 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScales++: Compute Efficient Evaluation Subset Selection with Cognitive Scales Embeddings
Oct 30, 2025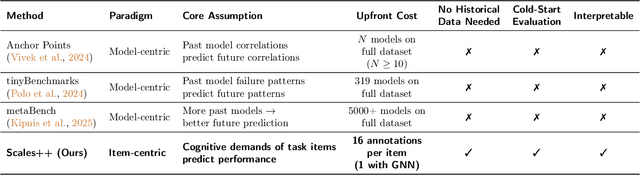
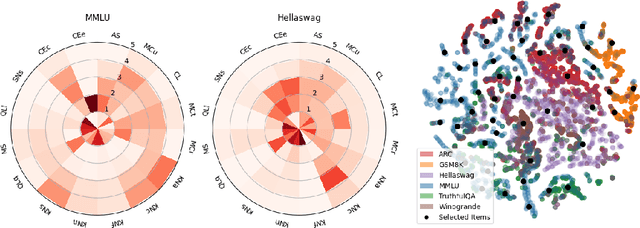
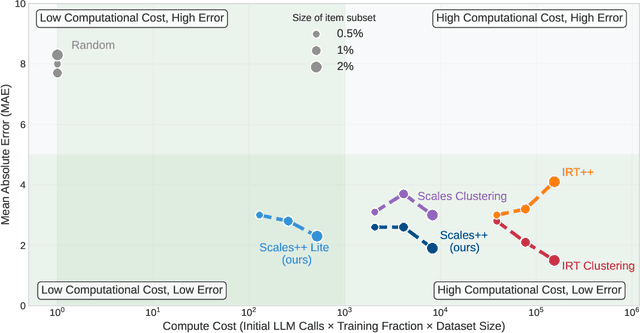
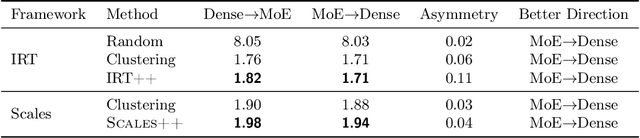
The prohibitive cost of evaluating large language models (LLMs) on comprehensive benchmarks necessitates the creation of small yet representative data subsets (i.e., tiny benchmarks) that enable efficient assessment while retaining predictive fidelity. Current methods for this task operate under a model-centric paradigm, selecting benchmarking items based on the collective performance of existing models. Such approaches are limited by large upfront costs, an inability to immediately handle new benchmarks (`cold-start'), and the fragile assumption that future models will share the failure patterns of their predecessors. In this work, we challenge this paradigm and propose a item-centric approach to benchmark subset selection, arguing that selection should be based on the intrinsic properties of the task items themselves, rather than on model-specific failure patterns. We instantiate this item-centric efficient benchmarking approach via a novel method, Scales++, where data selection is based on the cognitive demands of the benchmark samples. Empirically, we show Scales++ reduces the upfront selection cost by over 18x while achieving competitive predictive fidelity. On the Open LLM Leaderboard, using just a 0.5\% data subset, we predict full benchmark scores with a 2.9% mean absolute error. We demonstrate that this item-centric approach enables more efficient model evaluation without significant fidelity degradation, while also providing better cold-start performance and more interpretable benchmarking.
Automatic Expert Discovery in LLM Upcycling via Sparse Interpolated Mixture-of-Experts
Jun 14, 2025We present Sparse Interpolated Mixture-of-Experts (SIMoE) instruction-tuning, an end-to-end algorithm designed to fine-tune a dense pre-trained Large Language Model (LLM) into a MoE-style model that possesses capabilities in multiple specialized domains. During instruction-tuning, SIMoE automatically identifies multiple specialized experts under a specified sparsity constraint, with each expert representing a structurally sparse subset of the seed LLM's parameters that correspond to domain-specific knowledge within the data. SIMoE simultaneously learns an input-dependent expert merging strategy via a router network, leveraging rich cross-expert knowledge for superior downstream generalization that surpasses existing baselines. Empirically, SIMoE consistently achieves state-of-the-art performance on common instruction-tuning benchmarks while maintaining an optimal performance-compute trade-off compared to all baselines.
