 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Recipes for Efficient and Compact Vision-Language Models
Mar 17, 2026Deploying vision-language models (VLMs) in resource-constrained settings demands low latency and high throughput, yet existing compact VLMs often fall short of the inference speedups their smaller parameter counts suggest. To explain this discrepancy, we conduct an empirical end-to-end efficiency analysis and systematically profile inference to identify the dominant bottlenecks. Based on these findings, we develop optimization recipes tailored to compact VLMs that substantially reduce latency while preserving accuracy. These techniques cut time to first token (TTFT) by 53% on InternVL3-2B and by 93% on SmolVLM-256M. Our recipes are broadly applicable across both VLM architectures and common serving frameworks, providing practical guidance for building efficient VLM systems. Beyond efficiency, we study how to extend compact VLMs with structured perception outputs and introduce the resulting model family, ArgusVLM. Across diverse benchmarks, ArgusVLM achieves strong performance while maintaining a compact and efficient design.
StelLA: Subspace Learning in Low-rank Adaptation using Stiefel Manifold
Oct 02, 2025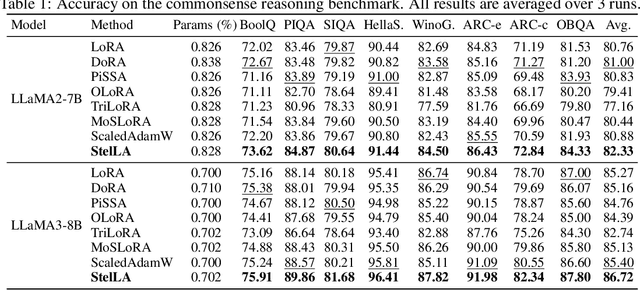
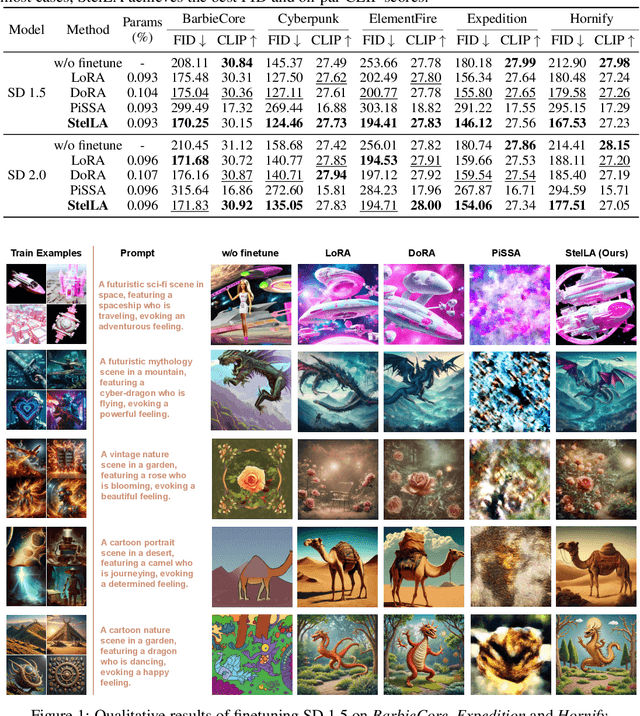
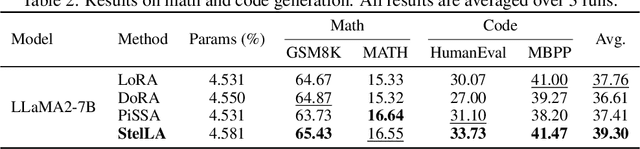
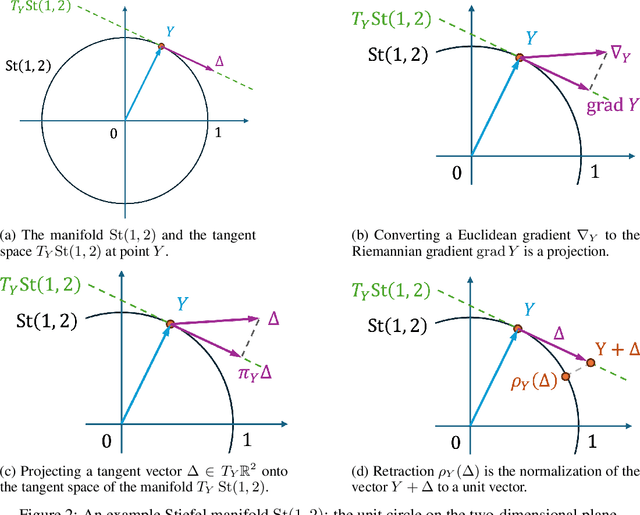
Low-rank adaptation (LoRA) has been widely adopted as a parameter-efficient technique for fine-tuning large-scale pre-trained models. However, it still lags behind full fine-tuning in performance, partly due to its insufficient exploitation of the geometric structure underlying low-rank manifolds. In this paper, we propose a geometry-aware extension of LoRA that uses a three-factor decomposition $U\!SV^\top$. Analogous to the structure of singular value decomposition (SVD), it separates the adapter's input and output subspaces, $V$ and $U$, from the scaling factor $S$. Our method constrains $U$ and $V$ to lie on the Stiefel manifold, ensuring their orthonormality throughout the training. To optimize on the Stiefel manifold, we employ a flexible and modular geometric optimization design that converts any Euclidean optimizer to a Riemannian one. It enables efficient subspace learning while remaining compatible with existing fine-tuning pipelines. Empirical results across a wide range of downstream tasks, including commonsense reasoning, math and code generation, image classification, and image generation, demonstrate the superior performance of our approach against the recent state-of-the-art variants of LoRA. Code is available at https://github.com/SonyResearch/stella.
