 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcealment of Intent: A Game-Theoretic Analysis
May 27, 2025As large language models (LLMs) grow more capable, concerns about their safe deployment have also grown. Although alignment mechanisms have been introduced to deter misuse, they remain vulnerable to carefully designed adversarial prompts. In this work, we present a scalable attack strategy: intent-hiding adversarial prompting, which conceals malicious intent through the composition of skills. We develop a game-theoretic framework to model the interaction between such attacks and defense systems that apply both prompt and response filtering. Our analysis identifies equilibrium points and reveals structural advantages for the attacker. To counter these threats, we propose and analyze a defense mechanism tailored to intent-hiding attacks. Empirically, we validate the attack's effectiveness on multiple real-world LLMs across a range of malicious behaviors, demonstrating clear advantages over existing adversarial prompting techniques.
Platonic Grounding for Efficient Multimodal Language Models
Apr 27, 2025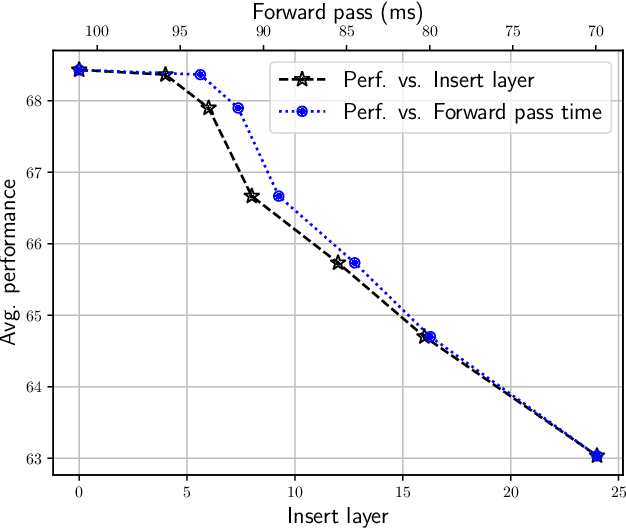

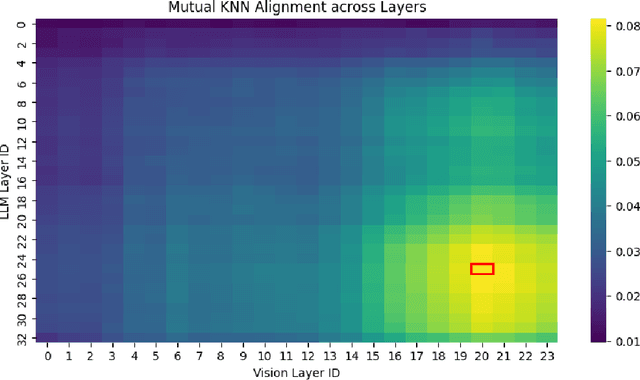
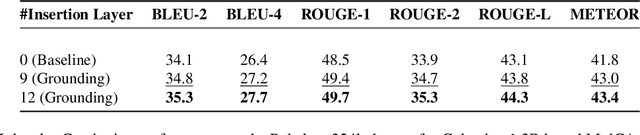
The hyperscaling of data and parameter count in Transformer-based models is yielding diminishing performance improvement, especially when weighed against training costs. Such plateauing indicates the importance of methods for more efficient finetuning and inference, while retaining similar performance. This is especially relevant for multimodal learning paradigms, where inference costs of processing multimodal tokens can determine the model's practical viability. At the same time, research on representations and mechanistic interpretability has improved our understanding of the inner workings of Transformer-based models; one such line of work reveals an implicit alignment in the deeper layers of pretrained models, across modalities. Taking inspiration from this, we motivate and propose a simple modification to existing multimodal frameworks that rely on aligning pretrained models. We demonstrate that our approach maintains and, in some cases, even improves performance of baseline methods while achieving significant gains in both training and inference-time compute. Our work also has implications for combining pretrained models into larger systems efficiently.
ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
SwitchCIT: Switching for Continual Instruction Tuning of Large Language Models
Jul 16, 2024Large language models (LLMs) have exhibited impressive capabilities in various domains, particularly in general language understanding. However these models, trained on massive text data, may not be finely optimized for specific tasks triggered by instructions. Continual instruction tuning is crucial to adapt LLMs to evolving tasks and domains, ensuring their effectiveness and relevance across a wide range of applications. In the context of continual instruction tuning, where models are sequentially trained on different tasks, catastrophic forgetting can occur, leading to performance degradation on previously learned tasks. This work addresses the catastrophic forgetting in continual instruction learning for LLMs through a switching mechanism for routing computations to parameter-efficient tuned models. We demonstrate the effectiveness of our method through experiments on continual instruction tuning of different natural language generation tasks.
Transformer-based Causal Language Models Perform Clustering
Feb 19, 2024Even though large language models (LLMs) have demonstrated remarkable capability in solving various natural language tasks, the capability of an LLM to follow human instructions is still a concern. Recent works have shown great improvements in the instruction-following capability via additional training for instruction-following tasks. However, the mechanisms responsible for effective instruction-following capabilities remain inadequately understood. Here, we introduce a simplified instruction-following task and use synthetic datasets to analyze a Transformer-based causal language model. Our findings suggest that the model learns task-specific information by clustering data within its hidden space, with this clustering process evolving dynamically during learning. We also demonstrate how this phenomenon assists the model in handling unseen instances and validate our results in a more realistic setting.
A Meta-Learning Perspective on Transformers for Causal Language Modeling
Oct 09, 2023The Transformer architecture has become prominent in developing large causal language models. However, mechanisms to explain its capabilities are not well understood. Focused on the training process, here we establish a meta-learning view of the Transformer architecture when trained for the causal language modeling task, by explicating an inner optimization process that may happen within the Transformer. Further, from within the inner optimization, we discover and theoretically analyze a special characteristic of the norms of learned token representations within Transformer-based causal language models. Our analysis is supported by experiments conducted on pre-trained large language models and real-world data.