 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Semantic Segmentation with a Strategic Curriculum of Proxy Labels
Paper and Code
Nov 08, 2018
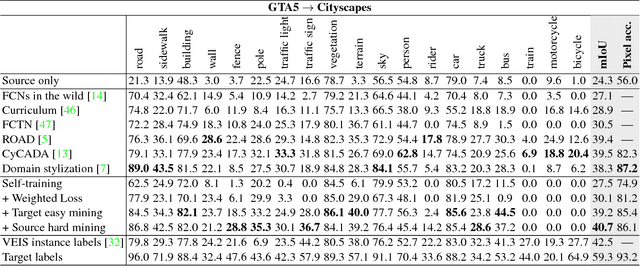
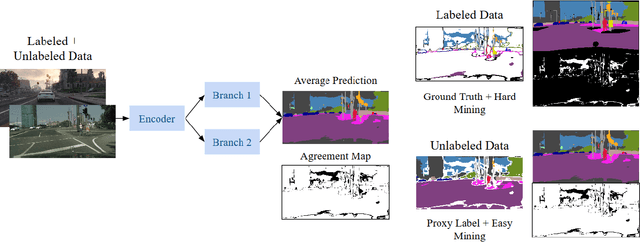
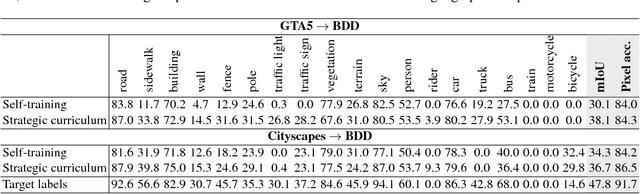
Training deep networks for semantic segmentation requires annotation of large amounts of data, which can be time-consuming and expensive. Unfortunately, these trained networks still generalize poorly when tested in domains not consistent with the training data. In this paper, we show that by carefully presenting a mixture of labeled source domain and proxy-labeled target domain data to a network, we can achieve state-of-the-art unsupervised domain adaptation results. With our design, the network progressively learns features specific to the target domain using annotation from only the source domain. We generate proxy labels for the target domain using the network's own predictions. Our architecture then allows selective mining of easy samples from this set of proxy labels, and hard samples from the annotated source domain. We conduct a series of experiments with the GTA5, Cityscapes and BDD100k datasets on synthetic-to-real domain adaptation and geographic domain adaptation, showing the advantages of our method over baselines and existing approaches.