 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlatonic Grounding for Efficient Multimodal Language Models
Apr 27, 2025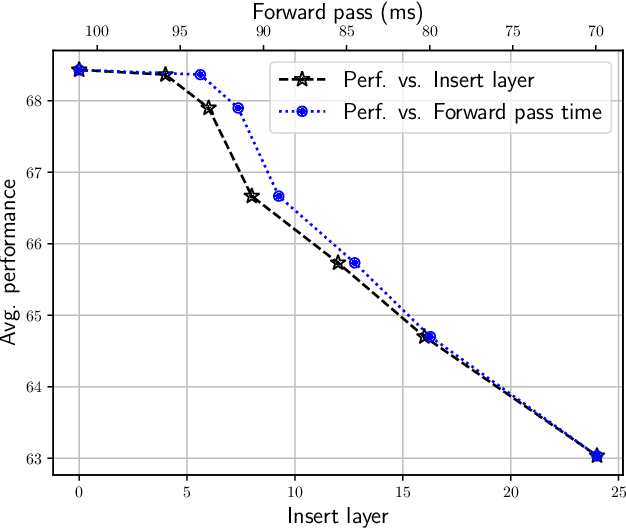

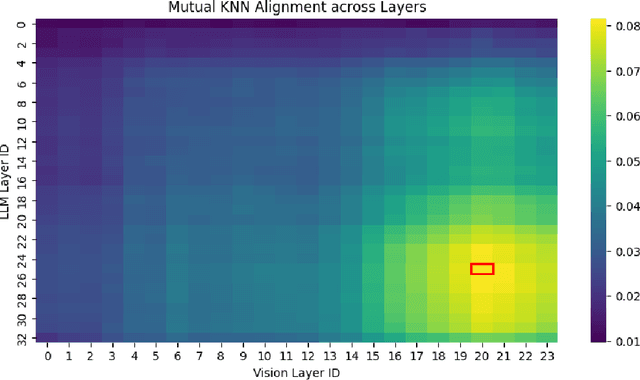
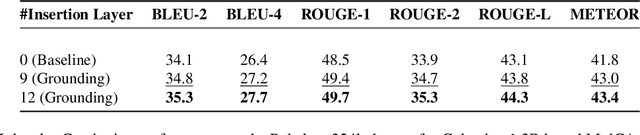
The hyperscaling of data and parameter count in Transformer-based models is yielding diminishing performance improvement, especially when weighed against training costs. Such plateauing indicates the importance of methods for more efficient finetuning and inference, while retaining similar performance. This is especially relevant for multimodal learning paradigms, where inference costs of processing multimodal tokens can determine the model's practical viability. At the same time, research on representations and mechanistic interpretability has improved our understanding of the inner workings of Transformer-based models; one such line of work reveals an implicit alignment in the deeper layers of pretrained models, across modalities. Taking inspiration from this, we motivate and propose a simple modification to existing multimodal frameworks that rely on aligning pretrained models. We demonstrate that our approach maintains and, in some cases, even improves performance of baseline methods while achieving significant gains in both training and inference-time compute. Our work also has implications for combining pretrained models into larger systems efficiently.
