 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlatonic Grounding for Efficient Multimodal Language Models
Apr 27, 2025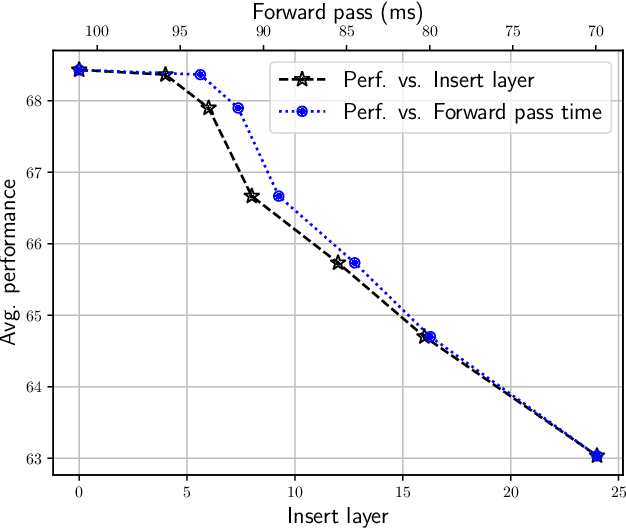

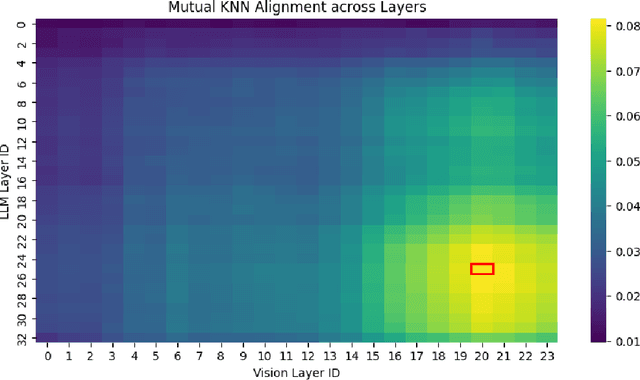
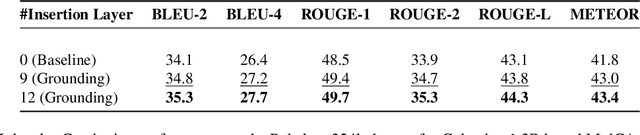
The hyperscaling of data and parameter count in Transformer-based models is yielding diminishing performance improvement, especially when weighed against training costs. Such plateauing indicates the importance of methods for more efficient finetuning and inference, while retaining similar performance. This is especially relevant for multimodal learning paradigms, where inference costs of processing multimodal tokens can determine the model's practical viability. At the same time, research on representations and mechanistic interpretability has improved our understanding of the inner workings of Transformer-based models; one such line of work reveals an implicit alignment in the deeper layers of pretrained models, across modalities. Taking inspiration from this, we motivate and propose a simple modification to existing multimodal frameworks that rely on aligning pretrained models. We demonstrate that our approach maintains and, in some cases, even improves performance of baseline methods while achieving significant gains in both training and inference-time compute. Our work also has implications for combining pretrained models into larger systems efficiently.
