 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Camera Configurations for Multi-View Pedestrian Detection
Paper and Code
Dec 04, 2023

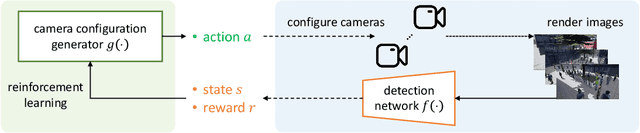

Jointly considering multiple camera views (multi-view) is very effective for pedestrian detection under occlusion. For such multi-view systems, it is critical to have well-designed camera configurations, including camera locations, directions, and fields-of-view (FoVs). Usually, these configurations are crafted based on human experience or heuristics. In this work, we present a novel solution that features a transformer-based camera configuration generator. Using reinforcement learning, this generator autonomously explores vast combinations within the action space and searches for configurations that give the highest detection accuracy according to the training dataset. The generator learns advanced techniques like maximizing coverage, minimizing occlusion, and promoting collaboration. Across multiple simulation scenarios, the configurations generated by our transformer-based model consistently outperform random search, heuristic-based methods, and configurations designed by human experts, shedding light on future camera layout optimization.