 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalArt-VQA: Diagnosing Whether VLMs Understand Salient Artifacts in Generated Images
Jun 10, 2026Vision-language models (VLMs) are increasingly used to detect whether AI-generated images contain visible artifacts, yet their ability to analyze such artifacts remains poorly understood. A correct image-level decision can still hide important failures: a model may correctly flag an artifact while relying on the wrong visual cue, selecting the wrong region, or describing a defect that the image does not support. To evaluate these behaviors directly, we introduce SalArt-VQA, a diagnostic benchmark for fine-grained SALient ARTifact understanding in AI-generated images. SalArt-VQA contains 950 images and 3,681 human-authored multiple-choice questions spanning artifact images, matched real reference images, and paired generated reference images. Four aligned question types evaluate presence detection, semantic localization, spatial grounding, and evidence-grounded defect identification, while the reference splits test calibration and abstention when the annotated defect is absent. Across 20 VLMs, SalArt-VQA reveals failures that image-level detection accuracy hides: the strongest model reaches 99.37% detection recall on artifact images but answers all four artifact-side questions correctly on only 53.26% of images. Comparing artifact images with artifact-free references reveals a sensitivity-calibration tradeoff: sensitive models often make unsupported artifact claims, while conservative models avoid false alarms largely by missing real artifacts. These results show that high artifact detection accuracy alone does not imply grounded artifact understanding. SalArt-VQA exposes these hidden failure modes and provides a fine-grained evaluation of whether VLM artifact claims are supported by local visual evidence.
MMBU: A Massive Multi-modal Biomedical Understanding Benchmark to Probe the Perception Capabilities of Vision-Language Models
Jun 04, 2026Vision and language models (VLMs) hold immense promise to transform biomedical imaging workflows, from detecting lesions in chest X-rays to profiling cellular features in microscopy. Realizing this potential, however, requires robust and fine-grained visual perception. Models need to correctly interpret subtle features in images, and they must do so across diverse biomedical modalities, scales, and contexts. Nevertheless, current benchmarks remain limited. To address these gaps, we introduce the Massive Multimodal Biomedical Understanding (MMBU) benchmark. It is the largest biomedical vision and language benchmark to date, covering 35 submodalities with rich structured metadata. It includes both open and closed versions of ungrounded classification, grounded classification, and object detection, enabling systematic evaluation of model performance across biological scales, clinical settings, and imaging modalities. Evaluating 15 open-weight and 2 frontier VLMs, we find that while medical adaptation provides measurable gains for some models, the high accuracy often reported on established benchmarks can mask deficiencies in visual perception and domain generalization.
An interpretable and trustworthy AI framework for large-scale longitudinal structure-pain association studies using data from the Osteoarthritis Initiative (OAI)
Jun 03, 2026Purpose: To develop an interpretable and trustworthy AI framework that combines deep learning based MRI Osteoarthritis Knee Score (MOAKS) prediction with interpretable statistical modeling to study structure-pain relationships at scale using data from the Osteoarthritis Initiative (OAI). Materials and Methods: We first developed a deep learning framework to predict MOAKS features directly from knee MRIs and incorporated conformal prediction to provide prediction uncertainty quantification. This uncertainty-aware strategy enables explicit filtering of model outputs, retaining only high-confidence MOAKS predictions at the knee level. Second, we applied a longitudinal latent class mixed model (LCMM) to examine associations between key structural abnormalities and four complementary knee pain measurements. Results: Among the three MRI-defined abnormalities (i.e., bone marrow lesions (BML), cartilage loss (CART), and meniscal extrusion (ME)), our framework substantially improved the Matthews correlation coefficient (MCC) and some other metrics. For example, MCC increased from 0.69 to 0.91 for BML, from 0.45 to 0.80 for CART, and from 0.59 to 0.89 for ME. Using these high-confidence predictions, we expanded the sample size to 2,175 knees for the LCMM analysis. Two distinct pain trajectories were identified (rapid and stable pain progression). The estimated odds ratios (95% CI) for the rapid progression group were 1.62 (1.12-2.35) for BML, 1.83 (1.24-2.70) for CART loss, and 2.50 (1.75-3.57) for ME. Conclusion: These results highlight the importance of these structural abnormalities as risk factors for pain and functional progression in osteoarthritis.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
Incentivizing Generative Zero-Shot Learning via Outcome-Reward Reinforcement Learning with Visual Cues
Mar 22, 2026Recent advances in zero-shot learning (ZSL) have demonstrated the potential of generative models. Typically, generative ZSL synthesizes visual features conditioned on semantic prototypes to model the data distribution of unseen classes, followed by training a classifier on the synthesized data. However, the synthesized features often remain task-agnostic, leading to degraded performance. Moreover, inferring a faithful distribution from semantic prototypes alone is insufficient for classes that are semantically similar but visually distinct. To address these and advance ZSL, we propose RLVC, an outcome-reward reinforcement learning RL framework with visual cues for generative ZSL. At its core, RL empowers the generative model to self-evolve, implicitly enhancing its generation capability. In particular, RLVC updates the generative model using an outcome-based reward, encouraging the synthesis of task-relevant features. Furthermore, we introduce class-wise visual cues that (i) align synthesized features with visual prototypes and (ii) stabilize the RL training updates. For the training process, we present a novel cold-start strategy. Comprehensive experiments and analyses on three prevalent ZSL benchmarks demonstrate that RLVC achieves state-of-the-art results with a 4.7% gain.
