 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombinatorial Privacy: Private Multi-Party Bitstream Grand Sum by Hiding in Birkhoff Polytopes
Mar 24, 2026We introduce PolyVeil, a protocol for private Boolean summation across $k$ clients that encodes private bits as permutation matrices in the Birkhoff polytope. A two-layer architecture gives the server perfect simulation-based security (statistical distance zero) while a separate aggregator faces \#P-hard likelihood inference via the permanent and mixed discriminant. Two variants (full and compressed) differ in what the aggregator observes. We develop a finite-sample $(\varepsilon,δ)$-DP analysis with explicit constants. In the full variant, where the aggregator sees a doubly stochastic matrix per client, the log-Lipschitz constant grows as $n^4 K_t$ and a signal-to-noise analysis shows the DP guarantee is non-vacuous only when the private signal is undetectable. In the compressed variant, where the aggregator sees a single scalar, the univariate density ratio yields non-vacuous $\varepsilon$ at moderate SNR, with the optimal decoy count balancing CLT accuracy against noise concentration. This exposes a fundamental tension. \#P-hardness requires the full matrix view (Birkhoff structure visible), while non-vacuous DP requires the scalar view (low dimensionality). Whether both hold simultaneously in one variant remains open. The protocol needs no PKI, has $O(k)$ communication, and outputs exact aggregates.
Learning in the Null Space: Small Singular Values for Continual Learning
Feb 25, 2026Alleviating catastrophic forgetting while enabling further learning is a primary challenge in continual learning (CL). Orthogonal-based training methods have gained attention for their efficiency and strong theoretical properties, and many existing approaches enforce orthogonality through gradient projection. In this paper, we revisit orthogonality and exploit the fact that small singular values correspond to directions that are nearly orthogonal to the input space of previous tasks. Building on this principle, we introduce NESS (Null-space Estimated from Small Singular values), a CL method that applies orthogonality directly in the weight space rather than through gradient manipulation. Specifically, NESS constructs an approximate null space using the smallest singular values of each layer's input representation and parameterizes task-specific updates via a compact low-rank adaptation (LoRA-style) formulation constrained to this subspace. The subspace basis is fixed to preserve the null-space constraint, and only a single trainable matrix is learned for each task. This design ensures that the resulting updates remain approximately in the null space of previous inputs while enabling adaptation to new tasks. Our theoretical analysis and experiments on three benchmark datasets demonstrate competitive performance, low forgetting, and stable accuracy across tasks, highlighting the role of small singular values in continual learning. The code is available at https://github.com/pacman-ctm/NESS.
Convergence of Mean Shift Algorithms for Large Bandwidths and Simultaneous Accurate Clustering
Jun 24, 2025The mean shift (MS) is a non-parametric, density-based, iterative algorithm that has prominent usage in clustering and image segmentation. A rigorous proof for its convergence in full generality remains unknown. Two significant steps in this direction were taken in the paper \cite{Gh1}, which proved that for \textit{sufficiently large bandwidth}, the MS algorithm with the Gaussian kernel always converges in any dimension, and also by the same author in \cite{Gh2}, proved that MS always converges in one dimension for kernels with differentiable, strictly decreasing, convex profiles. In the more recent paper \cite{YT}, they have proved the convergence in more generality,\textit{ without any restriction on the bandwidth}, with the assumption that the KDE $f$ has a continuous Lipschitz gradient on the closure of the convex hull of the trajectory of the iterated sequence of the mode estimate, and also satisfies the {\L}ojasiewicz property there. The main theoretical result of this paper is a generalization of those of \cite{Gh1}, where we show that (1) for\textit{ sufficiently large bandwidth} convergence is guaranteed in any dimension with \textit{any radially symmetric and strictly positive definite kernels}. The proof uses two alternate characterizations of radially symmetric positive definite smooth kernels by Schoenberg and Bernstein \cite{Fass}, and borrows some steps from the proofs in \cite{Gh1}. Although the authors acknowledge that the result in that paper is more restrictive than that of \cite{YT} due to the lower bandwidth limit, it uses a different set of assumptions than \cite{YT}, and the proof technique is different.
Safety Subspaces are Not Distinct: A Fine-Tuning Case Study
May 20, 2025
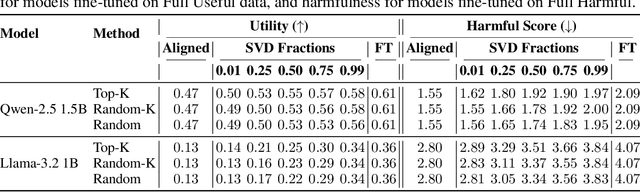