Language Grounded QFormer for Efficient Vision Language Understanding
Nov 13, 2023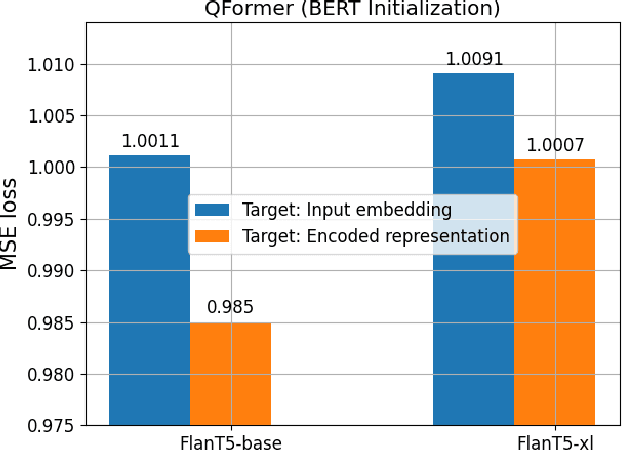
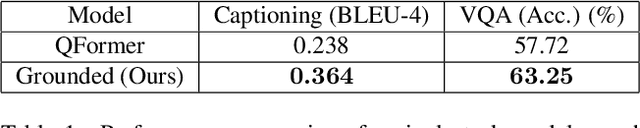
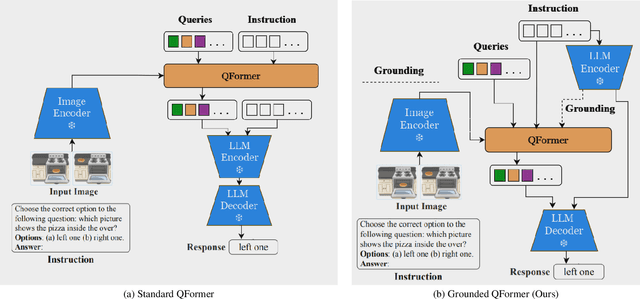

Large-scale pretraining and instruction tuning have been successful for training general-purpose language models with broad competencies. However, extending to general-purpose vision-language models is challenging due to the distributional diversity in visual inputs. A recent line of work explores vision-language instruction tuning, taking inspiration from the Query Transformer (QFormer) approach proposed in BLIP-2 models for bridging frozen modalities. However, these approaches rely heavily on large-scale multi-modal pretraining for representation learning before eventual finetuning, incurring a huge computational overhead, poor scaling, and limited accessibility. To that end, we propose a more efficient method for QFormer-based vision-language alignment and demonstrate the effectiveness of our strategy compared to existing baselines in improving the efficiency of vision-language pretraining.
Avoiding spurious correlations via logit correction
Dec 02, 2022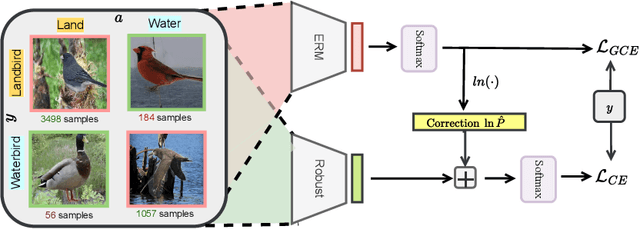
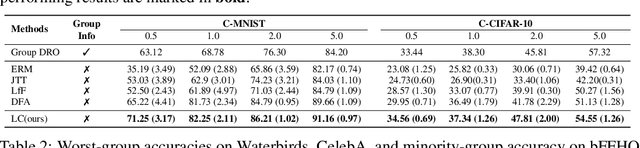
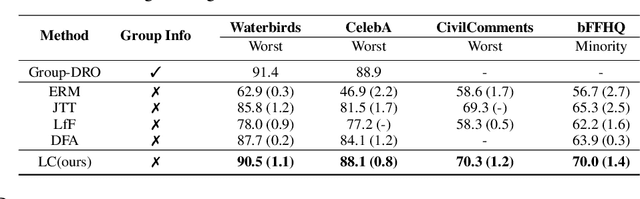
Empirical studies suggest that machine learning models trained with empirical risk minimization (ERM) often rely on attributes that may be spuriously correlated with the class labels. Such models typically lead to poor performance during inference for data lacking such correlations. In this work, we explicitly consider a situation where potential spurious correlations are present in the majority of training data. In contrast with existing approaches, which use the ERM model outputs to detect the samples without spurious correlations, and either heuristically upweighting or upsampling those samples; we propose the logit correction (LC) loss, a simple yet effective improvement on the softmax cross-entropy loss, to correct the sample logit. We demonstrate that minimizing the LC loss is equivalent to maximizing the group-balanced accuracy, so the proposed LC could mitigate the negative impacts of spurious correlations. Our extensive experimental results further reveal that the proposed LC loss outperforms the SoTA solutions on multiple popular benchmarks by a large margin, an average 5.5% absolute improvement, without access to spurious attribute labels. LC is also competitive with oracle methods that make use of the attribute labels. Code is available at https://github.com/shengliu66/LC.