Masked Differential Privacy
Oct 22, 2024



Privacy-preserving computer vision is an important emerging problem in machine learning and artificial intelligence. The prevalent methods tackling this problem use differential privacy or anonymization and obfuscation techniques to protect the privacy of individuals. In both cases, the utility of the trained model is sacrificed heavily in this process. In this work, we propose an effective approach called masked differential privacy (MaskDP), which allows for controlling sensitive regions where differential privacy is applied, in contrast to applying DP on the entire input. Our method operates selectively on the data and allows for defining non-sensitive spatio-temporal regions without DP application or combining differential privacy with other privacy techniques within data samples. Experiments on four challenging action recognition datasets demonstrate that our proposed techniques result in better utility-privacy trade-offs compared to standard differentially private training in the especially demanding $\epsilon<1$ regime.
ProGAP: Progressive Graph Neural Networks with Differential Privacy Guarantees
Apr 18, 2023Graph Neural Networks (GNNs) have become a popular tool for learning on graphs, but their widespread use raises privacy concerns as graph data can contain personal or sensitive information. Differentially private GNN models have been recently proposed to preserve privacy while still allowing for effective learning over graph-structured datasets. However, achieving an ideal balance between accuracy and privacy in GNNs remains challenging due to the intrinsic structural connectivity of graphs. In this paper, we propose a new differentially private GNN called ProGAP that uses a progressive training scheme to improve such accuracy-privacy trade-offs. Combined with the aggregation perturbation technique to ensure differential privacy, ProGAP splits a GNN into a sequence of overlapping submodels that are trained progressively, expanding from the first submodel to the complete model. Specifically, each submodel is trained over the privately aggregated node embeddings learned and cached by the previous submodels, leading to an increased expressive power compared to previous approaches while limiting the incurred privacy costs. We formally prove that ProGAP ensures edge-level and node-level privacy guarantees for both training and inference stages, and evaluate its performance on benchmark graph datasets. Experimental results demonstrate that ProGAP can achieve up to 5%-10% higher accuracy than existing state-of-the-art differentially private GNNs.
GAP: Differentially Private Graph Neural Networks with Aggregation Perturbation
Mar 02, 2022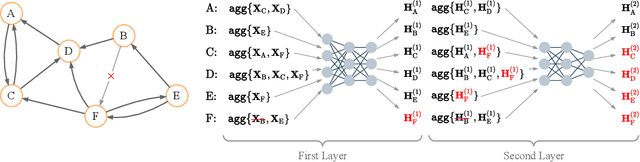

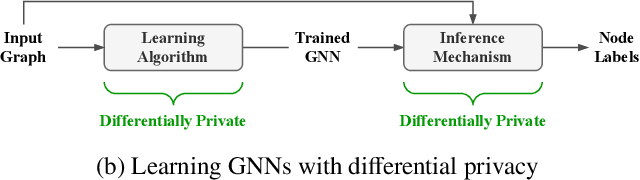

Graph Neural Networks (GNNs) are powerful models designed for graph data that learn node representation by recursively aggregating information from each node's local neighborhood. However, despite their state-of-the-art performance in predictive graph-based applications, recent studies have shown that GNNs can raise significant privacy concerns when graph data contain sensitive information. As a result, in this paper, we study the problem of learning GNNs with Differential Privacy (DP). We propose GAP, a novel differentially private GNN that safeguards the privacy of nodes and edges using aggregation perturbation, i.e., adding calibrated stochastic noise to the output of the GNN's aggregation function, which statistically obfuscates the presence of a single edge (edge-level privacy) or a single node and all its adjacent edges (node-level privacy). To circumvent the accumulation of privacy cost at every forward pass of the model, we tailor the GNN architecture to the specifics of private learning. In particular, we first precompute private aggregations by recursively applying neighborhood aggregation and perturbing the output of each aggregation step. Then, we privately train a deep neural network on the resulting perturbed aggregations for any node-wise classification task. A major advantage of GAP over previous approaches is that we guarantee edge-level and node-level DP not only for training, but also at inference time with no additional costs beyond the training's privacy budget. We theoretically analyze the formal privacy guarantees of GAP using R\'enyi DP. Empirical experiments conducted over three real-world graph datasets demonstrate that GAP achieves a favorable privacy-accuracy trade-off and significantly outperforms existing approaches.