Seeing Is Believing? A Benchmark for Multimodal Large Language Models on Visual Illusions and Anomalies
Feb 02, 2026Multimodal Large Language Models (MLLMs) have shown remarkable proficiency on general-purpose vision-language benchmarks, reaching or even exceeding human-level performance. However, these evaluations typically rely on standard in-distribution data, leaving the robustness of MLLMs largely unexamined when faced with scenarios that defy common-sense priors. To address this gap, we introduce VIA-Bench, a challenging benchmark designed to probe model performance on visual illusions and anomalies. It includes six core categories: color illusions, motion illusions, gestalt illusions, geometric and spatial illusions, general visual illusions, and visual anomalies. Through careful human-in-the-loop review, we construct over 1K high-quality question-answer pairs that require nuanced visual reasoning. Extensive evaluation of over 20 state-of-the-art MLLMs, including proprietary, open-source, and reasoning-enhanced models, uncovers significant vulnerabilities. Notably, we find that Chain-of-Thought (CoT) reasoning offers negligible robustness, often yielding ``brittle mirages'' where the model's logic collapses under illusory stimuli. Our findings reveal a fundamental divergence between machine and human perception, suggesting that resolving such perceptual bottlenecks is critical for the advancement of artificial general intelligence. The benchmark data and code will be released.
Do VLMs Perceive or Recall? Probing Visual Perception vs. Memory with Classic Visual Illusions
Jan 29, 2026Large Vision-Language Models (VLMs) often answer classic visual illusions "correctly" on original images, yet persist with the same responses when illusion factors are inverted, even though the visual change is obvious to humans. This raises a fundamental question: do VLMs perceive visual changes or merely recall memorized patterns? While several studies have noted this phenomenon, the underlying causes remain unclear. To move from observations to systematic understanding, this paper introduces VI-Probe, a controllable visual-illusion framework with graded perturbations and matched visual controls (without illusion inducer) that disentangles visually grounded perception from language-driven recall. Unlike prior work that focuses on averaged accuracy, we measure stability and sensitivity using Polarity-Flip Consistency, Template Fixation Index, and an illusion multiplier normalized against matched controls. Experiments across different families reveal that response persistence arises from heterogeneous causes rather than a single mechanism. For instance, GPT-5 exhibits memory override, Claude-Opus-4.1 shows perception-memory competition, while Qwen variants suggest visual-processing limits. Our findings challenge single-cause views and motivate probing-based evaluation that measures both knowledge and sensitivity to controlled visual change. Data and code are available at https://sites.google.com/view/vi-probe/.
