 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically Disentangled Representations
Paper and Code
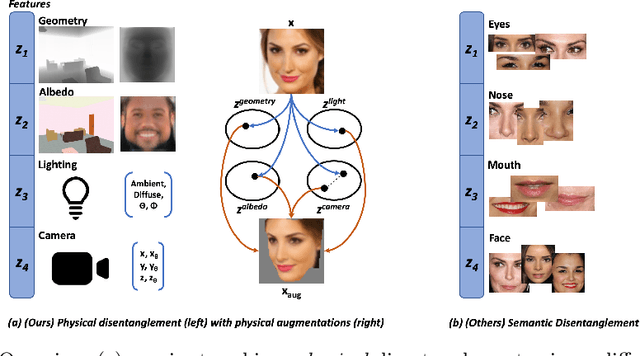

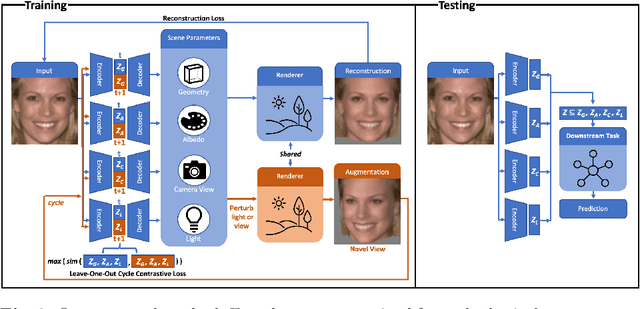

State-of-the-art methods in generative representation learning yield semantic disentanglement, but typically do not consider physical scene parameters, such as geometry, albedo, lighting, or camera. We posit that inverse rendering, a way to reverse the rendering process to recover scene parameters from an image, can also be used to learn physically disentangled representations of scenes without supervision. In this paper, we show the utility of inverse rendering in learning representations that yield improved accuracy on downstream clustering, linear classification, and segmentation tasks with the help of our novel Leave-One-Out, Cycle Contrastive loss (LOOCC), which improves disentanglement of scene parameters and robustness to out-of-distribution lighting and viewpoints. We perform a comparison of our method with other generative representation learning methods across a variety of downstream tasks, including face attribute classification, emotion recognition, identification, face segmentation, and car classification. Our physically disentangled representations yield higher accuracy than semantically disentangled alternatives across all tasks and by as much as 18%. We hope that this work will motivate future research in applying advances in inverse rendering and 3D understanding to representation learning.