When Differential Privacy Meets Graph Neural Networks
Jun 30, 2020

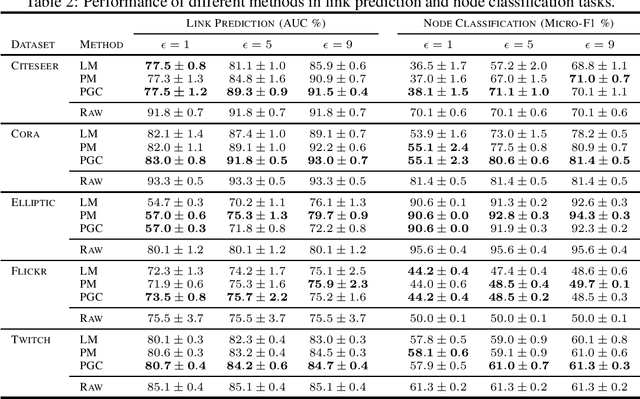
Graph Neural Networks have demonstrated superior performance in learning graph representations for several subsequent downstream inference tasks. However, learning over graph data types can raise privacy concerns when nodes represent people or human-related variables that involve personal information about individuals. Previous works have presented various techniques for privacy-preserving deep learning over non-relational data, such as image, audio, video, and text, but there is less work addressing the privacy issues involved in applying deep learning algorithms on graphs. As a result and for the first time, in this paper, we develop a privacy-preserving learning algorithm with formal privacy guarantees for Graph Convolutional Networks (GCNs) based on Local Differential Privacy (LDP) to tackle the problem of node-level privacy, where graph nodes have potentially sensitive features that need to be kept private, but they could be beneficial for learning rich node representations in a centralized learning setting. Specifically, we propose an LDP algorithm in which a central server can communicate with graph nodes to privately collect their data and estimate the graph convolution layer of a GCN. We then analyze the theoretical characteristics of the method and compare it with state-of-the-art mechanisms. Experimental results over real-world graph datasets demonstrate the effectiveness of the proposed method for both privacy-preserving node classification and link prediction tasks and verify our theoretical findings.
Continuous-Time Relationship Prediction in Dynamic Heterogeneous Information Networks
Oct 08, 2018


Online social networks, World Wide Web, media and technological networks, and other types of so-called information networks are ubiquitous nowadays. These information networks are inherently heterogeneous and dynamic. They are heterogeneous as they consist of multi-typed objects and relations, and they are dynamic as they are constantly evolving over time. One of the challenging issues in such heterogeneous and dynamic environments is to forecast those relationships in the network that will appear in the future. In this paper, we try to solve the problem of continuous-time relationship prediction in dynamic and heterogeneous information networks. This implies predicting the time it takes for a relationship to appear