 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWALT3D: Generating Realistic Training Data from Time-Lapse Imagery for Reconstructing Dynamic Objects under Occlusion
Apr 01, 2024



Current methods for 2D and 3D object understanding struggle with severe occlusions in busy urban environments, partly due to the lack of large-scale labeled ground-truth annotations for learning occlusion. In this work, we introduce a novel framework for automatically generating a large, realistic dataset of dynamic objects under occlusions using freely available time-lapse imagery. By leveraging off-the-shelf 2D (bounding box, segmentation, keypoint) and 3D (pose, shape) predictions as pseudo-groundtruth, unoccluded 3D objects are identified automatically and composited into the background in a clip-art style, ensuring realistic appearances and physically accurate occlusion configurations. The resulting clip-art image with pseudo-groundtruth enables efficient training of object reconstruction methods that are robust to occlusions. Our method demonstrates significant improvements in both 2D and 3D reconstruction, particularly in scenarios with heavily occluded objects like vehicles and people in urban scenes.
Learned Two-Plane Perspective Prior based Image Resampling for Efficient Object Detection
Mar 25, 2023Real-time efficient perception is critical for autonomous navigation and city scale sensing. Orthogonal to architectural improvements, streaming perception approaches have exploited adaptive sampling improving real-time detection performance. In this work, we propose a learnable geometry-guided prior that incorporates rough geometry of the 3D scene (a ground plane and a plane above) to resample images for efficient object detection. This significantly improves small and far-away object detection performance while also being more efficient both in terms of latency and memory. For autonomous navigation, using the same detector and scale, our approach improves detection rate by +4.1 $AP_{S}$ or +39% and in real-time performance by +5.3 $sAP_{S}$ or +63% for small objects over state-of-the-art (SOTA). For fixed traffic cameras, our approach detects small objects at image scales other methods cannot. At the same scale, our approach improves detection of small objects by 195% (+12.5 $AP_{S}$) over naive-downsampling and 63% (+4.2 $AP_{S}$) over SOTA.
Dynamic Body VSLAM with Semantic Constraints
Apr 27, 2015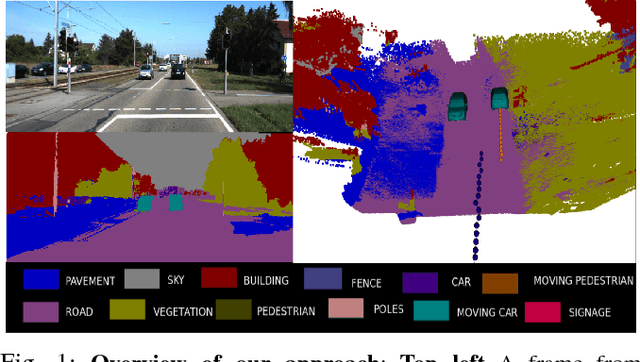

