 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence In Patent And Market Intelligence: A New Paradigm For Technology Scouting
Jul 27, 2025This paper presents the development of an AI powered software platform that leverages advanced large language models (LLMs) to transform technology scouting and solution discovery in industrial R&D. Traditional approaches to solving complex research and development challenges are often time consuming, manually driven, and heavily dependent on domain specific expertise. These methods typically involve navigating fragmented sources such as patent repositories, commercial product catalogs, and competitor data, leading to inefficiencies and incomplete insights. The proposed platform utilizes cutting edge LLM capabilities including semantic understanding, contextual reasoning, and cross-domain knowledge extraction to interpret problem statements and retrieve high-quality, sustainable solutions. The system processes unstructured patent texts, such as claims and technical descriptions, and systematically extracts potential innovations aligned with the given problem context. These solutions are then algorithmically organized under standardized technical categories and subcategories to ensure clarity and relevance across interdisciplinary domains. In addition to patent analysis, the platform integrates commercial intelligence by identifying validated market solutions and active organizations addressing similar challenges. This combined insight sourced from both intellectual property and real world product data enables R&D teams to assess not only technical novelty but also feasibility, scalability, and sustainability. The result is a comprehensive, AI driven scouting engine that reduces manual effort, accelerates innovation cycles, and enhances decision making in complex R&D environments.
Bridging the Data Provenance Gap Across Text, Speech and Video
Dec 19, 2024



Progress in AI is driven largely by the scale and quality of training data. Despite this, there is a deficit of empirical analysis examining the attributes of well-established datasets beyond text. In this work we conduct the largest and first-of-its-kind longitudinal audit across modalities--popular text, speech, and video datasets--from their detailed sourcing trends and use restrictions to their geographical and linguistic representation. Our manual analysis covers nearly 4000 public datasets between 1990-2024, spanning 608 languages, 798 sources, 659 organizations, and 67 countries. We find that multimodal machine learning applications have overwhelmingly turned to web-crawled, synthetic, and social media platforms, such as YouTube, for their training sets, eclipsing all other sources since 2019. Secondly, tracing the chain of dataset derivations we find that while less than 33% of datasets are restrictively licensed, over 80% of the source content in widely-used text, speech, and video datasets, carry non-commercial restrictions. Finally, counter to the rising number of languages and geographies represented in public AI training datasets, our audit demonstrates measures of relative geographical and multilingual representation have failed to significantly improve their coverage since 2013. We believe the breadth of our audit enables us to empirically examine trends in data sourcing, restrictions, and Western-centricity at an ecosystem-level, and that visibility into these questions are essential to progress in responsible AI. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire multimodal audit, allowing practitioners to trace data provenance across text, speech, and video.
Rendering-Refined Stable Diffusion for Privacy Compliant Synthetic Data
Dec 09, 2024Growing privacy concerns and regulations like GDPR and CCPA necessitate pseudonymization techniques that protect identity in image datasets. However, retaining utility is also essential. Traditional methods like masking and blurring degrade quality and obscure critical context, especially in human-centric images. We introduce Rendering-Refined Stable Diffusion (RefSD), a pipeline that combines 3D-rendering with Stable Diffusion, enabling prompt-based control over human attributes while preserving posture. Unlike standard diffusion models that fail to retain posture or GANs that lack realism and flexible attribute control, RefSD balances posture preservation, realism, and customization. We also propose HumanGenAI, a framework for human perception and utility evaluation. Human perception assessments reveal attribute-specific strengths and weaknesses of RefSD. Our utility experiments show that models trained on RefSD pseudonymized data outperform those trained on real data in detection tasks, with further performance gains when combining RefSD with real data. For classification tasks, we consistently observe performance improvements when using RefSD data with real data, confirming the utility of our pseudonymized data.
Masked Differential Privacy
Oct 22, 2024



Privacy-preserving computer vision is an important emerging problem in machine learning and artificial intelligence. The prevalent methods tackling this problem use differential privacy or anonymization and obfuscation techniques to protect the privacy of individuals. In both cases, the utility of the trained model is sacrificed heavily in this process. In this work, we propose an effective approach called masked differential privacy (MaskDP), which allows for controlling sensitive regions where differential privacy is applied, in contrast to applying DP on the entire input. Our method operates selectively on the data and allows for defining non-sensitive spatio-temporal regions without DP application or combining differential privacy with other privacy techniques within data samples. Experiments on four challenging action recognition datasets demonstrate that our proposed techniques result in better utility-privacy trade-offs compared to standard differentially private training in the especially demanding $\epsilon<1$ regime.
Consent in Crisis: The Rapid Decline of the AI Data Commons
Jul 24, 2024


