 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjDevBench: Benchmarking AI Coding Agents on End-to-End Project Development
Feb 02, 2026Recent coding agents can generate complete codebases from simple prompts, yet existing evaluations focus on issue-level bug fixing and lag behind end-to-end development. We introduce ProjDevBench, an end-to-end benchmark that provides project requirements to coding agents and evaluates the resulting repositories. Combining Online Judge (OJ) testing with LLM-assisted code review, the benchmark evaluates agents on (1) system architecture design, (2) functional correctness, and (3) iterative solution refinement. We curate 20 programming problems across 8 categories, covering both concept-oriented tasks and real-world application scenarios, and evaluate six coding agents built on different LLM backends. Our evaluation reports an overall acceptance rate of 27.38%: agents handle basic functionality and data structures but struggle with complex system design, time complexity optimization, and resource management. Our benchmark is available at https://github.com/zsworld6/projdevbench.
Effective Training Data Synthesis for Improving MLLM Chart Understanding
Aug 08, 2025Being able to effectively read scientific plots, or chart understanding, is a central part toward building effective agents for science. However, existing multimodal large language models (MLLMs), especially open-source ones, are still falling behind with a typical success rate of 30%-50% on challenging benchmarks. Previous studies on fine-tuning MLLMs with synthetic charts are often restricted by their inadequate similarity to the real charts, which could compromise model training and performance on complex real-world charts. In this study, we show that modularizing chart generation and diversifying visual details improves chart understanding capabilities. In particular, we design a five-step data synthesis pipeline, where we separate data and function creation for single plot generation, condition the generation of later subplots on earlier ones for multi-subplot figures, visually diversify the generated figures, filter out low quality data, and finally generate the question-answer (QA) pairs with GPT-4o. This approach allows us to streamline the generation of fine-tuning datasets and introduce the effective chart dataset (ECD), which contains 10k+ chart images and 300k+ QA pairs, covering 25 topics and featuring 250+ chart type combinations with high visual complexity. We show that ECD consistently improves the performance of various MLLMs on a range of real-world and synthetic test sets. Code, data and models are available at: https://github.com/yuweiyang-anu/ECD.
REPA-E: Unlocking VAE for End-to-End Tuning with Latent Diffusion Transformers
Apr 14, 2025In this paper we tackle a fundamental question: "Can we train latent diffusion models together with the variational auto-encoder (VAE) tokenizer in an end-to-end manner?" Traditional deep-learning wisdom dictates that end-to-end training is often preferable when possible. However, for latent diffusion transformers, it is observed that end-to-end training both VAE and diffusion-model using standard diffusion-loss is ineffective, even causing a degradation in final performance. We show that while diffusion loss is ineffective, end-to-end training can be unlocked through the representation-alignment (REPA) loss -- allowing both VAE and diffusion model to be jointly tuned during the training process. Despite its simplicity, the proposed training recipe (REPA-E) shows remarkable performance; speeding up diffusion model training by over 17x and 45x over REPA and vanilla training recipes, respectively. Interestingly, we observe that end-to-end tuning with REPA-E also improves the VAE itself; leading to improved latent space structure and downstream generation performance. In terms of final performance, our approach sets a new state-of-the-art; achieving FID of 1.26 and 1.83 with and without classifier-free guidance on ImageNet 256 x 256. Code is available at https://end2end-diffusion.github.io.
Learning Camera Movement Control from Real-World Drone Videos
Dec 12, 2024



This study seeks to automate camera movement control for filming existing subjects into attractive videos, contrasting with the creation of non-existent content by directly generating the pixels. We select drone videos as our test case due to their rich and challenging motion patterns, distinctive viewing angles, and precise controls. Existing AI videography methods struggle with limited appearance diversity in simulation training, high costs of recording expert operations, and difficulties in designing heuristic-based goals to cover all scenarios. To avoid these issues, we propose a scalable method that involves collecting real-world training data to improve diversity, extracting camera trajectories automatically to minimize annotation costs, and training an effective architecture that does not rely on heuristics. Specifically, we collect 99k high-quality trajectories by running 3D reconstruction on online videos, connecting camera poses from consecutive frames to formulate 3D camera paths, and using Kalman filter to identify and remove low-quality data. Moreover, we introduce DVGFormer, an auto-regressive transformer that leverages the camera path and images from all past frames to predict camera movement in the next frame. We evaluate our system across 38 synthetic natural scenes and 7 real city 3D scans. We show that our system effectively learns to perform challenging camera movements such as navigating through obstacles, maintaining low altitude to increase perceived speed, and orbiting towers and buildings, which are very useful for recording high-quality videos. Data and code are available at dvgformer.github.io.
Optimizing Camera Configurations for Multi-View Pedestrian Detection
Dec 04, 2023