CLDyB: Towards Dynamic Benchmarking for Continual Learning with Pre-trained Models
Mar 06, 2025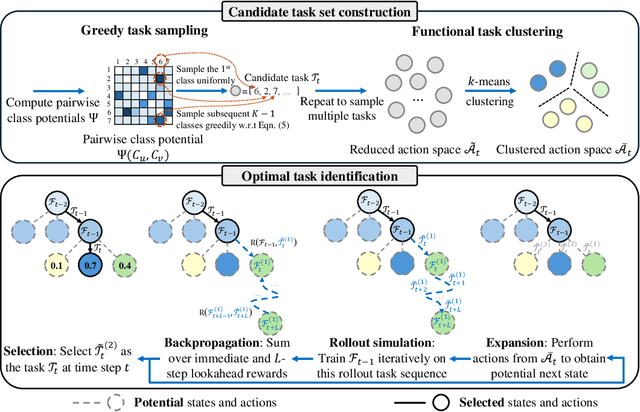
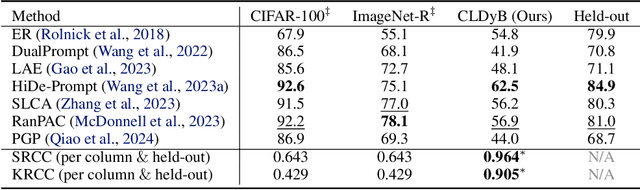
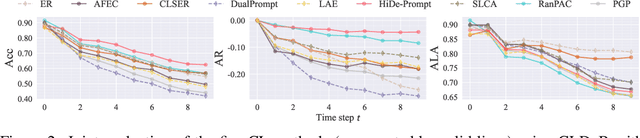

The advent of the foundation model era has sparked significant research interest in leveraging pre-trained representations for continual learning (CL), yielding a series of top-performing CL methods on standard evaluation benchmarks. Nonetheless, there are growing concerns regarding potential data contamination during the pre-training stage. Furthermore, standard evaluation benchmarks, which are typically static, fail to capture the complexities of real-world CL scenarios, resulting in saturated performance. To address these issues, we describe CL on dynamic benchmarks (CLDyB), a general computational framework based on Markov decision processes for evaluating CL methods reliably. CLDyB dynamically identifies inherently difficult and algorithm-dependent tasks for the given CL methods, and determines challenging task orders using Monte Carlo tree search. Leveraging CLDyB, we first conduct a joint evaluation of multiple state-of-the-art CL methods, leading to a set of commonly challenging and generalizable task sequences where existing CL methods tend to perform poorly. We then conduct separate evaluations of individual CL methods using CLDyB, discovering their respective strengths and weaknesses. The source code and generated task sequences are publicly accessible at https://github.com/szc12153/CLDyB.
Physiologically-Informed Predictability of a Teammate's Future Actions Forecasts Team Performance
Jan 25, 2025



In collaborative environments, a deep understanding of multi-human teaming dynamics is essential for optimizing performance. However, the relationship between individuals' behavioral and physiological markers and their combined influence on overall team performance remains poorly understood. To explore this, we designed a triadic human collaborative sensorimotor task in virtual reality (VR) and introduced a novel predictability metric to examine team dynamics and performance. Our findings reveal a strong connection between team performance and the predictability of a team member's future actions based on other team members' behavioral and physiological data. Contrary to conventional wisdom that high-performing teams are highly synchronized, our results suggest that physiological and behavioral synchronizations among team members have a limited correlation with team performance. These insights provide a new quantitative framework for understanding multi-human teaming, paving the way for deeper insights into team dynamics and performance.
Rendering-Refined Stable Diffusion for Privacy Compliant Synthetic Data
Dec 09, 2024Growing privacy concerns and regulations like GDPR and CCPA necessitate pseudonymization techniques that protect identity in image datasets. However, retaining utility is also essential. Traditional methods like masking and blurring degrade quality and obscure critical context, especially in human-centric images. We introduce Rendering-Refined Stable Diffusion (RefSD), a pipeline that combines 3D-rendering with Stable Diffusion, enabling prompt-based control over human attributes while preserving posture. Unlike standard diffusion models that fail to retain posture or GANs that lack realism and flexible attribute control, RefSD balances posture preservation, realism, and customization. We also propose HumanGenAI, a framework for human perception and utility evaluation. Human perception assessments reveal attribute-specific strengths and weaknesses of RefSD. Our utility experiments show that models trained on RefSD pseudonymized data outperform those trained on real data in detection tasks, with further performance gains when combining RefSD with real data. For classification tasks, we consistently observe performance improvements when using RefSD data with real data, confirming the utility of our pseudonymized data.