 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Decoding of Stabilizer Codes under Radiation-Induced Correlated Noise
Mar 18, 2026Fault-tolerant quantum computation demands extremely low logical error rates, yet superconducting qubit arrays are subject to radiation-induced correlated noise arising from cosmic-ray muon-generated quasiparticles. The quasiparticle density is unknown and time-varying, resulting in a mismatch between the true noise statistics and the priors assumed by standard decoders, and consequently, degraded logical performance. We formalize joint noise sensing and decoding using syndrome measurements by modeling the QP density as a latent variable, which governs correlation in physical errors and syndrome measurements. Starting from a variational expectation--maximization approach, we derive an iterative algorithm that alternates between QP density estimation and syndrome-based decoding under the updated noise model. Simulations of surface-code and bivariate bicycle quantum memory under radiation-induced correlated noise demonstrate a measurable reduction in logical error probability relative to baseline decoding with a uniform prior. Beyond improved decoding performance, the inferred QP density provides diagnostic information relevant to device characterization, shielding, and chip design. These results indicate that integrating physical noise estimation into decoding can mitigate correlated noise effects and relax effective error-rate requirements for fault-tolerant quantum computation.
CAETC: Causal Autoencoding and Treatment Conditioning for Counterfactual Estimation over Time
Mar 12, 2026Counterfactual estimation over time is important in various applications, such as personalized medicine. However, time-dependent confounding bias in observational data still poses a significant challenge in achieving accurate and efficient estimation. We introduce causal autoencoding and treatment conditioning (CAETC), a novel method for this problem. Built on adversarial representation learning, our method leverages an autoencoding architecture to learn a partially invertible and treatment-invariant representation, where the outcome prediction task is cast as applying a treatment-specific conditioning on the representation. Our design is independent of the underlying sequence model and can be applied to existing architectures such as long short-term memories (LSTMs) or temporal convolution networks (TCNs). We conduct extensive experiments on synthetic, semi-synthetic, and real-world data to demonstrate that CAETC yields significant improvement in counterfactual estimation over existing methods.
Energy-Aware Routing to Large Reasoning Models
Dec 23, 2025Large reasoning models (LRMs) have heterogeneous inference energy costs based on which model is used and how much it reasons. To reduce energy, it is important to choose the right LRM and operate it in the right way. As a result, the performance of systems that dispatch tasks to different individual LRMs depend on the balance between mean energy provisioning and stochastic fluctuations. The critical regime is the unique operating point at which neither auxiliary energy nor baseline energy is systematically wasted. Increasing baseline supply shifts the system toward persistent over-supply and baseline-energy waste, while reducing supply induces persistent reliance on auxiliary energy. Yet in this regime, performance remains volatility-limited and so a second-order characterization provides further insights that we develop. Here, performance is governed by how variability is absorbed across time, models, and execution choices. This perspective highlights variance-aware routing and dispatch as a principled design axis, and provides a theoretical basis for developing energy-aware model routing policies. Routing behavior is characterized when dispatch policies are based on training-compute and inference-compute scaling laws for LRMs.
Nonlinear Federated System Identification
Aug 20, 2025



