 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformational Creativity in Science: A Graphical Theory
Apr 25, 2025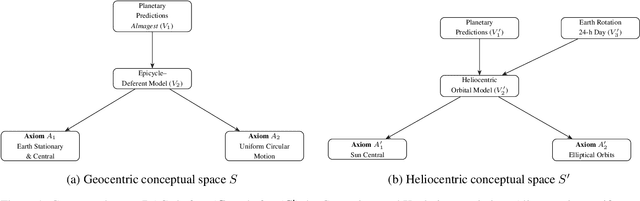

Creative processes are typically divided into three types: combinatorial, exploratory, and transformational. Here, we provide a graphical theory of transformational scientific creativity, synthesizing Boden's insight that transformational creativity arises from changes in the "enabling constraints" of a conceptual space and Kuhn's structure of scientific revolutions as resulting from paradigm shifts. We prove that modifications made to axioms of our graphical model have the most transformative potential and then illustrate how several historical instances of transformational creativity can be captured by our framework.
Spark: A System for Scientifically Creative Idea Generation
Apr 25, 2025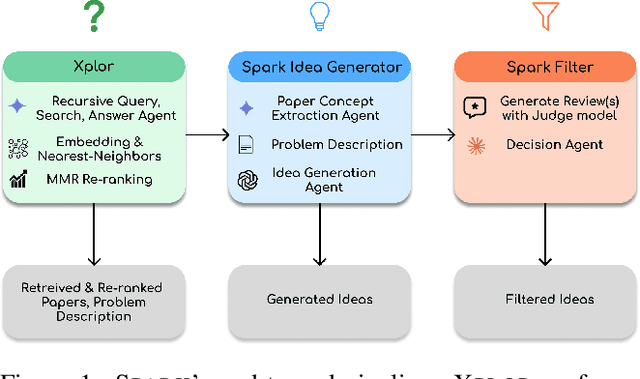


Recently, large language models (LLMs) have shown promising abilities to generate novel research ideas in science, a direction which coincides with many foundational principles in computational creativity (CC). In light of these developments, we present an idea generation system named Spark that couples retrieval-augmented idea generation using LLMs with a reviewer model named Judge trained on 600K scientific reviews from OpenReview. Our work is both a system demonstration and intended to inspire other CC researchers to explore grounding the generation and evaluation of scientific ideas within foundational CC principles. To this end, we release the annotated dataset used to train Judge, inviting other researchers to explore the use of LLMs for idea generation and creative evaluations.
Towards Understanding the Role of Sharpness-Aware Minimization Algorithms for Out-of-Distribution Generalization
Dec 06, 2024Recently, sharpness-aware minimization (SAM) has emerged as a promising method to improve generalization by minimizing sharpness, which is known to correlate well with generalization ability. Since the original proposal of SAM, many variants of SAM have been proposed to improve its accuracy and efficiency, but comparisons have mainly been restricted to the i.i.d. setting. In this paper we study SAM for out-of-distribution (OOD) generalization. First, we perform a comprehensive comparison of eight SAM variants on zero-shot OOD generalization, finding that the original SAM outperforms the Adam baseline by $4.76\%$ and the strongest SAM variants outperform the Adam baseline by $8.01\%$ on average. We then provide an OOD generalization bound in terms of sharpness for this setting. Next, we extend our study of SAM to the related setting of gradual domain adaptation (GDA), another form of OOD generalization where intermediate domains are constructed between the source and target domains, and iterative self-training is done on intermediate domains, to improve the overall target domain error. In this setting, our experimental results demonstrate that the original SAM outperforms the baseline of Adam on each of the experimental datasets by $0.82\%$ on average and the strongest SAM variants outperform Adam by $1.52\%$ on average. We then provide a generalization bound for SAM in the GDA setting. Asymptotically, this generalization bound is no better than the one for self-training in the literature of GDA. This highlights a further disconnection between the theoretical justification for SAM versus its empirical performance, with recent work finding that low sharpness alone does not account for all of SAM's generalization benefits. For future work, we provide several potential avenues for obtaining a tighter analysis for SAM in the OOD setting.
Comparative Study on the Effects of Noise in ML-Based Anxiety Detection
Jun 23, 2023Wearable health devices are ushering in a new age of continuous and noninvasive remote monitoring. One application of this technology is in anxiety detection. Many advancements in anxiety detection have happened in controlled lab settings, but noise prevents these advancements from generalizing to real-world conditions. We seek to progress the field by studying how noise impacts model performance and developing models that are robust to noisy, real-world conditions and, hence, attuned to the commotion of everyday life. In this study we look to investigate why and how previous methods have failed. Using the wearable stress and affect detection (WESAD) dataset, we compare the effect of various intensities of noise on machine learning models classifying levels of physiological arousal in the three-class classification problem: baseline vs. stress vs. amusement. Before introducing noise, our baseline model performance reaches 98.7%, compared to Schmidt 2018's 80.3%. We discuss potential sources of this discrepancy in results through a careful evaluation of feature extraction and model architecture choices. Finally, after the introduction of noise, we provide a thorough analysis of the effect of noise on each model architecture.