in the future, given its features that have been extracted by considering both heterogeneity and temporal dynamics of the underlying network. To this end, we first introduce a feature extraction framework that combines the power of meta-path-based modeling and recurrent neural networks to effectively extract features suitable for relationship prediction regarding heterogeneity and dynamicity of the networks. Next, we propose a supervised non-parametric approach, called Non-Parametric Generalized Linear Model (NP-GLM), which infers the hidden underlying probability distribution of the relationship building time given its features. We then present a learning algorithm to train NP-GLM and an inference method to answer time-related queries. Extensive experiments conducted on synthetic data and three real-world datasets, namely Delicious, MovieLens, and DBLP, demonstrate the effectiveness of NP-GLM in solving continuous-time relationship prediction problem vis-a-vis competitive baselines
A Hybrid Deep Learning Architecture for Privacy-Preserving Mobile Analytics
Apr 18, 2018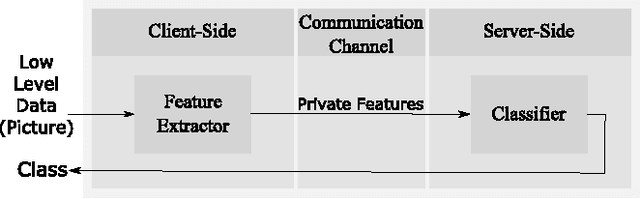
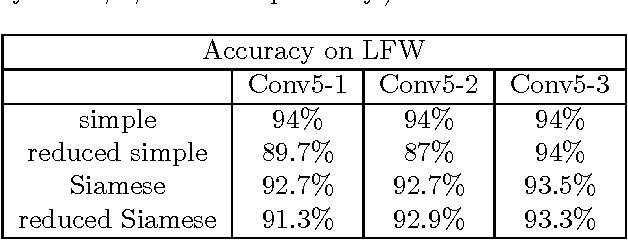
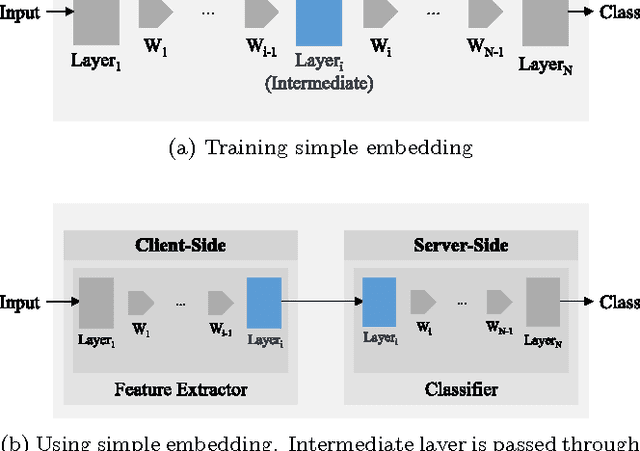
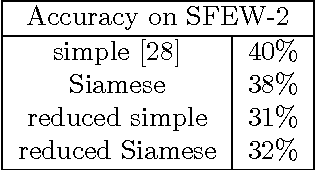
Deep Neural Networks are increasingly being used in a variety of machine learning applications applied to user data on the cloud. However, this approach introduces a number of privacy and efficiency challenges, as the cloud operator can perform secondary inferences on the available data. Recently, advances in edge processing have paved the way for more efficient, and private, data processing at the source for simple tasks and lighter models, though they remain a challenge for larger, and more complicated models. In this paper, we present a hybrid approach for breaking down large, complex deep models for cooperative, privacy-preserving analytics. We do this by breaking down the popular deep architectures and fine-tune them in a suitable way. We then evaluate the privacy benefits of this approach based on the information exposed to the cloud service. We also assess the local inference cost of different layers on a modern handset for mobile applications. Our evaluations show that by using certain kind of fine-tuning and embedding techniques and at a small processing cost, we can greatly reduce the level of information available to unintended tasks applied to the data features on the cloud, and hence achieving the desired tradeoff between privacy and performance.