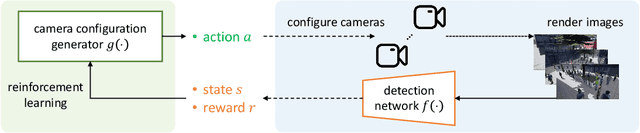

Jointly considering multiple camera views (multi-view) is very effective for pedestrian detection under occlusion. For such multi-view systems, it is critical to have well-designed camera configurations, including camera locations, directions, and fields-of-view (FoVs). Usually, these configurations are crafted based on human experience or heuristics. In this work, we present a novel solution that features a transformer-based camera configuration generator. Using reinforcement learning, this generator autonomously explores vast combinations within the action space and searches for configurations that give the highest detection accuracy according to the training dataset. The generator learns advanced techniques like maximizing coverage, minimizing occlusion, and promoting collaboration. Across multiple simulation scenarios, the configurations generated by our transformer-based model consistently outperform random search, heuristic-based methods, and configurations designed by human experts, shedding light on future camera layout optimization.
Learning to Select Camera Views: Efficient Multiview Understanding at Few Glances
Mar 10, 2023Multiview camera setups have proven useful in many computer vision applications for reducing ambiguities, mitigating occlusions, and increasing field-of-view coverage. However, the high computational cost associated with multiple views poses a significant challenge for end devices with limited computational resources. To address this issue, we propose a view selection approach that analyzes the target object or scenario from given views and selects the next best view for processing. Our approach features a reinforcement learning based camera selection module, MVSelect, that not only selects views but also facilitates joint training with the task network. Experimental results on multiview classification and detection tasks show that our approach achieves promising performance while using only 2 or 3 out of N available views, significantly reducing computational costs. Furthermore, analysis on the selected views reveals that certain cameras can be shut off with minimal performance impact, shedding light on future camera layout optimization for multiview systems. Code is available at https://github.com/hou-yz/MVSelect.
Learning to Structure an Image with Few Colors and Beyond
Aug 17, 2022



Color and structure are the two pillars that combine to give an image its meaning. Interested in critical structures for neural network recognition, we isolate the influence of colors by limiting the color space to just a few bits, and find structures that enable network recognition under such constraints. To this end, we propose a color quantization network, ColorCNN, which learns to structure an image in limited color spaces by minimizing the classification loss. Building upon the architecture and insights of ColorCNN, we introduce ColorCNN+, which supports multiple color space size configurations, and addresses the previous issues of poor recognition accuracy and undesirable visual fidelity under large color spaces. Via a novel imitation learning approach, ColorCNN+ learns to cluster colors like traditional color quantization methods. This reduces overfitting and helps both visual fidelity and recognition accuracy under large color spaces. Experiments verify that ColorCNN+ achieves very competitive results under most circumstances, preserving both key structures for network recognition and visual fidelity with accurate colors. We further discuss differences between key structures and accurate colors, and their specific contributions to network recognition. For potential applications, we show that ColorCNNs can be used as image compression methods for network recognition.
Multi-View Correlation Consistency for Semi-Supervised Semantic Segmentation
Aug 17, 2022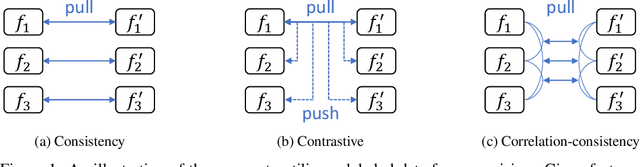
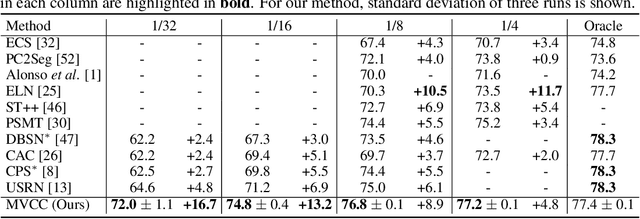