We consider federated learning of linearly-parameterized nonlinear systems. We establish theoretical guarantees on the effectiveness of federated nonlinear system identification compared to centralized approaches, demonstrating that the convergence rate improves as the number of clients increases. Although the convergence rates in the linear and nonlinear cases differ only by a constant, this constant depends on the feature map $\phi$, which can be carefully chosen in the nonlinear setting to increase excitation and improve performance. We experimentally validate our theory in physical settings where client devices are driven by i.i.d. control inputs and control policies exhibiting i.i.d. random perturbations, ensuring non-active exploration. Experiments use trajectories from nonlinear dynamical systems characterized by real-analytic feature functions, including polynomial and trigonometric components, representative of physical systems including pendulum and quadrotor dynamics. We analyze the convergence behavior of the proposed method under varying noise levels and data distributions. Results show that federated learning consistently improves convergence of any individual client as the number of participating clients increases.
Concealment of Intent: A Game-Theoretic Analysis
May 27, 2025As large language models (LLMs) grow more capable, concerns about their safe deployment have also grown. Although alignment mechanisms have been introduced to deter misuse, they remain vulnerable to carefully designed adversarial prompts. In this work, we present a scalable attack strategy: intent-hiding adversarial prompting, which conceals malicious intent through the composition of skills. We develop a game-theoretic framework to model the interaction between such attacks and defense systems that apply both prompt and response filtering. Our analysis identifies equilibrium points and reveals structural advantages for the attacker. To counter these threats, we propose and analyze a defense mechanism tailored to intent-hiding attacks. Empirically, we validate the attack's effectiveness on multiple real-world LLMs across a range of malicious behaviors, demonstrating clear advantages over existing adversarial prompting techniques.
Platonic Grounding for Efficient Multimodal Language Models
Apr 27, 2025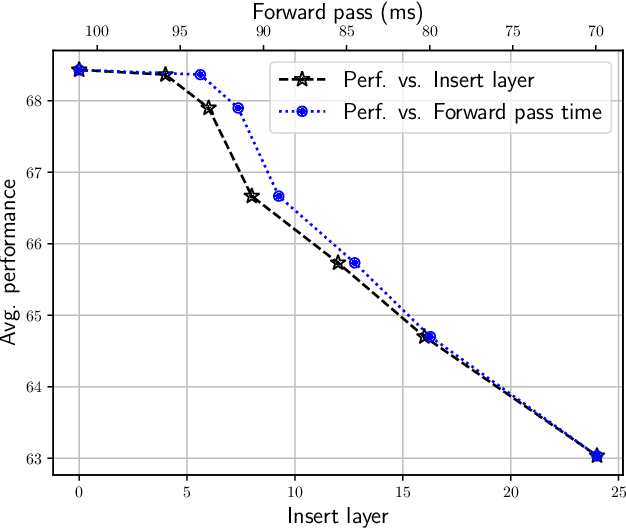

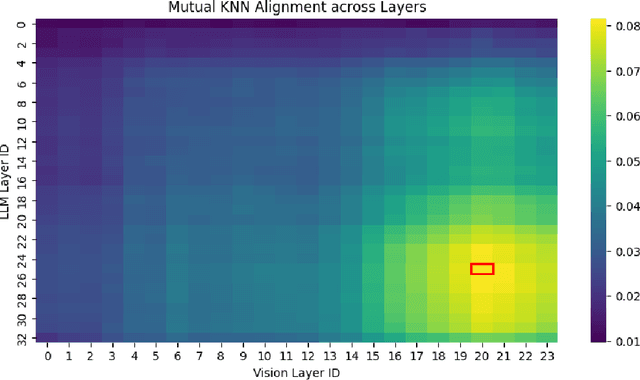
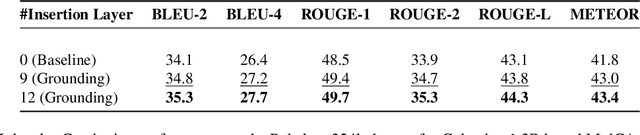
The hyperscaling of data and parameter count in Transformer-based models is yielding diminishing performance improvement, especially when weighed against training costs. Such plateauing indicates the importance of methods for more efficient finetuning and inference, while retaining similar performance. This is especially relevant for multimodal learning paradigms, where inference costs of processing multimodal tokens can determine the model's practical viability. At the same time, research on representations and mechanistic interpretability has improved our understanding of the inner workings of Transformer-based models; one such line of work reveals an implicit alignment in the deeper layers of pretrained models, across modalities. Taking inspiration from this, we motivate and propose a simple modification to existing multimodal frameworks that rely on aligning pretrained models. We demonstrate that our approach maintains and, in some cases, even improves performance of baseline methods while achieving significant gains in both training and inference-time compute. Our work also has implications for combining pretrained models into larger systems efficiently.
Spark: A System for Scientifically Creative Idea Generation
Apr 25, 2025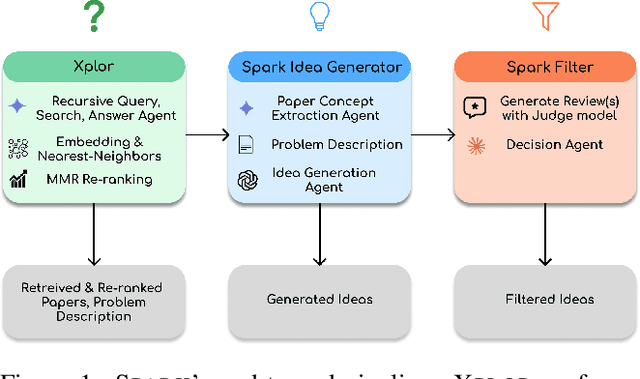


