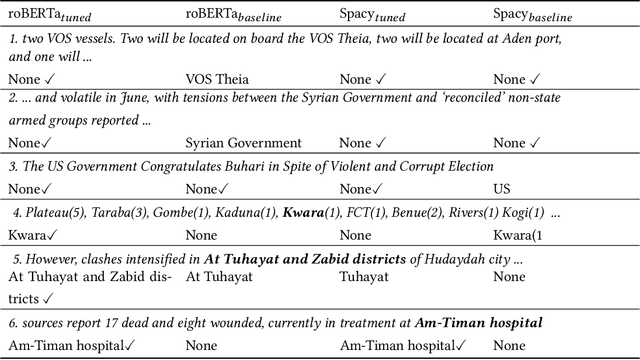
Geographical location is a crucial element of humanitarian response, outlining vulnerable populations, ongoing events, and available resources. Latest developments in Natural Language Processing may help in extracting vital information from the deluge of reports and documents produced by the humanitarian sector. However, the performance and biases of existing state-of-the-art information extraction tools are unknown. In this work, we develop annotated resources to fine-tune the popular Named Entity Recognition (NER) tools Spacy and roBERTa to perform geotagging of humanitarian texts. We then propose a geocoding method FeatureRank which links the candidate locations to the GeoNames database. We find that not only does the humanitarian-domain data improves the performance of the classifiers (up to F1 = 0.92), but it also alleviates some of the bias of the existing tools, which erroneously favor locations in the Western countries. Thus, we conclude that more resources from non-Western documents are necessary to ensure that off-the-shelf NER systems are suitable for the deployment in the humanitarian sector.
Comfort Foods and Community Connectedness: Investigating Diet Change during COVID-19 Using YouTube Videos on Twitter
May 19, 2023



Unprecedented lockdowns at the start of the COVID-19 pandemic have drastically changed the routines of millions of people, potentially impacting important health-related behaviors. In this study, we use YouTube videos embedded in tweets about diet, exercise and fitness posted before and during COVID-19 to investigate the influence of the pandemic lockdowns on diet and nutrition. In particular, we examine the nutritional profile of the foods mentioned in the transcript, description and title of each video in terms of six macronutrients (protein, energy, fat, sodium, sugar, and saturated fat). These macronutrient values were further linked to demographics to assess if there are specific effects on those potentially having insufficient access to healthy sources of food. Interrupted time series analysis revealed a considerable shift in the aggregated macronutrient scores before and during COVID-19. In particular, whereas areas with lower incomes showed decrease in energy, fat, and saturated fat, those with higher percentage of African Americans showed an elevation in sodium. Word2Vec word similarities and odds ratio analysis suggested a shift from popular diets and lifestyle bloggers before the lockdowns to the interest in a variety of healthy foods, communal sharing of quick and easy recipes, as well as a new emphasis on comfort foods. To the best of our knowledge, this work is novel in terms of linking attention signals in tweets, content of videos, their nutrients profile, and aggregate demographics of the users. The insights made possible by this combination of resources are important for monitoring the secondary health effects of social distancing, and informing social programs designed to alleviate these effects.