Semi-supervised semantic segmentation needs rich and robust supervision on unlabeled data. Consistency learning enforces the same pixel to have similar features in different augmented views, which is a robust signal but neglects relationships with other pixels. In comparison, contrastive learning considers rich pairwise relationships, but it can be a conundrum to assign binary positive-negative supervision signals for pixel pairs. In this paper, we take the best of both worlds and propose multi-view correlation consistency (MVCC) learning: it considers rich pairwise relationships in self-correlation matrices and matches them across views to provide robust supervision. Together with this correlation consistency loss, we propose a view-coherent data augmentation strategy that guarantees pixel-pixel correspondence between different views. In a series of semi-supervised settings on two datasets, we report competitive accuracy compared with the state-of-the-art methods. Notably, on Cityscapes, we achieve 76.8% mIoU with 1/8 labeled data, just 0.6% shy from the fully supervised oracle.
Multiview Detection with Cardboard Human Modeling
Jul 10, 2022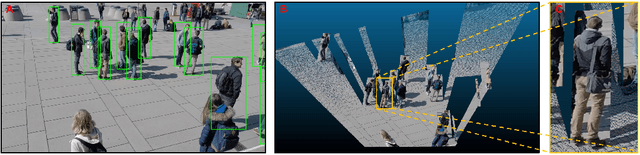
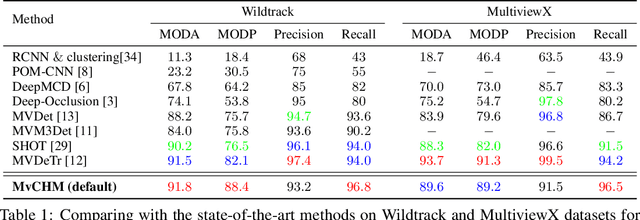
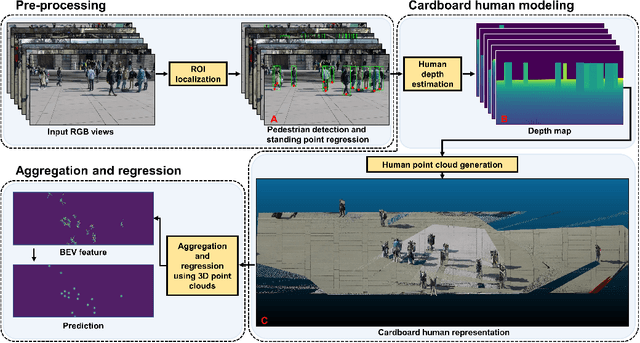

Multiview detection uses multiple calibrated cameras with overlapping fields of views to locate occluded pedestrians. In this field, existing methods typically adopt a "human modeling - aggregation" strategy. To find robust pedestrian representations, some intuitively use locations of detected 2D bounding boxes, while others use entire frame features projected to the ground plane. However, the former does not consider human appearance and leads to many ambiguities, and the latter suffers from projection errors due to the lack of accurate height of the human torso and head. In this paper, we propose a new pedestrian representation scheme based on human point clouds modeling. Specifically, using ray tracing for holistic human depth estimation, we model pedestrians as upright, thin cardboard point clouds on the ground. Then, we aggregate the point clouds of the pedestrian cardboard across multiple views for a final decision. Compared with existing representations, the proposed method explicitly leverages human appearance and reduces projection errors significantly by relatively accurate height estimation. On two standard evaluation benchmarks, the proposed method achieves very competitive results.
Adaptive Affinity for Associations in Multi-Target Multi-Camera Tracking
Dec 14, 2021



Data associations in multi-target multi-camera tracking (MTMCT) usually estimate affinity directly from re-identification (re-ID) feature distances. However, we argue that it might not be the best choice given the difference in matching scopes between re-ID and MTMCT problems. Re-ID systems focus on global matching, which retrieves targets from all cameras and all times. In contrast, data association in tracking is a local matching problem, since its candidates only come from neighboring locations and time frames. In this paper, we design experiments to verify such misfit between global re-ID feature distances and local matching in tracking, and propose a simple yet effective approach to adapt affinity estimations to corresponding matching scopes in MTMCT. Instead of trying to deal with all appearance changes, we tailor the affinity metric to specialize in ones that might emerge during data associations. To this end, we introduce a new data sampling scheme with temporal windows originally used for data associations in tracking. Minimizing the mismatch, the adaptive affinity module brings significant improvements over global re-ID distance, and produces competitive performance on CityFlow and DukeMTMC datasets.