CLDyB: Towards Dynamic Benchmarking for Continual Learning with Pre-trained Models
Mar 06, 2025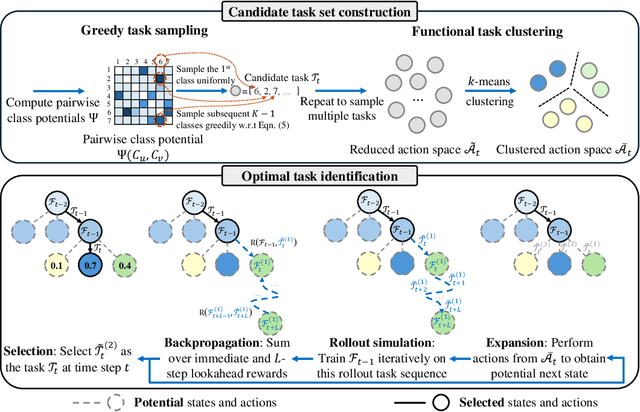
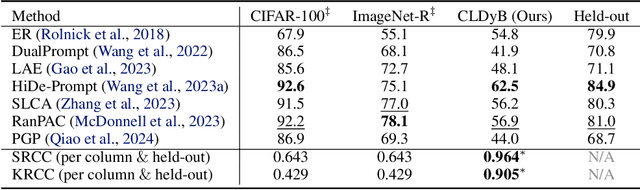
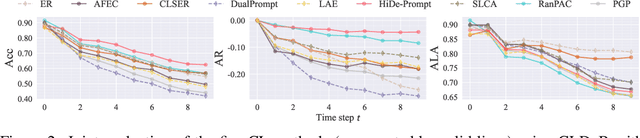

The advent of the foundation model era has sparked significant research interest in leveraging pre-trained representations for continual learning (CL), yielding a series of top-performing CL methods on standard evaluation benchmarks. Nonetheless, there are growing concerns regarding potential data contamination during the pre-training stage. Furthermore, standard evaluation benchmarks, which are typically static, fail to capture the complexities of real-world CL scenarios, resulting in saturated performance. To address these issues, we describe CL on dynamic benchmarks (CLDyB), a general computational framework based on Markov decision processes for evaluating CL methods reliably. CLDyB dynamically identifies inherently difficult and algorithm-dependent tasks for the given CL methods, and determines challenging task orders using Monte Carlo tree search. Leveraging CLDyB, we first conduct a joint evaluation of multiple state-of-the-art CL methods, leading to a set of commonly challenging and generalizable task sequences where existing CL methods tend to perform poorly. We then conduct separate evaluations of individual CL methods using CLDyB, discovering their respective strengths and weaknesses. The source code and generated task sequences are publicly accessible at https://github.com/szc12153/CLDyB.
Learning Where to Edit Vision Transformers
Nov 04, 2024



Model editing aims to data-efficiently correct predictive errors of large pre-trained models while ensuring generalization to neighboring failures and locality to minimize unintended effects on unrelated examples. While significant progress has been made in editing Transformer-based large language models, effective strategies for editing vision Transformers (ViTs) in computer vision remain largely untapped. In this paper, we take initial steps towards correcting predictive errors of ViTs, particularly those arising from subpopulation shifts. Taking a locate-then-edit approach, we first address the where-to-edit challenge by meta-learning a hypernetwork on CutMix-augmented data generated for editing reliability. This trained hypernetwork produces generalizable binary masks that identify a sparse subset of structured model parameters, responsive to real-world failure samples. Afterward, we solve the how-to-edit problem by simply fine-tuning the identified parameters using a variant of gradient descent to achieve successful edits. To validate our method, we construct an editing benchmark that introduces subpopulation shifts towards natural underrepresented images and AI-generated images, thereby revealing the limitations of pre-trained ViTs for object recognition. Our approach not only achieves superior performance on the proposed benchmark but also allows for adjustable trade-offs between generalization and locality. Our code is available at https://github.com/hustyyq/Where-to-Edit.
Unleashing the Power of Meta-tuning for Few-shot Generalization Through Sparse Interpolated Experts
Mar 13, 2024Conventional wisdom suggests parameter-efficient fine-tuning of foundation models as the state-of-the-art method for transfer learning in vision, replacing the rich literature of alternatives such as meta-learning. In trying to harness the best of both worlds, meta-tuning introduces a subsequent optimization stage of foundation models but has so far only shown limited success and crucially tends to underperform on out-of-domain (OOD) tasks. In this paper, we introduce Sparse MetA-Tuning (SMAT), a method inspired by sparse mixture-of-experts approaches and trained to isolate subsets of pre-trained parameters automatically for meta-tuning on each task. SMAT successfully overcomes OOD sensitivity and delivers on the promise of enhancing the transfer abilities of vision foundation models beyond parameter-efficient finetuning. We establish new state-of-the-art results on a challenging combination of Meta-Dataset augmented with additional OOD tasks in both zero-shot and gradient-based adaptation settings. In addition, we provide a thorough analysis of the superiority of learned over hand-designed sparsity patterns for sparse expert methods and the pivotal importance of the sparsity level in balancing between in-domain and out-of-domain generalization. Our code is publicly available.