Large Language Models (LLMs) rely on safety alignment to produce socially acceptable responses. This is typically achieved through instruction tuning and reinforcement learning from human feedback. However, this alignment is known to be brittle: further fine-tuning, even on benign or lightly contaminated data, can degrade safety and reintroduce harmful behaviors. A growing body of work suggests that alignment may correspond to identifiable geometric directions in weight space, forming subspaces that could, in principle, be isolated or preserved to defend against misalignment. In this work, we conduct a comprehensive empirical study of this geometric perspective. We examine whether safety-relevant behavior is concentrated in specific subspaces, whether it can be separated from general-purpose learning, and whether harmfulness arises from distinguishable patterns in internal representations. Across both parameter and activation space, our findings are consistent: subspaces that amplify safe behaviors also amplify unsafe ones, and prompts with different safety implications activate overlapping representations. We find no evidence of a subspace that selectively governs safety. These results challenge the assumption that alignment is geometrically localized. Rather than residing in distinct directions, safety appears to emerge from entangled, high-impact components of the model's broader learning dynamics. This suggests that subspace-based defenses may face fundamental limitations and underscores the need for alternative strategies to preserve alignment under continued training. We corroborate these findings through multiple experiments on five open-source LLMs. Our code is publicly available at: https://github.com/CERT-Lab/safety-subspaces.
ABBA: Highly Expressive Hadamard Product Adaptation for Large Language Models
May 20, 2025



Large Language Models have demonstrated strong performance across a wide range of tasks, but adapting them efficiently to new domains remains a key challenge. Parameter-Efficient Fine-Tuning (PEFT) methods address this by introducing lightweight, trainable modules while keeping most pre-trained weights fixed. The prevailing approach, LoRA, models updates using a low-rank decomposition, but its expressivity is inherently constrained by the rank. Recent methods like HiRA aim to increase expressivity by incorporating a Hadamard product with the frozen weights, but still rely on the structure of the pre-trained model. We introduce ABBA, a new PEFT architecture that reparameterizes the update as a Hadamard product of two independently learnable low-rank matrices. In contrast to prior work, ABBA fully decouples the update from the pre-trained weights, enabling both components to be optimized freely. This leads to significantly higher expressivity under the same parameter budget. We formally analyze ABBA's expressive capacity and validate its advantages through matrix reconstruction experiments. Empirically, ABBA achieves state-of-the-art results on arithmetic and commonsense reasoning benchmarks, consistently outperforming existing PEFT methods by a significant margin across multiple models. Our code is publicly available at: https://github.com/CERT-Lab/abba.
HSplitLoRA: A Heterogeneous Split Parameter-Efficient Fine-Tuning Framework for Large Language Models
May 05, 2025Recently, large language models (LLMs) have achieved remarkable breakthroughs, revolutionizing the natural language processing domain and beyond. Due to immense parameter sizes, fine-tuning these models with private data for diverse downstream tasks has become mainstream. Though federated learning (FL) offers a promising solution for fine-tuning LLMs without sharing raw data, substantial computing costs hinder its democratization. Moreover, in real-world scenarios, private client devices often possess heterogeneous computing resources, further complicating LLM fine-tuning. To combat these challenges, we propose HSplitLoRA, a heterogeneous parameter-efficient fine-tuning (PEFT) framework built on split learning (SL) and low-rank adaptation (LoRA) fine-tuning, for efficiently fine-tuning LLMs on heterogeneous client devices. HSplitLoRA first identifies important weights based on their contributions to LLM training. It then dynamically configures the decomposition ranks of LoRA adapters for selected weights and determines the model split point according to varying computing budgets of client devices. Finally, a noise-free adapter aggregation mechanism is devised to support heterogeneous adapter aggregation without introducing noise. Extensive experiments demonstrate that HSplitLoRA outperforms state-of-the-art benchmarks in training accuracy and convergence speed.
Fed-SB: A Silver Bullet for Extreme Communication Efficiency and Performance in (Private) Federated LoRA Fine-Tuning
Feb 21, 2025



