 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Face Style Transfer with a Hybrid Solution of NeRF and Mesh Rasterization
Nov 22, 2023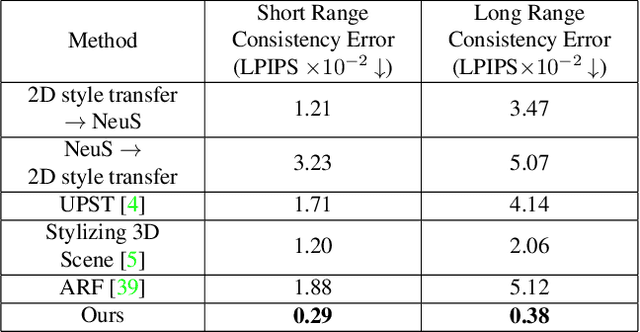
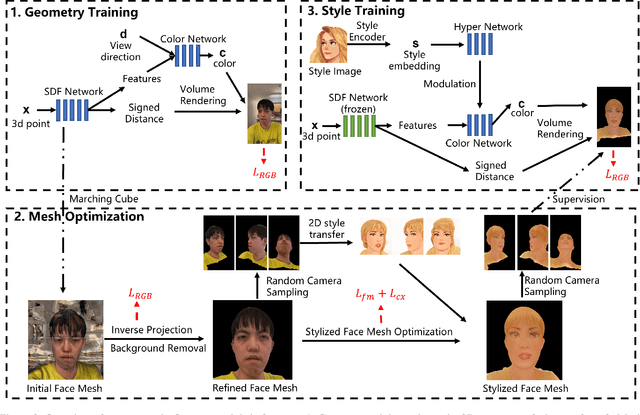


Style transfer for human face has been widely researched in recent years. Majority of the existing approaches work in 2D image domain and have 3D inconsistency issue when applied on different viewpoints of the same face. In this paper, we tackle the problem of 3D face style transfer which aims at generating stylized novel views of a 3D human face with multi-view consistency. We propose to use a neural radiance field (NeRF) to represent 3D human face and combine it with 2D style transfer to stylize the 3D face. We find that directly training a NeRF on stylized images from 2D style transfer brings in 3D inconsistency issue and causes blurriness. On the other hand, training a NeRF jointly with 2D style transfer objectives shows poor convergence due to the identity and head pose gap between style image and content image. It also poses challenge in training time and memory due to the need of volume rendering for full image to apply style transfer loss functions. We therefore propose a hybrid framework of NeRF and mesh rasterization to combine the benefits of high fidelity geometry reconstruction of NeRF and fast rendering speed of mesh. Our framework consists of three stages: 1. Training a NeRF model on input face images to learn the 3D geometry; 2. Extracting a mesh from the trained NeRF model and optimizing it with style transfer objectives via differentiable rasterization; 3. Training a new color network in NeRF conditioned on a style embedding to enable arbitrary style transfer to the 3D face. Experiment results show that our approach generates high quality face style transfer with great 3D consistency, while also enabling a flexible style control.
Adaptive Semantic Segmentation with a Strategic Curriculum of Proxy Labels
Nov 08, 2018
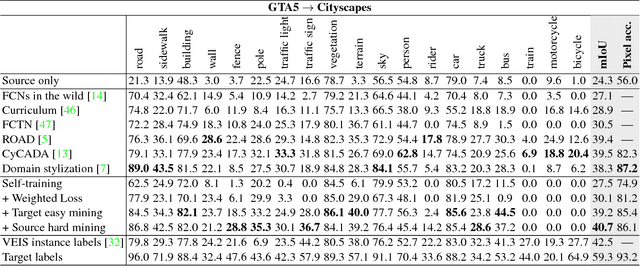
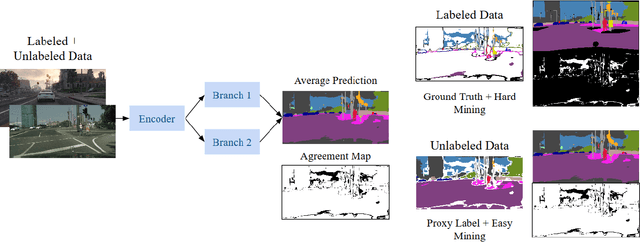
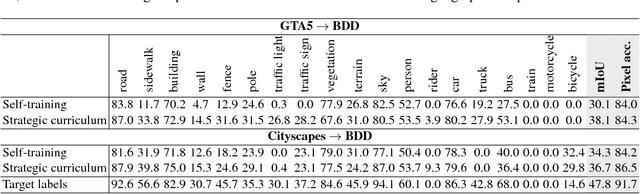
Training deep networks for semantic segmentation requires annotation of large amounts of data, which can be time-consuming and expensive. Unfortunately, these trained networks still generalize poorly when tested in domains not consistent with the training data. In this paper, we show that by carefully presenting a mixture of labeled source domain and proxy-labeled target domain data to a network, we can achieve state-of-the-art unsupervised domain adaptation results. With our design, the network progressively learns features specific to the target domain using annotation from only the source domain. We generate proxy labels for the target domain using the network's own predictions. Our architecture then allows selective mining of easy samples from this set of proxy labels, and hard samples from the annotated source domain. We conduct a series of experiments with the GTA5, Cityscapes and BDD100k datasets on synthetic-to-real domain adaptation and geographic domain adaptation, showing the advantages of our method over baselines and existing approaches.
Cutting Down Training Memory by Re-fowarding
Jul 31, 2018
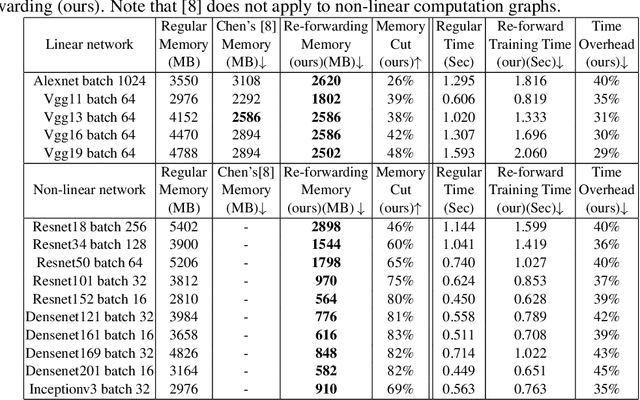

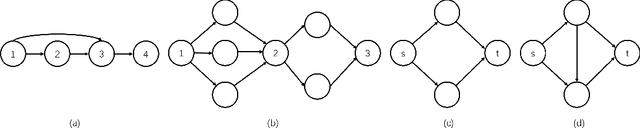
Deep Neutral Networks(DNN) require huge GPU memory when training on modern image/video databases. Unfortunately, the GPU memory is always finite, which limits the image resolution, batch size, and learning rate that could be tuned for better performances. In this paper, we propose a novel approach, called Re-forwarding, that substantially reduces memory usage in training. Our approach only saves the tensors at a subset of layers during the first forward, and conduct extra local forwards (the Re-forwarding process) to compute the missing tensors needed during backward. The total memory cost becomes the sum of (1) the cost at the subset of layers and (2) the maximum cost of the re-forwarding processes. We propose theories and algorithms that achieve the optimal memory solutions for DNNs with either linear or arbitrary optimization graphs. Experiments show that Re-forwarding cut down huge amount of training memory on all popular DNNs such as Alexnet, VGG net, ResNet, Densenet and Inception net.