 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Limitations of Vision-Language Models in Understanding Image Transforms
Mar 12, 2025



Vision Language Models (VLMs) have demonstrated significant potential in various downstream tasks, including Image/Video Generation, Visual Question Answering, Multimodal Chatbots, and Video Understanding. However, these models often struggle with basic image transformations. This paper investigates the image-level understanding of VLMs, specifically CLIP by OpenAI and SigLIP by Google. Our findings reveal that these models lack comprehension of multiple image-level augmentations. To facilitate this study, we created an augmented version of the Flickr8k dataset, pairing each image with a detailed description of the applied transformation. We further explore how this deficiency impacts downstream tasks, particularly in image editing, and evaluate the performance of state-of-the-art Image2Image models on simple transformations.
Masked Differential Privacy
Oct 22, 2024



Privacy-preserving computer vision is an important emerging problem in machine learning and artificial intelligence. The prevalent methods tackling this problem use differential privacy or anonymization and obfuscation techniques to protect the privacy of individuals. In both cases, the utility of the trained model is sacrificed heavily in this process. In this work, we propose an effective approach called masked differential privacy (MaskDP), which allows for controlling sensitive regions where differential privacy is applied, in contrast to applying DP on the entire input. Our method operates selectively on the data and allows for defining non-sensitive spatio-temporal regions without DP application or combining differential privacy with other privacy techniques within data samples. Experiments on four challenging action recognition datasets demonstrate that our proposed techniques result in better utility-privacy trade-offs compared to standard differentially private training in the especially demanding $\epsilon<1$ regime.
Detailed Annotations of Chest X-Rays via CT Projection for Report Understanding
Oct 07, 2022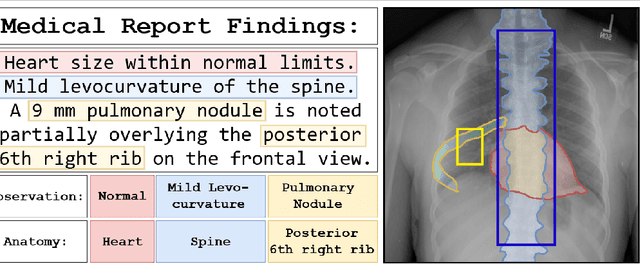
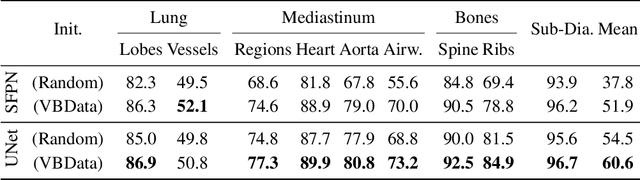
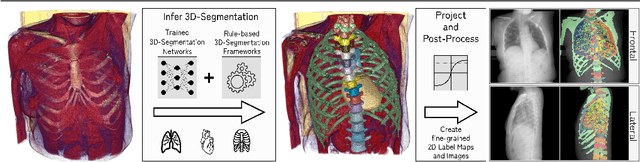
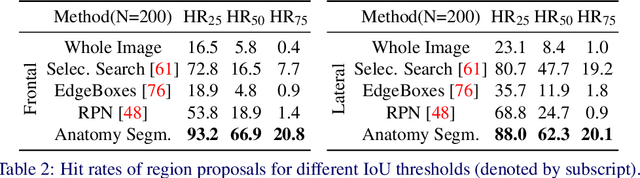
In clinical radiology reports, doctors capture important information about the patient's health status. They convey their observations from raw medical imaging data about the inner structures of a patient. As such, formulating reports requires medical experts to possess wide-ranging knowledge about anatomical regions with their normal, healthy appearance as well as the ability to recognize abnormalities. This explicit grasp on both the patient's anatomy and their appearance is missing in current medical image-processing systems as annotations are especially difficult to gather. This renders the models to be narrow experts e.g. for identifying specific diseases. In this work, we recover this missing link by adding human anatomy into the mix and enable the association of content in medical reports to their occurrence in associated imagery (medical phrase grounding). To exploit anatomical structures in this scenario, we present a sophisticated automatic pipeline to gather and integrate human bodily structures from computed tomography datasets, which we incorporate in our PAXRay: A Projected dataset for the segmentation of Anatomical structures in X-Ray data. Our evaluation shows that methods that take advantage of anatomical information benefit heavily in visually grounding radiologists' findings, as our anatomical segmentations allow for up to absolute 50% better grounding results on the OpenI dataset as compared to commonly used region proposals. The PAXRay dataset is available at https://constantinseibold.github.io/paxray/.