3D Face Style Transfer with a Hybrid Solution of NeRF and Mesh Rasterization
Nov 22, 2023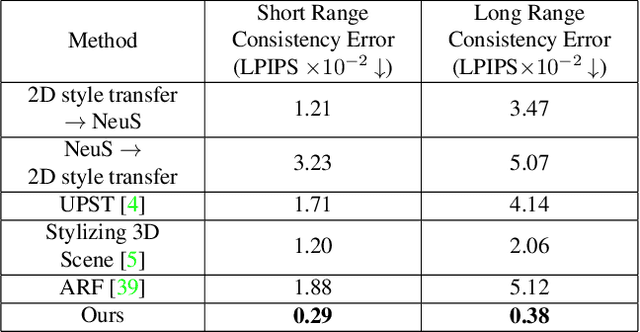
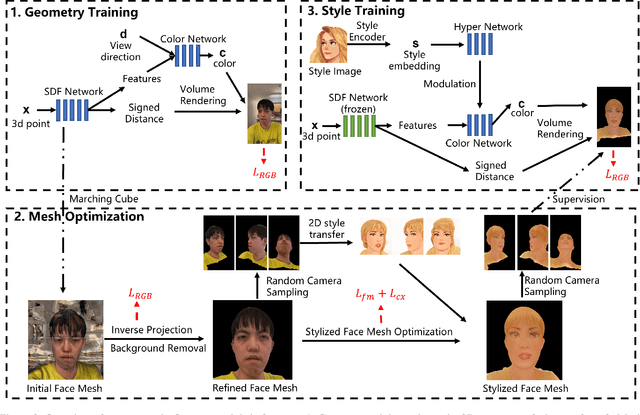


Style transfer for human face has been widely researched in recent years. Majority of the existing approaches work in 2D image domain and have 3D inconsistency issue when applied on different viewpoints of the same face. In this paper, we tackle the problem of 3D face style transfer which aims at generating stylized novel views of a 3D human face with multi-view consistency. We propose to use a neural radiance field (NeRF) to represent 3D human face and combine it with 2D style transfer to stylize the 3D face. We find that directly training a NeRF on stylized images from 2D style transfer brings in 3D inconsistency issue and causes blurriness. On the other hand, training a NeRF jointly with 2D style transfer objectives shows poor convergence due to the identity and head pose gap between style image and content image. It also poses challenge in training time and memory due to the need of volume rendering for full image to apply style transfer loss functions. We therefore propose a hybrid framework of NeRF and mesh rasterization to combine the benefits of high fidelity geometry reconstruction of NeRF and fast rendering speed of mesh. Our framework consists of three stages: 1. Training a NeRF model on input face images to learn the 3D geometry; 2. Extracting a mesh from the trained NeRF model and optimizing it with style transfer objectives via differentiable rasterization; 3. Training a new color network in NeRF conditioned on a style embedding to enable arbitrary style transfer to the 3D face. Experiment results show that our approach generates high quality face style transfer with great 3D consistency, while also enabling a flexible style control.
Language Grounded QFormer for Efficient Vision Language Understanding
Nov 13, 2023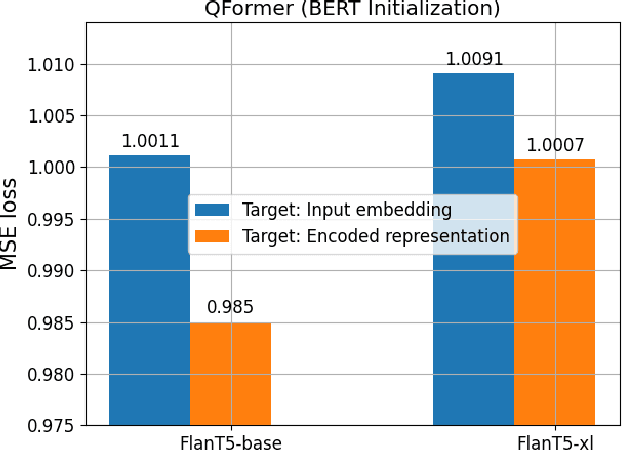
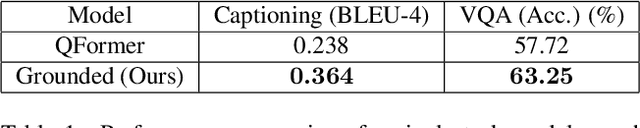
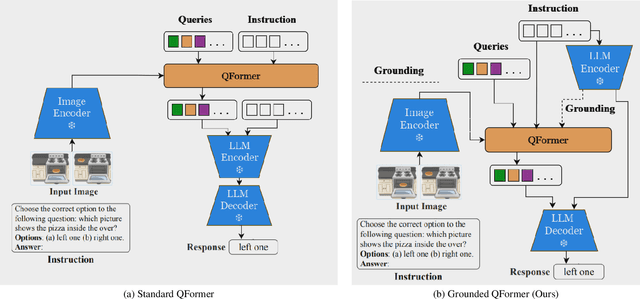

Large-scale pretraining and instruction tuning have been successful for training general-purpose language models with broad competencies. However, extending to general-purpose vision-language models is challenging due to the distributional diversity in visual inputs. A recent line of work explores vision-language instruction tuning, taking inspiration from the Query Transformer (QFormer) approach proposed in BLIP-2 models for bridging frozen modalities. However, these approaches rely heavily on large-scale multi-modal pretraining for representation learning before eventual finetuning, incurring a huge computational overhead, poor scaling, and limited accessibility. To that end, we propose a more efficient method for QFormer-based vision-language alignment and demonstrate the effectiveness of our strategy compared to existing baselines in improving the efficiency of vision-language pretraining.
