 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat matters for Representation Alignment: Global Information or Spatial Structure?
Dec 11, 2025Representation alignment (REPA) guides generative training by distilling representations from a strong, pretrained vision encoder to intermediate diffusion features. We investigate a fundamental question: what aspect of the target representation matters for generation, its \textit{global} \revision{semantic} information (e.g., measured by ImageNet-1K accuracy) or its spatial structure (i.e. pairwise cosine similarity between patch tokens)? Prevalent wisdom holds that stronger global semantic performance leads to better generation as a target representation. To study this, we first perform a large-scale empirical analysis across 27 different vision encoders and different model scales. The results are surprising; spatial structure, rather than global performance, drives the generation performance of a target representation. To further study this, we introduce two straightforward modifications, which specifically accentuate the transfer of \emph{spatial} information. We replace the standard MLP projection layer in REPA with a simple convolution layer and introduce a spatial normalization layer for the external representation. Surprisingly, our simple method (implemented in $<$4 lines of code), termed iREPA, consistently improves convergence speed of REPA, across a diverse set of vision encoders, model sizes, and training variants (such as REPA, REPA-E, Meanflow, JiT etc). %, etc. Our work motivates revisiting the fundamental working mechanism of representational alignment and how it can be leveraged for improved training of generative models. The code and project page are available at https://end2end-diffusion.github.io/irepa
REPA-E: Unlocking VAE for End-to-End Tuning with Latent Diffusion Transformers
Apr 14, 2025In this paper we tackle a fundamental question: "Can we train latent diffusion models together with the variational auto-encoder (VAE) tokenizer in an end-to-end manner?" Traditional deep-learning wisdom dictates that end-to-end training is often preferable when possible. However, for latent diffusion transformers, it is observed that end-to-end training both VAE and diffusion-model using standard diffusion-loss is ineffective, even causing a degradation in final performance. We show that while diffusion loss is ineffective, end-to-end training can be unlocked through the representation-alignment (REPA) loss -- allowing both VAE and diffusion model to be jointly tuned during the training process. Despite its simplicity, the proposed training recipe (REPA-E) shows remarkable performance; speeding up diffusion model training by over 17x and 45x over REPA and vanilla training recipes, respectively. Interestingly, we observe that end-to-end tuning with REPA-E also improves the VAE itself; leading to improved latent space structure and downstream generation performance. In terms of final performance, our approach sets a new state-of-the-art; achieving FID of 1.26 and 1.83 with and without classifier-free guidance on ImageNet 256 x 256. Code is available at https://end2end-diffusion.github.io.
DWIM: Towards Tool-aware Visual Reasoning via Discrepancy-aware Workflow Generation & Instruct-Masking Tuning
Mar 25, 2025
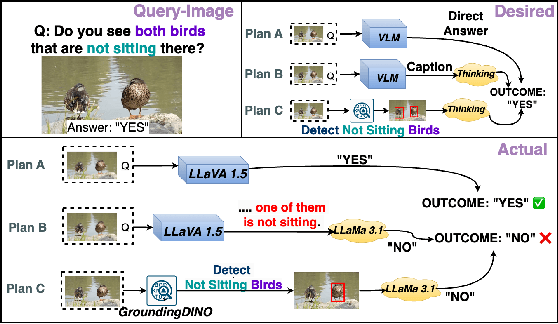
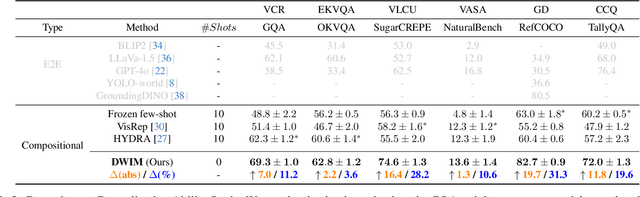
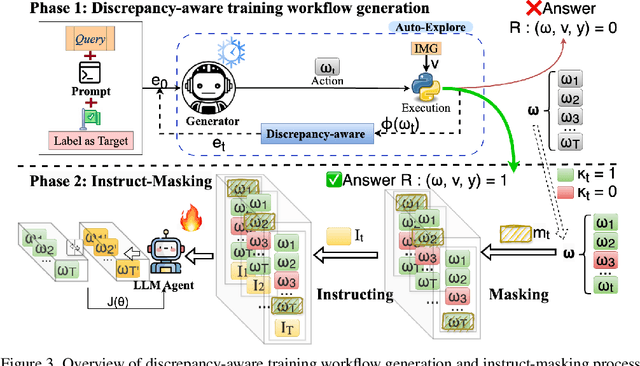