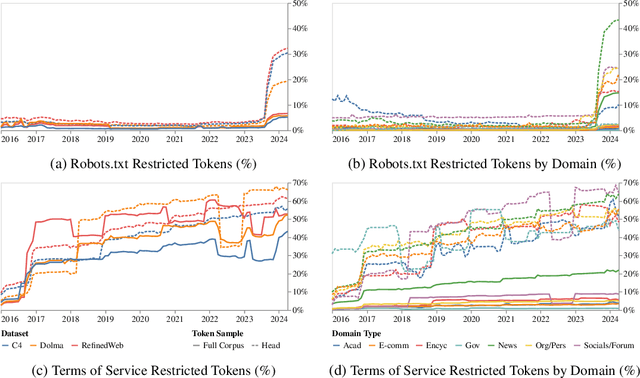
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, large-scale, longitudinal audit of the consent protocols for the web domains underlying AI training corpora. Our audit of 14,000 web domains provides an expansive view of crawlable web data and how codified data use preferences are changing over time. We observe a proliferation of AI-specific clauses to limit use, acute differences in restrictions on AI developers, as well as general inconsistencies between websites' expressed intentions in their Terms of Service and their robots.txt. We diagnose these as symptoms of ineffective web protocols, not designed to cope with the widespread re-purposing of the internet for AI. Our longitudinal analyses show that in a single year (2023-2024) there has been a rapid crescendo of data restrictions from web sources, rendering ~5%+ of all tokens in C4, or 28%+ of the most actively maintained, critical sources in C4, fully restricted from use. For Terms of Service crawling restrictions, a full 45% of C4 is now restricted. If respected or enforced, these restrictions are rapidly biasing the diversity, freshness, and scaling laws for general-purpose AI systems. We hope to illustrate the emerging crises in data consent, for both developers and creators. The foreclosure of much of the open web will impact not only commercial AI, but also non-commercial AI and academic research.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
MedLM: Exploring Language Models for Medical Question Answering Systems
Jan 21, 2024In the face of rapidly expanding online medical literature, automated systems for aggregating and summarizing information are becoming increasingly crucial for healthcare professionals and patients. Large Language Models (LLMs), with their advanced generative capabilities, have shown promise in various NLP tasks, and their potential in the healthcare domain, particularly for Closed-Book Generative QnA, is significant. However, the performance of these models in domain-specific tasks such as medical Q&A remains largely unexplored. This study aims to fill this gap by comparing the performance of general and medical-specific distilled LMs for medical Q&A. We aim to evaluate the effectiveness of fine-tuning domain-specific LMs and compare the performance of different families of Language Models. The study will address critical questions about these models' reliability, comparative performance, and effectiveness in the context of medical Q&A. The findings will provide valuable insights into the suitability of different LMs for specific applications in the medical domain.
Privacy Assessment on Reconstructed Images: Are Existing Evaluation Metrics Faithful to Human Perception?
Sep 22, 2023



Hand-crafted image quality metrics, such as PSNR and SSIM, are commonly used to evaluate model privacy risk under reconstruction attacks. Under these metrics, reconstructed images that are determined to resemble the original one generally indicate more privacy leakage. Images determined as overall dissimilar, on the other hand, indicate higher robustness against attack. However, there is no guarantee that these metrics well reflect human opinions, which, as a judgement for model privacy leakage, are more trustworthy. In this paper, we comprehensively study the faithfulness of these hand-crafted metrics to human perception of privacy information from the reconstructed images. On 5 datasets ranging from natural images, faces, to fine-grained classes, we use 4 existing attack methods to reconstruct images from many different classification models and, for each reconstructed image, we ask multiple human annotators to assess whether this image is recognizable. Our studies reveal that the hand-crafted metrics only have a weak correlation with the human evaluation of privacy leakage and that even these metrics themselves often contradict each other. These observations suggest risks of current metrics in the community. To address this potential risk, we propose a learning-based measure called SemSim to evaluate the Semantic Similarity between the original and reconstructed images. SemSim is trained with a standard triplet loss, using an original image as an anchor, one of its recognizable reconstructed images as a positive sample, and an unrecognizable one as a negative. By training on human annotations, SemSim exhibits a greater reflection of privacy leakage on the semantic level. We show that SemSim has a significantly higher correlation with human judgment compared with existing metrics. Moreover, this strong correlation generalizes to unseen datasets, models and attack methods.
Physically Disentangled Representations
Apr 11, 2022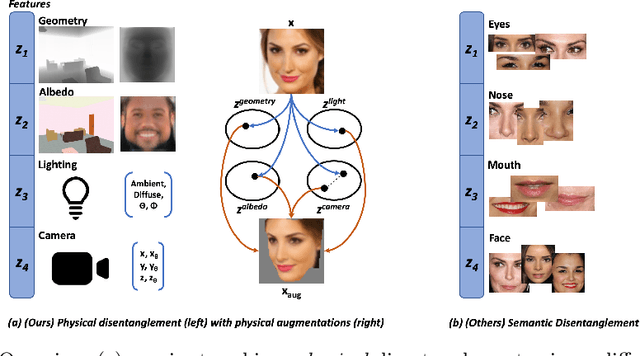