NPGLM: A Non-Parametric Method for Temporal Link Prediction
Jun 21, 2017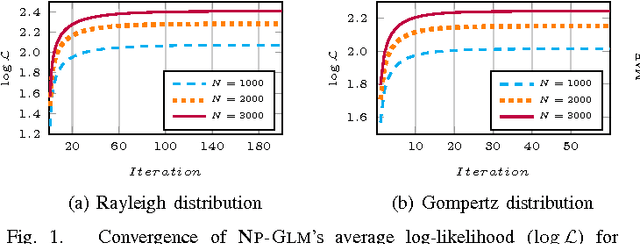
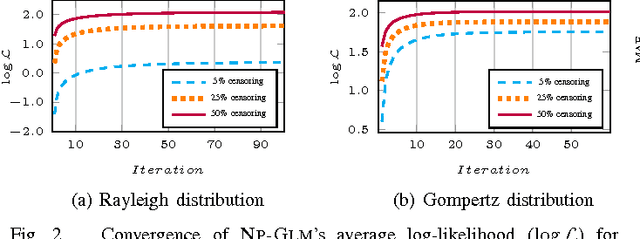
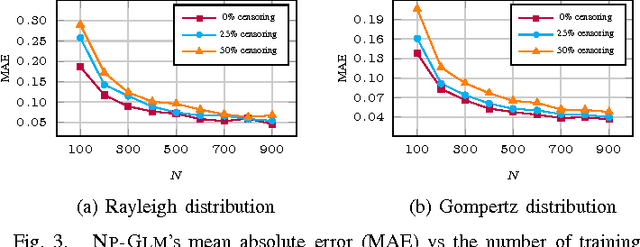
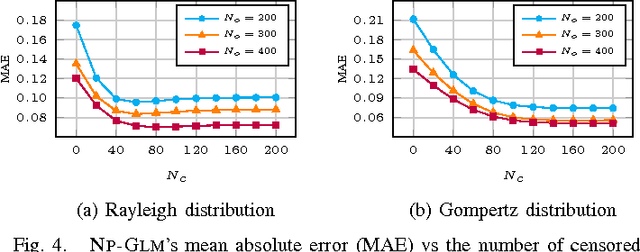
In this paper, we try to solve the problem of temporal link prediction in information networks. This implies predicting the time it takes for a link to appear in the future, given its features that have been extracted at the current network snapshot. To this end, we introduce a probabilistic non-parametric approach, called "Non-Parametric Generalized Linear Model" (NP-GLM), which infers the hidden underlying probability distribution of the link advent time given its features. We then present a learning algorithm for NP-GLM and an inference method to answer time-related queries. Extensive experiments conducted on both synthetic data and real-world Sina Weibo social network demonstrate the effectiveness of NP-GLM in solving temporal link prediction problem vis-a-vis competitive baselines.
Kissing Cuisines: Exploring Worldwide Culinary Habits on the Web
Apr 25, 2017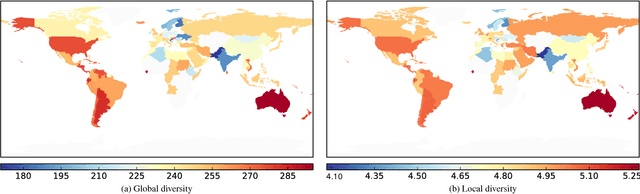
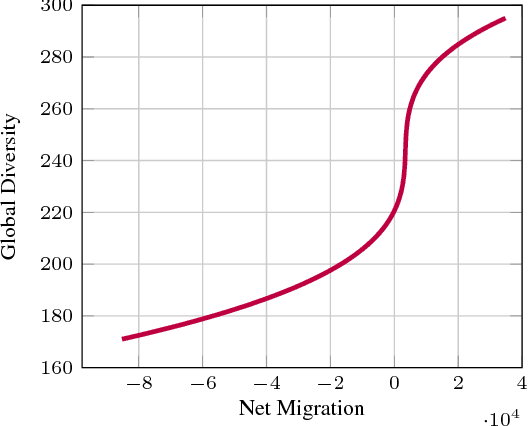
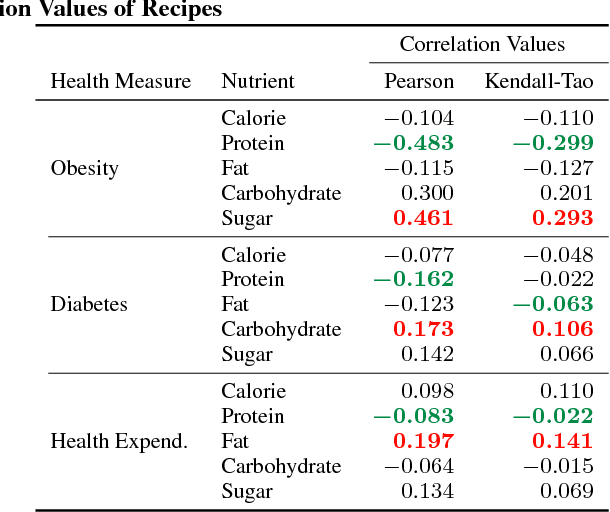
Food and nutrition occupy an increasingly prevalent space on the web, and dishes and recipes shared online provide an invaluable mirror into culinary cultures and attitudes around the world. More specifically, ingredients, flavors, and nutrition information become strong signals of the taste preferences of individuals and civilizations. However, there is little understanding of these palate varieties. In this paper, we present a large-scale study of recipes published on the web and their content, aiming to understand cuisines and culinary habits around the world. Using a database of more than 157K recipes from over 200 different cuisines, we analyze ingredients, flavors, and nutritional values which distinguish dishes from different regions, and use this knowledge to assess the predictability of recipes from different cuisines. We then use country health statistics to understand the relation between these factors and health indicators of different nations, such as obesity, diabetes, migration, and health expenditure. Our results confirm the strong effects of geographical and cultural similarities on recipes, health indicators, and culinary preferences across the globe.