Googling for Abortion: Search Engine Mediation of Abortion Accessibility in the United States
Feb 23, 2022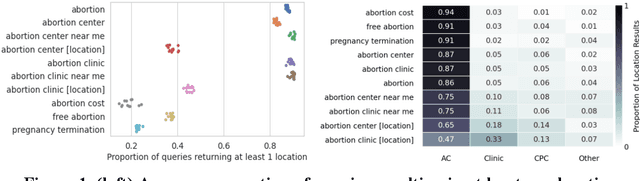
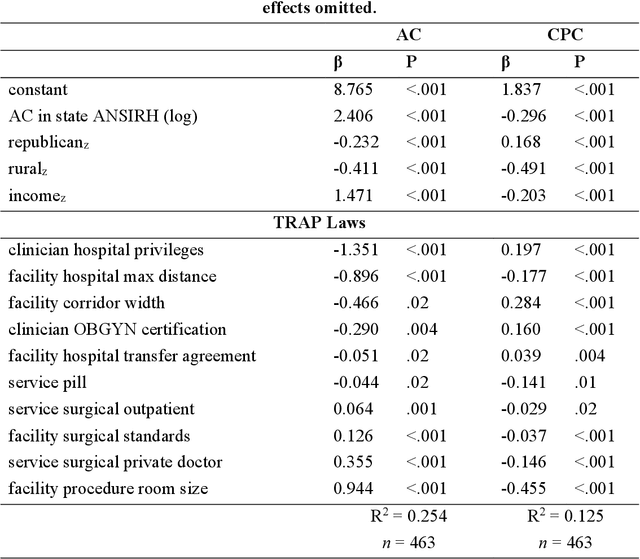
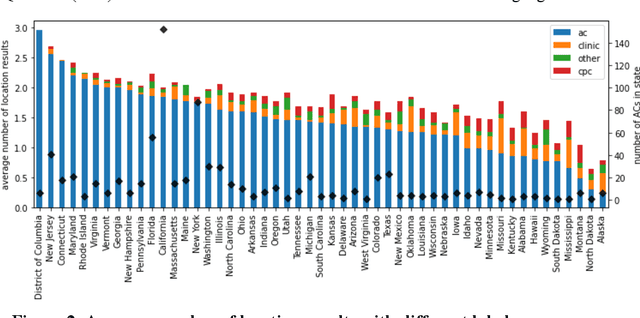
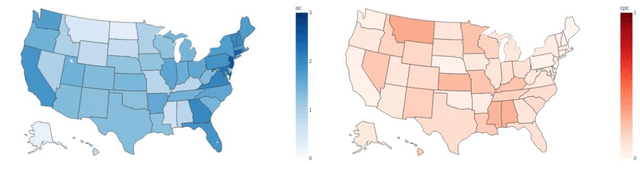
Among the myriad barriers to abortion access, crisis pregnancy centers (CPCs) pose an additional difficulty by targeting women with unexpected or "crisis" pregnancies in order to dissuade them from the procedure. Web search engines may prove to be another barrier, being in a powerful position to direct their users to health information, and above all, health services. In this study we ask, to what degree does Google Search provide quality responses to users searching for an abortion provider, specifically in terms of directing them to abortion clinics (ACs) or CPCs. To answer this question, we considered the scenario of a woman searching for abortion services online, and conducted 10 abortion-related queries from 467 locations across the United States once a week for 14 weeks. Overall, among Google's location results that feature businesses alongside a map, 79.4% were ACs, and 6.9% were CPCs. When an AC was returned, it was the closest known AC location 86.9% of the time. However, when a CPC appeared in a result set, it was the closest one to the search location 75.9% of the time. Examining correlates of AC results, we found that fewer AC results were returned for searches from poorer and rural areas, and those with TRAP laws governing AC facility and clinician requirements. We also observed that Google's performance on our queries significantly improved following a major algorithm update. These results have important implications concerning health access quality and equity, both for individual users and public health policy.
Developing Annotated Resources for Internal Displacement Monitoring
Apr 12, 2021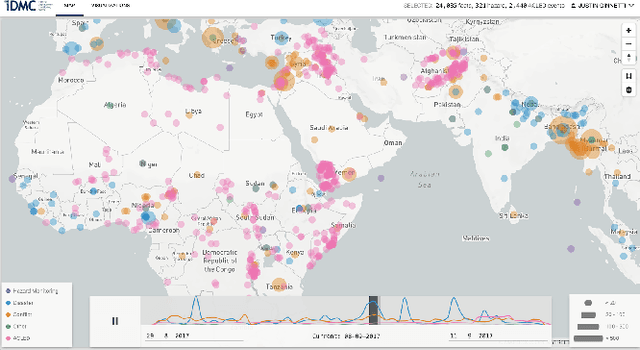

This paper describes in details the design and development of a novel annotation framework and of annotated resources for Internal Displacement, as the outcome of a collaboration with the Internal Displacement Monitoring Centre, aimed at improving the accuracy of their monitoring platform IDETECT. The schema includes multi-faceted description of the events, including cause, quantity of people displaced, location and date. Higher-order facets aimed at improving the information extraction, such as document relevance and type, are proposed. We also report a case study of machine learning application to the document classification tasks. Finally, we discuss the importance of standardized schema in dataset benchmark development and its impact on the development of reliable disaster monitoring infrastructure.