Avoiding spurious correlations via logit correction
Dec 02, 2022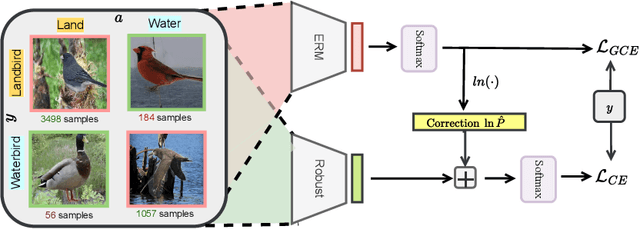
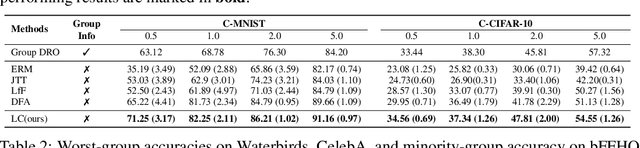
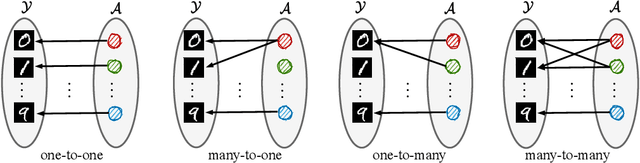
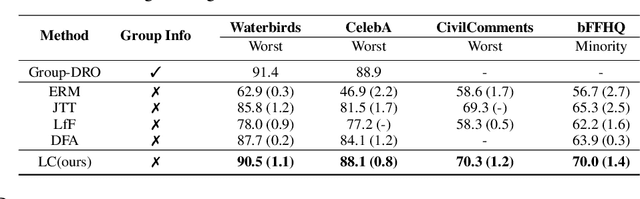
Empirical studies suggest that machine learning models trained with empirical risk minimization (ERM) often rely on attributes that may be spuriously correlated with the class labels. Such models typically lead to poor performance during inference for data lacking such correlations. In this work, we explicitly consider a situation where potential spurious correlations are present in the majority of training data. In contrast with existing approaches, which use the ERM model outputs to detect the samples without spurious correlations, and either heuristically upweighting or upsampling those samples; we propose the logit correction (LC) loss, a simple yet effective improvement on the softmax cross-entropy loss, to correct the sample logit. We demonstrate that minimizing the LC loss is equivalent to maximizing the group-balanced accuracy, so the proposed LC could mitigate the negative impacts of spurious correlations. Our extensive experimental results further reveal that the proposed LC loss outperforms the SoTA solutions on multiple popular benchmarks by a large margin, an average 5.5% absolute improvement, without access to spurious attribute labels. LC is also competitive with oracle methods that make use of the attribute labels. Code is available at https://github.com/shengliu66/LC.
Multi-modal Tracking for Object based SLAM
Mar 14, 2016
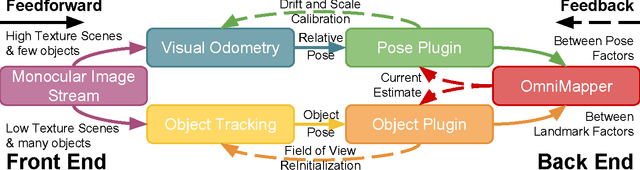
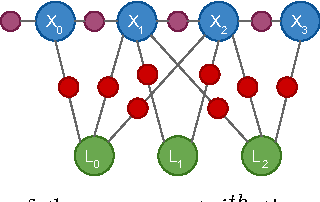
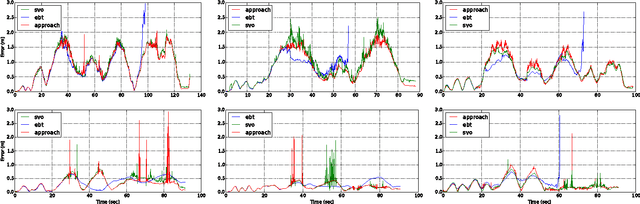
We present an on-line 3D visual object tracking framework for monocular cameras by incorporating spatial knowledge and uncertainty from semantic mapping along with high frequency measurements from visual odometry. Using a combination of vision and odometry that are tightly integrated we can increase the overall performance of object based tracking for semantic mapping. We present a framework for integration of the two data-sources into a coherent framework through information based fusion/arbitration. We demonstrate the framework in the context of OmniMapper[1] and present results on 6 challenging sequences over multiple objects compared to data obtained from a motion capture systems. We are able to achieve a mean error of 0.23m for per frame tracking showing 9% relative error less than state of the art tracker.
