 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Grounded QFormer for Efficient Vision Language Understanding
Paper and Code
Nov 13, 2023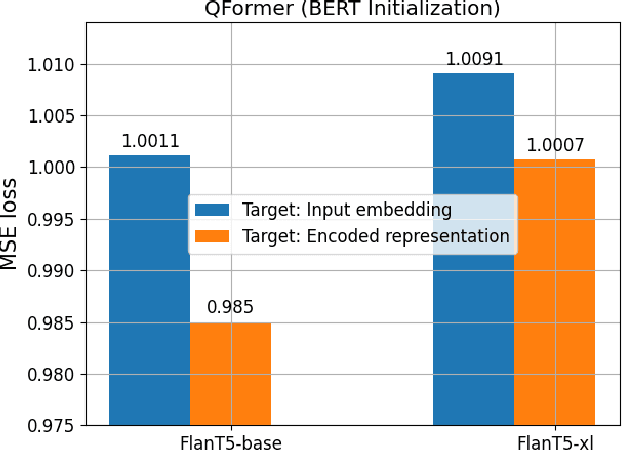
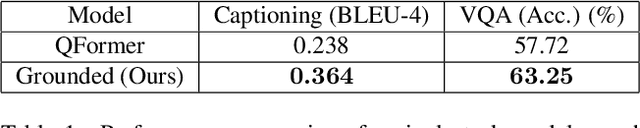
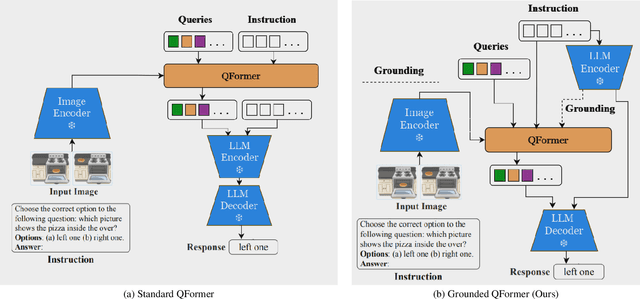

Large-scale pretraining and instruction tuning have been successful for training general-purpose language models with broad competencies. However, extending to general-purpose vision-language models is challenging due to the distributional diversity in visual inputs. A recent line of work explores vision-language instruction tuning, taking inspiration from the Query Transformer (QFormer) approach proposed in BLIP-2 models for bridging frozen modalities. However, these approaches rely heavily on large-scale multi-modal pretraining for representation learning before eventual finetuning, incurring a huge computational overhead, poor scaling, and limited accessibility. To that end, we propose a more efficient method for QFormer-based vision-language alignment and demonstrate the effectiveness of our strategy compared to existing baselines in improving the efficiency of vision-language pretraining.