Kissing Cuisines: Exploring Worldwide Culinary Habits on the Web
Apr 25, 2017
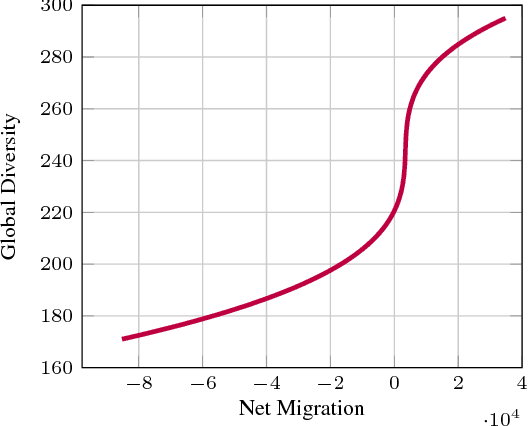
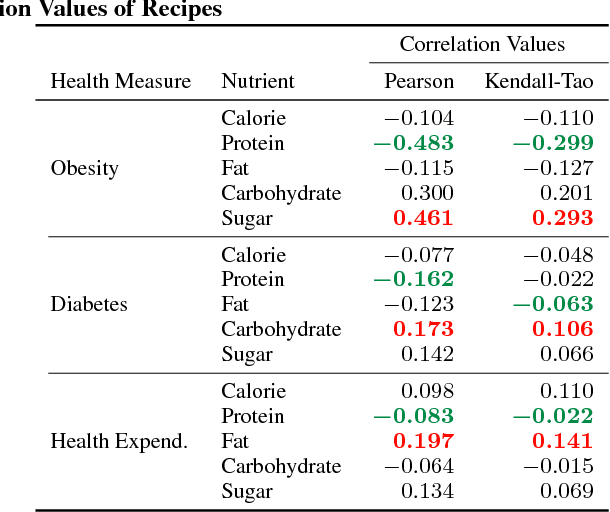
Food and nutrition occupy an increasingly prevalent space on the web, and dishes and recipes shared online provide an invaluable mirror into culinary cultures and attitudes around the world. More specifically, ingredients, flavors, and nutrition information become strong signals of the taste preferences of individuals and civilizations. However, there is little understanding of these palate varieties. In this paper, we present a large-scale study of recipes published on the web and their content, aiming to understand cuisines and culinary habits around the world. Using a database of more than 157K recipes from over 200 different cuisines, we analyze ingredients, flavors, and nutritional values which distinguish dishes from different regions, and use this knowledge to assess the predictability of recipes from different cuisines. We then use country health statistics to understand the relation between these factors and health indicators of different nations, such as obesity, diabetes, migration, and health expenditure. Our results confirm the strong effects of geographical and cultural similarities on recipes, health indicators, and culinary preferences across the globe.
Controversy and Sentiment in Online News
Sep 29, 2014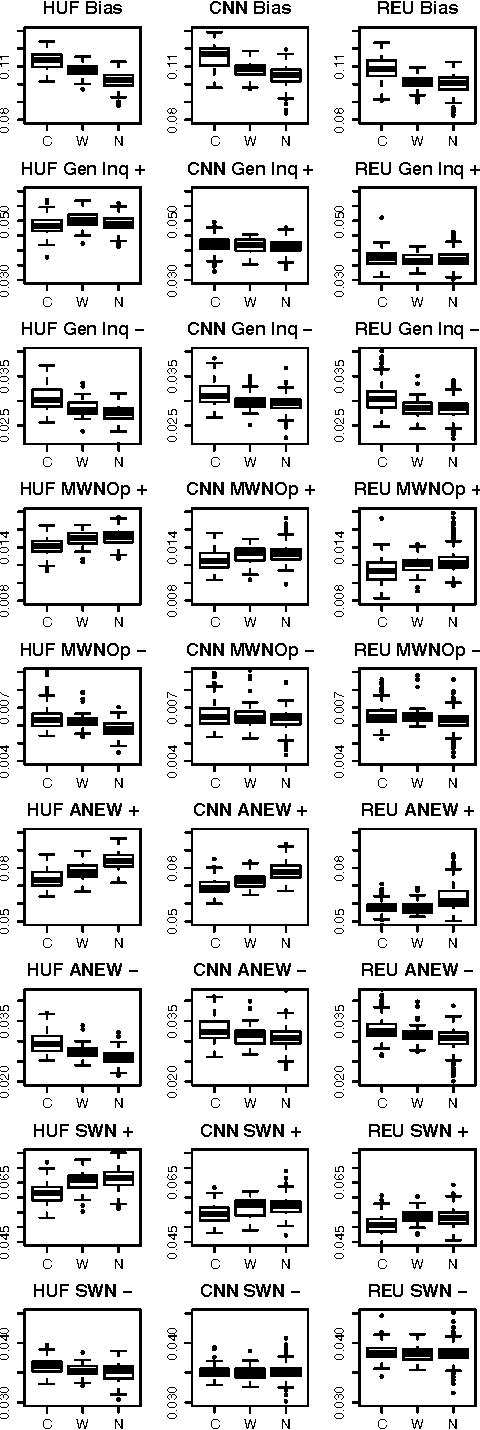


How do news sources tackle controversial issues? In this work, we take a data-driven approach to understand how controversy interplays with emotional expression and biased language in the news. We begin by introducing a new dataset of controversial and non-controversial terms collected using crowdsourcing. Then, focusing on 15 major U.S. news outlets, we compare millions of articles discussing controversial and non-controversial issues over a span of 7 months. We find that in general, when it comes to controversial issues, the use of negative affect and biased language is prevalent, while the use of strong emotion is tempered. We also observe many differences across news sources. Using these findings, we show that we can indicate to what extent an issue is controversial, by comparing it with other issues in terms of how they are portrayed across different media.