Visual reasoning (VR), which is crucial in many fields for enabling human-like visual understanding, remains highly challenging. Recently, compositional visual reasoning approaches, which leverage the reasoning abilities of large language models (LLMs) with integrated tools to solve problems, have shown promise as more effective strategies than end-to-end VR methods. However, these approaches face limitations, as frozen LLMs lack tool awareness in VR, leading to performance bottlenecks. While leveraging LLMs for reasoning is widely used in other domains, they are not directly applicable to VR due to limited training data, imperfect tools that introduce errors and reduce data collection efficiency in VR, and challenging in fine-tuning on noisy workflows. To address these challenges, we propose DWIM: i) Discrepancy-aware training Workflow generation, which assesses tool usage and extracts more viable workflows for training; and ii) Instruct-Masking fine-tuning, which guides the model to only clone effective actions, enabling the generation of more practical solutions. Our experiments demonstrate that DWIM achieves state-of-the-art performance across various VR tasks, exhibiting strong generalization on multiple widely-used datasets.
Optimizing Camera Configurations for Multi-View Pedestrian Detection
Dec 04, 2023

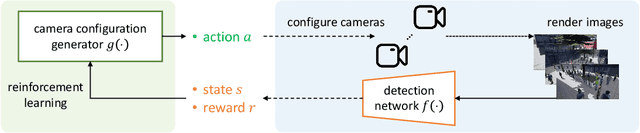

Jointly considering multiple camera views (multi-view) is very effective for pedestrian detection under occlusion. For such multi-view systems, it is critical to have well-designed camera configurations, including camera locations, directions, and fields-of-view (FoVs). Usually, these configurations are crafted based on human experience or heuristics. In this work, we present a novel solution that features a transformer-based camera configuration generator. Using reinforcement learning, this generator autonomously explores vast combinations within the action space and searches for configurations that give the highest detection accuracy according to the training dataset. The generator learns advanced techniques like maximizing coverage, minimizing occlusion, and promoting collaboration. Across multiple simulation scenarios, the configurations generated by our transformer-based model consistently outperform random search, heuristic-based methods, and configurations designed by human experts, shedding light on future camera layout optimization.
CIFAR-10-Warehouse: Broad and More Realistic Testbeds in Model Generalization Analysis
Oct 09, 2023Analyzing model performance in various unseen environments is a critical research problem in the machine learning community. To study this problem, it is important to construct a testbed with out-of-distribution test sets that have broad coverage of environmental discrepancies. However, existing testbeds typically either have a small number of domains or are synthesized by image corruptions, hindering algorithm design that demonstrates real-world effectiveness. In this paper, we introduce CIFAR-10-Warehouse, consisting of 180 datasets collected by prompting image search engines and diffusion models in various ways. Generally sized between 300 and 8,000 images, the datasets contain natural images, cartoons, certain colors, or objects that do not naturally appear. With CIFAR-10-W, we aim to enhance the evaluation and deepen the understanding of two generalization tasks: domain generalization and model accuracy prediction in various out-of-distribution environments. We conduct extensive benchmarking and comparison experiments and show that CIFAR-10-W offers new and interesting insights inherent to these tasks. We also discuss other fields that would benefit from CIFAR-10-W.