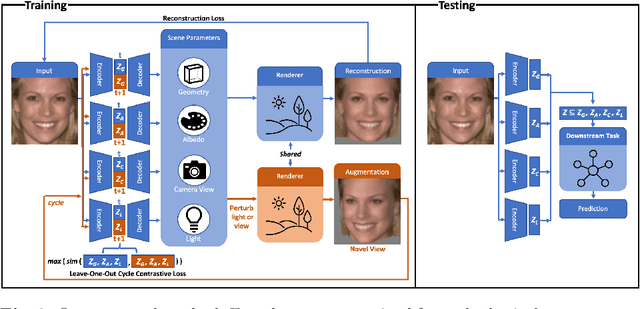

State-of-the-art methods in generative representation learning yield semantic disentanglement, but typically do not consider physical scene parameters, such as geometry, albedo, lighting, or camera. We posit that inverse rendering, a way to reverse the rendering process to recover scene parameters from an image, can also be used to learn physically disentangled representations of scenes without supervision. In this paper, we show the utility of inverse rendering in learning representations that yield improved accuracy on downstream clustering, linear classification, and segmentation tasks with the help of our novel Leave-One-Out, Cycle Contrastive loss (LOOCC), which improves disentanglement of scene parameters and robustness to out-of-distribution lighting and viewpoints. We perform a comparison of our method with other generative representation learning methods across a variety of downstream tasks, including face attribute classification, emotion recognition, identification, face segmentation, and car classification. Our physically disentangled representations yield higher accuracy than semantically disentangled alternatives across all tasks and by as much as 18%. We hope that this work will motivate future research in applying advances in inverse rendering and 3D understanding to representation learning.
Learning to Censor by Noisy Sampling
Mar 23, 2022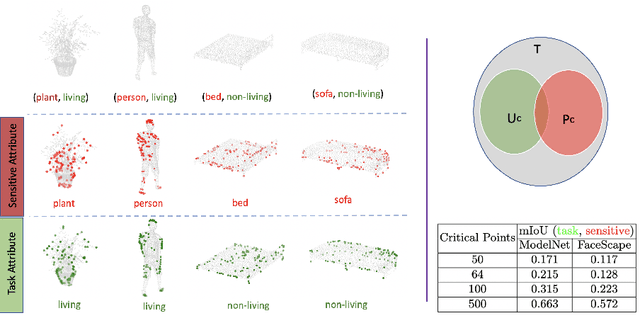
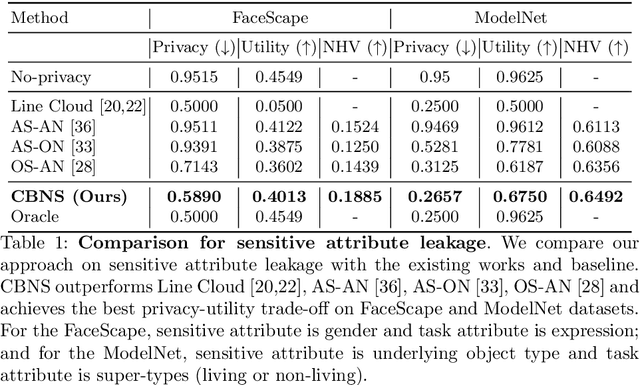

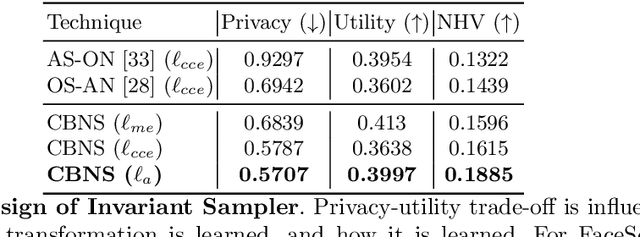
Point clouds are an increasingly ubiquitous input modality and the raw signal can be efficiently processed with recent progress in deep learning. This signal may, often inadvertently, capture sensitive information that can leak semantic and geometric properties of the scene which the data owner does not want to share. The goal of this work is to protect sensitive information when learning from point clouds; by censoring the sensitive information before the point cloud is released for downstream tasks. Specifically, we focus on preserving utility for perception tasks while mitigating attribute leakage attacks. The key motivating insight is to leverage the localized saliency of perception tasks on point clouds to provide good privacy-utility trade-offs. We realize this through a mechanism called Censoring by Noisy Sampling (CBNS), which is composed of two modules: i) Invariant Sampler: a differentiable point-cloud sampler which learns to remove points invariant to utility and ii) Noisy Distorter: which learns to distort sampled points to decouple the sensitive information from utility, and mitigate privacy leakage. We validate the effectiveness of CBNS through extensive comparisons with state-of-the-art baselines and sensitivity analyses of key design choices. Results show that CBNS achieves superior privacy-utility trade-offs on multiple datasets.