 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Sep 12, 2023



We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/
Accurate Fine-Grained Segmentation of Human Anatomy in Radiographs via Volumetric Pseudo-Labeling
Jun 06, 2023Purpose: Interpreting chest radiographs (CXR) remains challenging due to the ambiguity of overlapping structures such as the lungs, heart, and bones. To address this issue, we propose a novel method for extracting fine-grained anatomical structures in CXR using pseudo-labeling of three-dimensional computed tomography (CT) scans. Methods: We created a large-scale dataset of 10,021 thoracic CTs with 157 labels and applied an ensemble of 3D anatomy segmentation models to extract anatomical pseudo-labels. These labels were projected onto a two-dimensional plane, similar to the CXR, allowing the training of detailed semantic segmentation models for CXR without any manual annotation effort. Results: Our resulting segmentation models demonstrated remarkable performance on CXR, with a high average model-annotator agreement between two radiologists with mIoU scores of 0.93 and 0.85 for frontal and lateral anatomy, while inter-annotator agreement remained at 0.95 and 0.83 mIoU. Our anatomical segmentations allowed for the accurate extraction of relevant explainable medical features such as the cardio-thoracic-ratio. Conclusion: Our method of volumetric pseudo-labeling paired with CT projection offers a promising approach for detailed anatomical segmentation of CXR with a high agreement with human annotators. This technique may have important clinical implications, particularly in the analysis of various thoracic pathologies.
Detailed Annotations of Chest X-Rays via CT Projection for Report Understanding
Oct 07, 2022
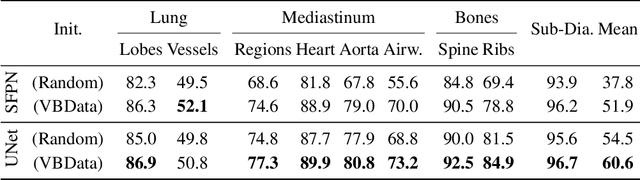
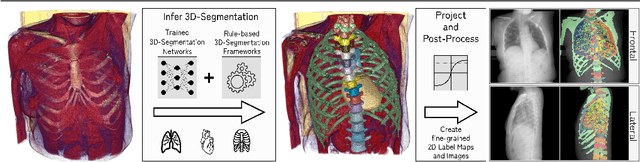
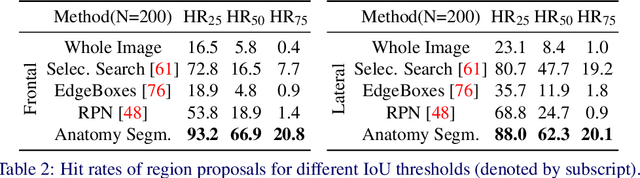
In clinical radiology reports, doctors capture important information about the patient's health status. They convey their observations from raw medical imaging data about the inner structures of a patient. As such, formulating reports requires medical experts to possess wide-ranging knowledge about anatomical regions with their normal, healthy appearance as well as the ability to recognize abnormalities. This explicit grasp on both the patient's anatomy and their appearance is missing in current medical image-processing systems as annotations are especially difficult to gather. This renders the models to be narrow experts e.g. for identifying specific diseases. In this work, we recover this missing link by adding human anatomy into the mix and enable the association of content in medical reports to their occurrence in associated imagery (medical phrase grounding). To exploit anatomical structures in this scenario, we present a sophisticated automatic pipeline to gather and integrate human bodily structures from computed tomography datasets, which we incorporate in our PAXRay: A Projected dataset for the segmentation of Anatomical structures in X-Ray data. Our evaluation shows that methods that take advantage of anatomical information benefit heavily in visually grounding radiologists' findings, as our anatomical segmentations allow for up to absolute 50% better grounding results on the OpenI dataset as compared to commonly used region proposals. The PAXRay dataset is available at https://constantinseibold.github.io/paxray/.
Prediction of low-keV monochromatic images from polyenergetic CT scans for improved automatic detection of pulmonary embolism
Feb 23, 2021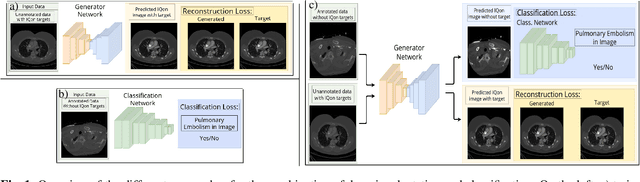
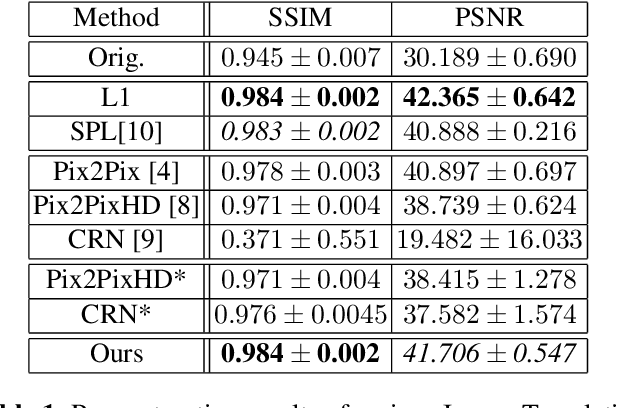
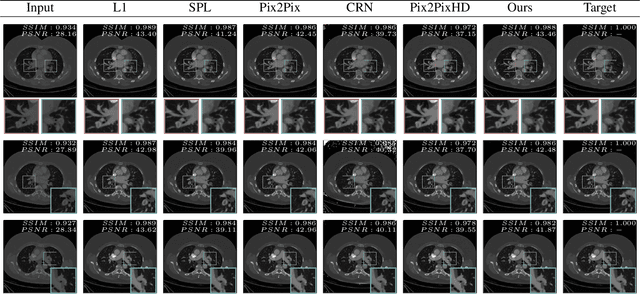

Detector-based spectral computed tomography is a recent dual-energy CT (DECT) technology that offers the possibility of obtaining spectral information. From this spectral data, different types of images can be derived, amongst others virtual monoenergetic (monoE) images. MonoE images potentially exhibit decreased artifacts, improve contrast, and overall contain lower noise values, making them ideal candidates for better delineation and thus improved diagnostic accuracy of vascular abnormalities. In this paper, we are training convolutional neural networks~(CNN) that can emulate the generation of monoE images from conventional single energy CT acquisitions. For this task, we investigate several commonly used image-translation methods. We demonstrate that these methods while creating visually similar outputs, lead to a poorer performance when used for automatic classification of pulmonary embolism (PE). We expand on these methods through the use of a multi-task optimization approach, under which the networks achieve improved classification as well as generation results, as reflected by PSNR and SSIM scores. Further, evaluating our proposed framework on a subset of the RSNA-PE challenge data set shows that we are able to improve the Area under the Receiver Operating Characteristic curve (AuROC) in comparison to a na\"ive classification approach from 0.8142 to 0.8420.