Recently, large language models (LLMs) have shown promising abilities to generate novel research ideas in science, a direction which coincides with many foundational principles in computational creativity (CC). In light of these developments, we present an idea generation system named Spark that couples retrieval-augmented idea generation using LLMs with a reviewer model named Judge trained on 600K scientific reviews from OpenReview. Our work is both a system demonstration and intended to inspire other CC researchers to explore grounding the generation and evaluation of scientific ideas within foundational CC principles. To this end, we release the annotated dataset used to train Judge, inviting other researchers to explore the use of LLMs for idea generation and creative evaluations.
Transformational Creativity in Science: A Graphical Theory
Apr 25, 2025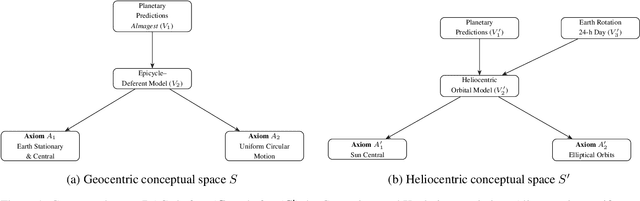

Creative processes are typically divided into three types: combinatorial, exploratory, and transformational. Here, we provide a graphical theory of transformational scientific creativity, synthesizing Boden's insight that transformational creativity arises from changes in the "enabling constraints" of a conceptual space and Kuhn's structure of scientific revolutions as resulting from paradigm shifts. We prove that modifications made to axioms of our graphical model have the most transformative potential and then illustrate how several historical instances of transformational creativity can be captured by our framework.
Fed-SB: A Silver Bullet for Extreme Communication Efficiency and Performance in (Private) Federated LoRA Fine-Tuning
Feb 21, 2025



Low-Rank Adaptation (LoRA) has become ubiquitous for efficiently fine-tuning foundation models. However, federated fine-tuning using LoRA is challenging due to suboptimal updates arising from traditional federated averaging of individual adapters. Existing solutions either incur prohibitively high communication cost that scales linearly with the number of clients or suffer from performance degradation due to limited expressivity. We introduce Federated Silver Bullet (Fed-SB), a novel approach for federated fine-tuning of LLMs using LoRA-SB, a recently proposed low-rank adaptation method. LoRA-SB optimally aligns the optimization trajectory with the ideal low-rank full fine-tuning projection by learning a small square matrix (R) between adapters B and A, keeping other components fixed. Direct averaging of R guarantees exact updates, substantially reducing communication cost, which remains independent of the number of clients, and enables scalability. Fed-SB achieves state-of-the-art performance across commonsense reasoning, arithmetic reasoning, and language inference tasks while reducing communication costs by up to 230x. In private settings, Fed-SB further improves performance by (1) reducing trainable parameters, thereby lowering the noise required for differential privacy and (2) avoiding noise amplification introduced by other methods. Overall, Fed-SB establishes a new Pareto frontier in the tradeoff between communication and performance, offering an efficient and scalable solution for both private and non-private federated fine-tuning. Our code is publicly available at https://github.com/CERT-Lab/fed-sb.
ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.