 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Motion Segmentation Using Dense CRF Formulation
Paper and Code
Apr 24, 2015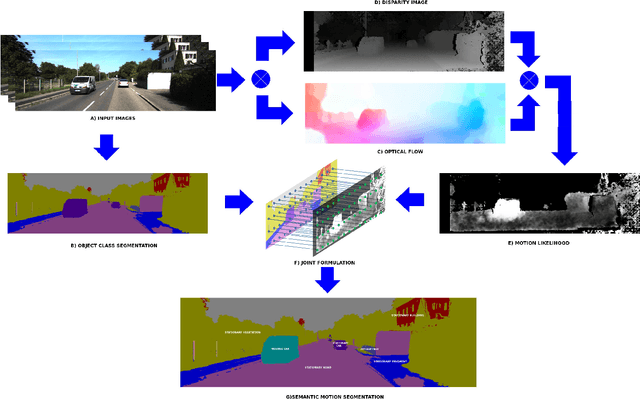
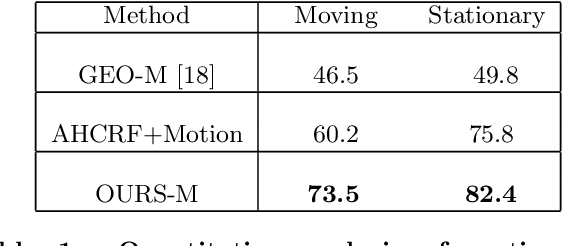
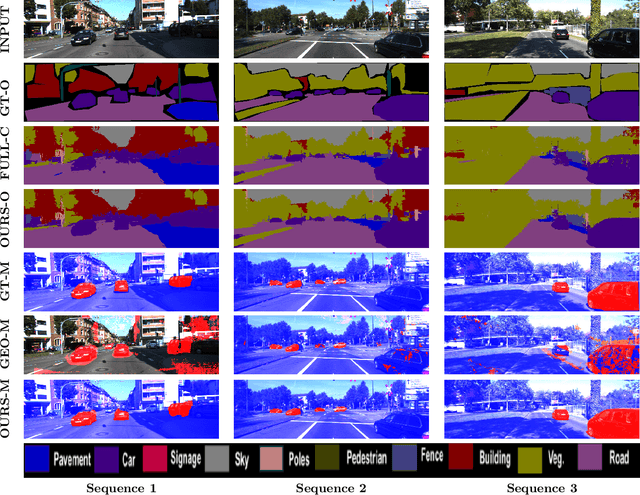

While the literature has been fairly dense in the areas of scene understanding and semantic labeling there have been few works that make use of motion cues to embellish semantic performance and vice versa. In this paper, we address the problem of semantic motion segmentation, and show how semantic and motion priors augments performance. We pro- pose an algorithm that jointly infers the semantic class and motion labels of an object. Integrating semantic, geometric and optical ow based constraints into a dense CRF-model we infer both the object class as well as motion class, for each pixel. We found improvement in performance using a fully connected CRF as compared to a standard clique-based CRFs. For inference, we use a Mean Field approximation based algorithm. Our method outperforms recently pro- posed motion detection algorithms and also improves the semantic labeling compared to the state-of-the-art Automatic Labeling Environment algorithm on the challenging KITTI dataset especially for object classes such as pedestrians and cars that are critical to an outdoor robotic navigation scenario.