 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Correlation Consistency for Semi-Supervised Semantic Segmentation
Paper and Code
Aug 17, 2022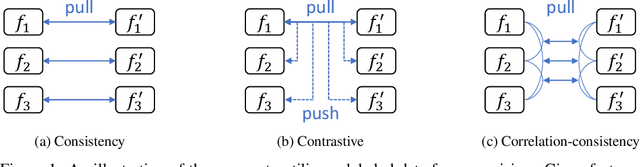
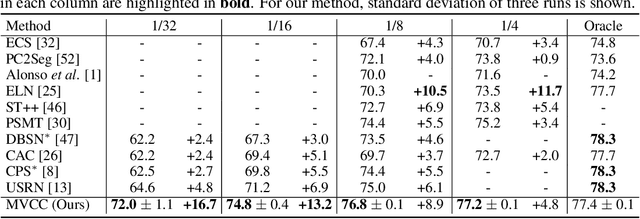


Semi-supervised semantic segmentation needs rich and robust supervision on unlabeled data. Consistency learning enforces the same pixel to have similar features in different augmented views, which is a robust signal but neglects relationships with other pixels. In comparison, contrastive learning considers rich pairwise relationships, but it can be a conundrum to assign binary positive-negative supervision signals for pixel pairs. In this paper, we take the best of both worlds and propose multi-view correlation consistency (MVCC) learning: it considers rich pairwise relationships in self-correlation matrices and matches them across views to provide robust supervision. Together with this correlation consistency loss, we propose a view-coherent data augmentation strategy that guarantees pixel-pixel correspondence between different views. In a series of semi-supervised settings on two datasets, we report competitive accuracy compared with the state-of-the-art methods. Notably, on Cityscapes, we achieve 76.8% mIoU with 1/8 labeled data, just 0.6% shy from the fully supervised oracle.