Low-Rank Adaptation (LoRA) has become ubiquitous for efficiently fine-tuning foundation models. However, federated fine-tuning using LoRA is challenging due to suboptimal updates arising from traditional federated averaging of individual adapters. Existing solutions either incur prohibitively high communication cost that scales linearly with the number of clients or suffer from performance degradation due to limited expressivity. We introduce Federated Silver Bullet (Fed-SB), a novel approach for federated fine-tuning of LLMs using LoRA-SB, a recently proposed low-rank adaptation method. LoRA-SB optimally aligns the optimization trajectory with the ideal low-rank full fine-tuning projection by learning a small square matrix (R) between adapters B and A, keeping other components fixed. Direct averaging of R guarantees exact updates, substantially reducing communication cost, which remains independent of the number of clients, and enables scalability. Fed-SB achieves state-of-the-art performance across commonsense reasoning, arithmetic reasoning, and language inference tasks while reducing communication costs by up to 230x. In private settings, Fed-SB further improves performance by (1) reducing trainable parameters, thereby lowering the noise required for differential privacy and (2) avoiding noise amplification introduced by other methods. Overall, Fed-SB establishes a new Pareto frontier in the tradeoff between communication and performance, offering an efficient and scalable solution for both private and non-private federated fine-tuning. Our code is publicly available at https://github.com/CERT-Lab/fed-sb.
Tackling Feature and Sample Heterogeneity in Decentralized Multi-Task Learning: A Sheaf-Theoretic Approach
Feb 03, 2025



Federated multi-task learning (FMTL) aims to simultaneously learn multiple related tasks across clients without sharing sensitive raw data. However, in the decentralized setting, existing FMTL frameworks are limited in their ability to capture complex task relationships and handle feature and sample heterogeneity across clients. To address these challenges, we introduce a novel sheaf-theoretic-based approach for FMTL. By representing client relationships using cellular sheaves, our framework can flexibly model interactions between heterogeneous client models. We formulate the sheaf-based FMTL optimization problem using sheaf Laplacian regularization and propose the Sheaf-FMTL algorithm to solve it. We show that the proposed framework provides a unified view encompassing many existing federated learning (FL) and FMTL approaches. Furthermore, we prove that our proposed algorithm, Sheaf-FMTL, achieves a sublinear convergence rate in line with state-of-the-art decentralized FMTL algorithms. Extensive experiments demonstrate that Sheaf-FMTL exhibits communication savings by sending significantly fewer bits compared to decentralized FMTL baselines.
Predicting Survival of Hemodialysis Patients using Federated Learning
Dec 14, 2024



Hemodialysis patients who are on donor lists for kidney transplant may get misidentified, delaying their wait time. Thus, predicting their survival time is crucial for optimizing waiting lists and personalizing treatment plans. Predicting survival times for patients often requires large quantities of high quality but sensitive data. This data is siloed and since individual datasets are smaller and less diverse, locally trained survival models do not perform as well as centralized ones. Hence, we propose the use of Federated Learning in the context of predicting survival for hemodialysis patients. Federated Learning or FL can have comparatively better performances than local models while not sharing data between centers. However, despite the increased use of such technologies, the application of FL in survival and even more, dialysis patients remains sparse. This paper studies the performance of FL for data of hemodialysis patients from NephroPlus, the largest private network of dialysis centers in India.
Initialization using Update Approximation is a Silver Bullet for Extremely Efficient Low-Rank Fine-Tuning
Nov 29, 2024



Low-rank adapters have become a standard approach for efficiently fine-tuning large language models (LLMs), but they often fall short of achieving the performance of full fine-tuning. We propose a method, LoRA Silver Bullet or LoRA-SB, that approximates full fine-tuning within low-rank subspaces using a carefully designed initialization strategy. We theoretically demonstrate that the architecture of LoRA-XS, which inserts a trainable (r x r) matrix between B and A while keeping other matrices fixed, provides the precise conditions needed for this approximation. We leverage its constrained update space to achieve optimal scaling for high-rank gradient updates while removing the need for hyperparameter tuning. We prove that our initialization offers an optimal low-rank approximation of the initial gradient and preserves update directions throughout training. Extensive experiments across mathematical reasoning, commonsense reasoning, and language understanding tasks demonstrate that our approach exceeds the performance of standard LoRA while using 27-90x fewer parameters, and comprehensively outperforms LoRA-XS. Our findings establish that it is possible to simulate full fine-tuning in low-rank subspaces, and achieve significant efficiency gains without sacrificing performance. Our code is publicly available at https://github.com/RaghavSinghal10/lora-sb.