 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCutting Down Training Memory by Re-fowarding
Paper and Code

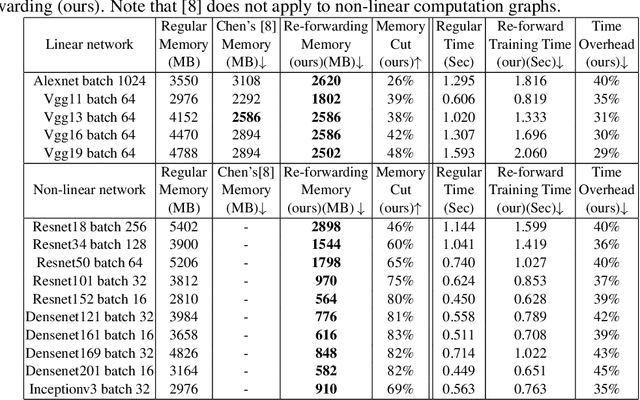

Deep Neutral Networks(DNN) require huge GPU memory when training on modern image/video databases. Unfortunately, the GPU memory is always finite, which limits the image resolution, batch size, and learning rate that could be tuned for better performances. In this paper, we propose a novel approach, called Re-forwarding, that substantially reduces memory usage in training. Our approach only saves the tensors at a subset of layers during the first forward, and conduct extra local forwards (the Re-forwarding process) to compute the missing tensors needed during backward. The total memory cost becomes the sum of (1) the cost at the subset of layers and (2) the maximum cost of the re-forwarding processes. We propose theories and algorithms that achieve the optimal memory solutions for DNNs with either linear or arbitrary optimization graphs. Experiments show that Re-forwarding cut down huge amount of training memory on all popular DNNs such as Alexnet, VGG net, ResNet, Densenet and Inception net.