Dynamic Body VSLAM with Semantic Constraints
Apr 27, 2015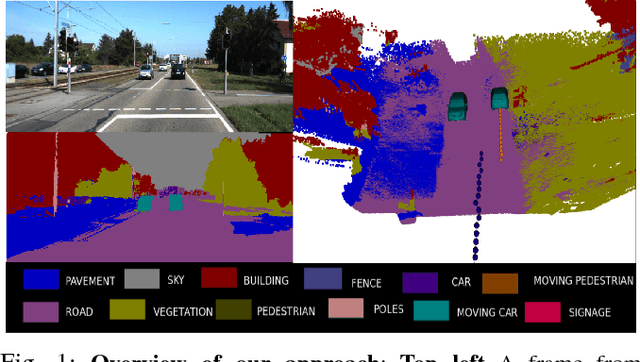

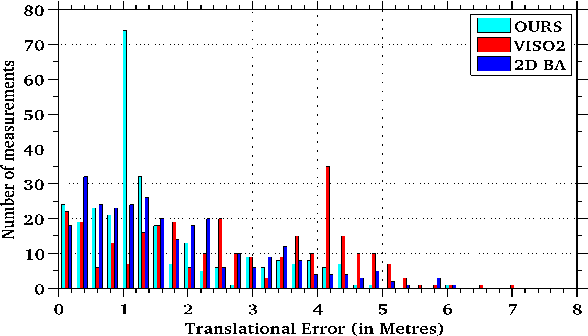
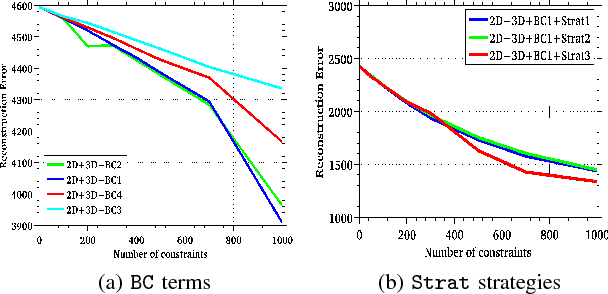
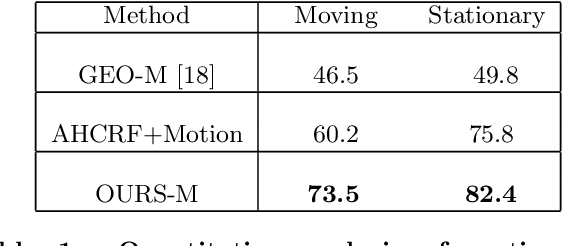
Image based reconstruction of urban environments is a challenging problem that deals with optimization of large number of variables, and has several sources of errors like the presence of dynamic objects. Since most large scale approaches make the assumption of observing static scenes, dynamic objects are relegated to the noise modeling section of such systems. This is an approach of convenience since the RANSAC based framework used to compute most multiview geometric quantities for static scenes naturally confine dynamic objects to the class of outlier measurements. However, reconstructing dynamic objects along with the static environment helps us get a complete picture of an urban environment. Such understanding can then be used for important robotic tasks like path planning for autonomous navigation, obstacle tracking and avoidance, and other areas. In this paper, we propose a system for robust SLAM that works in both static and dynamic environments. To overcome the challenge of dynamic objects in the scene, we propose a new model to incorporate semantic constraints into the reconstruction algorithm. While some of these constraints are based on multi-layered dense CRFs trained over appearance as well as motion cues, other proposed constraints can be expressed as additional terms in the bundle adjustment optimization process that does iterative refinement of 3D structure and camera / object motion trajectories. We show results on the challenging KITTI urban dataset for accuracy of motion segmentation and reconstruction of the trajectory and shape of moving objects relative to ground truth. We are able to show average relative error reduction by a significant amount for moving object trajectory reconstruction relative to state-of-the-art methods like VISO 2, as well as standard bundle adjustment algorithms.