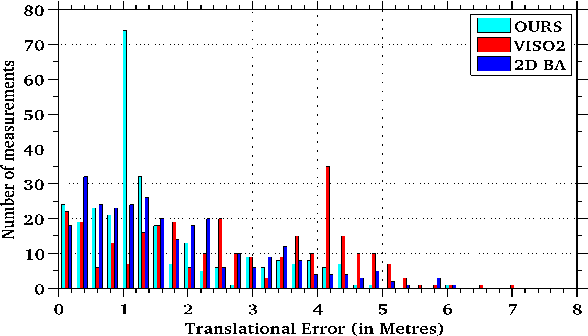
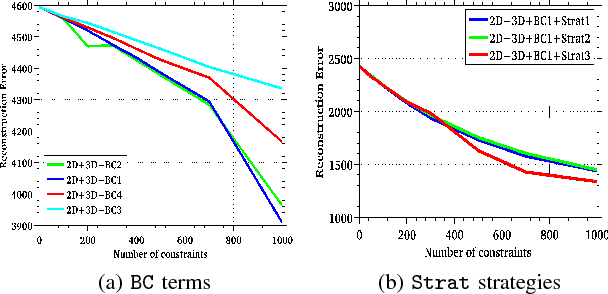
Image based reconstruction of urban environments is a challenging problem that deals with optimization of large number of variables, and has several sources of errors like the presence of dynamic objects. Since most large scale approaches make the assumption of observing static scenes, dynamic objects are relegated to the noise modeling section of such systems. This is an approach of convenience since the RANSAC based framework used to compute most multiview geometric quantities for static scenes naturally confine dynamic objects to the class of outlier measurements. However, reconstructing dynamic objects along with the static environment helps us get a complete picture of an urban environment. Such understanding can then be used for important robotic tasks like path planning for autonomous navigation, obstacle tracking and avoidance, and other areas. In this paper, we propose a system for robust SLAM that works in both static and dynamic environments. To overcome the challenge of dynamic objects in the scene, we propose a new model to incorporate semantic constraints into the reconstruction algorithm. While some of these constraints are based on multi-layered dense CRFs trained over appearance as well as motion cues, other proposed constraints can be expressed as additional terms in the bundle adjustment optimization process that does iterative refinement of 3D structure and camera / object motion trajectories. We show results on the challenging KITTI urban dataset for accuracy of motion segmentation and reconstruction of the trajectory and shape of moving objects relative to ground truth. We are able to show average relative error reduction by a significant amount for moving object trajectory reconstruction relative to state-of-the-art methods like VISO 2, as well as standard bundle adjustment algorithms.
Semantic Motion Segmentation Using Dense CRF Formulation
Apr 24, 2015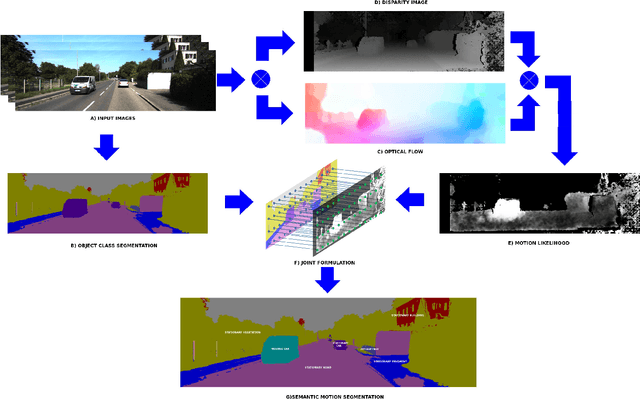
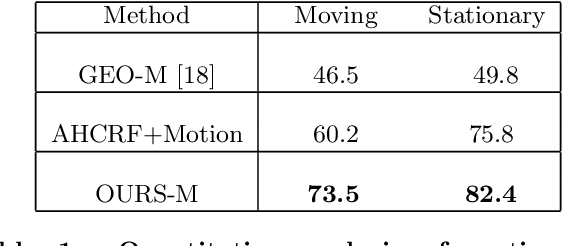
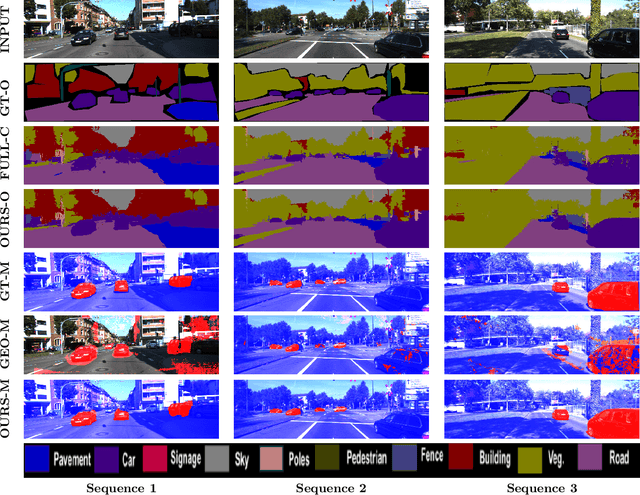

While the literature has been fairly dense in the areas of scene understanding and semantic labeling there have been few works that make use of motion cues to embellish semantic performance and vice versa. In this paper, we address the problem of semantic motion segmentation, and show how semantic and motion priors augments performance. We pro- pose an algorithm that jointly infers the semantic class and motion labels of an object. Integrating semantic, geometric and optical ow based constraints into a dense CRF-model we infer both the object class as well as motion class, for each pixel. We found improvement in performance using a fully connected CRF as compared to a standard clique-based CRFs. For inference, we use a Mean Field approximation based algorithm. Our method outperforms recently pro- posed motion detection algorithms and also improves the semantic labeling compared to the state-of-the-art Automatic Labeling Environment algorithm on the challenging KITTI dataset especially for object classes such as pedestrians and cars that are critical to an outdoor robotic navigation scenario.