Semantic Motion Segmentation Using Dense CRF Formulation
Apr 24, 2015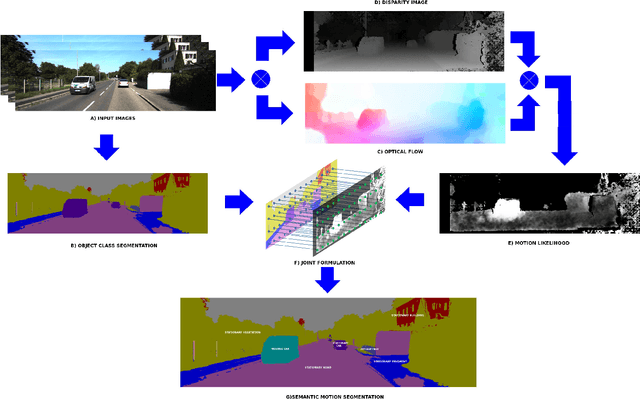
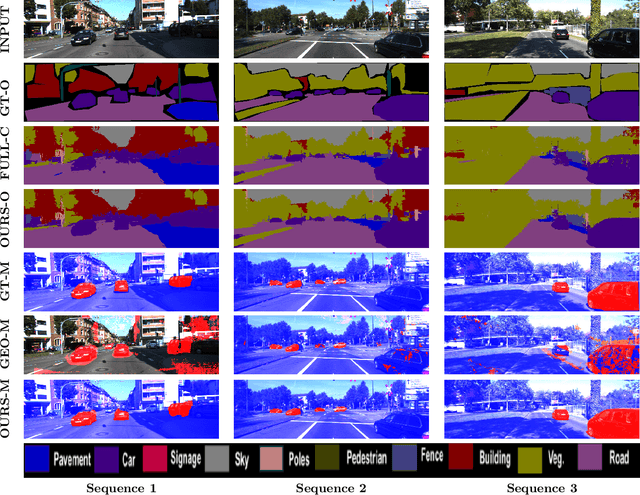

While the literature has been fairly dense in the areas of scene understanding and semantic labeling there have been few works that make use of motion cues to embellish semantic performance and vice versa. In this paper, we address the problem of semantic motion segmentation, and show how semantic and motion priors augments performance. We pro- pose an algorithm that jointly infers the semantic class and motion labels of an object. Integrating semantic, geometric and optical ow based constraints into a dense CRF-model we infer both the object class as well as motion class, for each pixel. We found improvement in performance using a fully connected CRF as compared to a standard clique-based CRFs. For inference, we use a Mean Field approximation based algorithm. Our method outperforms recently pro- posed motion detection algorithms and also improves the semantic labeling compared to the state-of-the-art Automatic Labeling Environment algorithm on the challenging KITTI dataset especially for object classes such as pedestrians and cars that are critical to an outdoor robotic navigation scenario.
Top Down Approach to Multiple Plane Detection
Dec 26, 2013
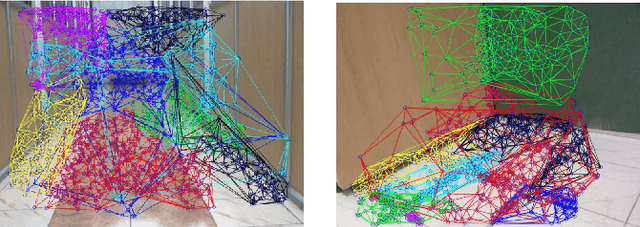

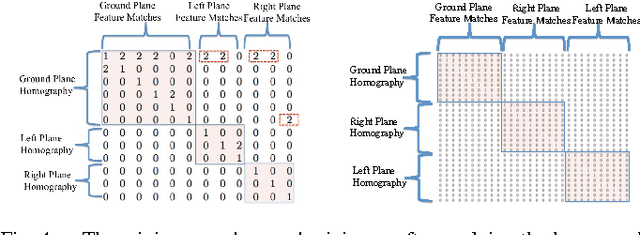
Detecting multiple planes in images is a challenging problem, but one with many applications. Recent work such as J-Linkage and Ordered Residual Kernels have focussed on developing a domain independent approach to detect multiple structures. These multiple structure detection methods are then used for estimating multiple homographies given feature matches between two images. Features participating in the multiple homographies detected, provide us the multiple scene planes. We show that these methods provide locally optimal results and fail to merge detected planar patches to the true scene planes. These methods use only residues obtained on applying homography of one plane to another as cue for merging. In this paper, we develop additional cues such as local consistency of planes, local normals, texture etc. to perform better classification and merging . We formulate the classification as an MRF problem and use TRWS message passing algorithm to solve non metric energy terms and complex sparse graph structure. We show results on challenging dataset common in robotics navigation scenarios where our method shows accuracy of more than 85 percent on average while being close or same as the actual number of scene planes.